
XML的主要用途
- --数据存储和数据描述
- --是一个优良的配置文件
- --相当于一个小型数据库
- --XML不依赖于任何一种编程语言,是独立的W3C提供的规范,所以可以完成多种语言之间的数据交换(重点)
XML的语法严格,并且完全区分大小写
- XML(
eXtensible Markup Language)-描述事物本身 .xml

XSL (eXtensible Stylesheet Language)-修饰XML XSL文件也有单独的文件,文件后缀 .xsl
通过以下陈程序引入xsl文件
<?xml-stylesheet type="text/xsl" href="student.xsl"?>
DTD (Docment Type Definition)-约定xml的标签 在XML文件中只能编写那些标签,标签中只能编写那些属性 DTD有单独的文件,文件后缀 .dtd
DTD实例

Schema-约定xml标签和类型,比DTD编写更加方便,(约束XML文件) schema有单独的文件,文件后缀 .xsd/.xml
实例是:
<?xml version="1.0" encoding="gb2312"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="丛书"> <xs:complexType> <xs:sequence> <xs:element name="书"> <xs:element name="名" minoccurs="1"></xs:element> <xs:element name="人"></xs:element> <xs:element name="价"> <xs:attribute name="unit"> <xs:enumeration value="RMB"/> <xs:enumeration value="美元"/> <xs:enumeration value="日元"/> </xs:attribute> </xs:element> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
可以扩展的原因:DTD可以修改
对比HTML
HTML(Hyper Text Markup language)
*超文本传输标记语句(程序员不能自己扩展)
*HTML主要用途:做页面展示,不会做数据处理
*语法松散,不区分大小写
CSS
DTD(Doucment Type Defined)约束HTML能有那些标签,标签能有那些属性
schema (DTD的升级版,语法更新一些,和DTD达到同等效果)
不可扩展原因:DTD不可扩展
关于XML文件的解析?
*无论是哪一种编程语言,对XML文件的解析都包括两种方式:
*DOM解析
*SAX解析(org.xml.sax.helps DefaultHandler)
DOM解析
*原理
在开始解析XML文件的时候,将整个XMl文件全部加载到内存中
在内存中编程语言将XML文件映射成一颗DOM树,这颗树就是一个
对象,然后我们对这棵树上的任意节点进行增删改查操作,由于
这棵树全部都在内存上,解析过去的节点可以再次解析,比较灵活。
*优点
灵活,解析过去的节点,可以再次解析
*缺点
如果XML文件比较大,可能会导致内存溢出,即使不导致内存溢出,
也会耗费大量内存,内存少了项目的运行效率自然就降低了。
*什么情况下选择dom解析方式
如果很灵活的操作每一个元素,选用dom解析,但是注意文件需要小一些
SAX解析
*原理
SAX解析是基于事件驱动型的解析方式,他的解析不需要将整个XML文件全部
转载到内存中,解析的时候是有顺序的,在XML文件中从上往下依次解析,遇
到开始标签,表示发生了一个特定的事件,此时执行一段特定的程序,遇到结束
标签表示又发生一个特定事件,此时执行一段特定的程序完成解析。
*优点
不需要转载XML文件,所以不会占用大量内存, 适合大文件
*缺点
解析过去的节点不能重复解析,除非重头开始
*什么情况下选择SAX解析方式
大文件适合使用SAX解析
作为程序员如何解析XML文件,解析XMl文件的开源项目都包括那些?
java解析XML相关的开源项目
*DOM4j(Dom for Java)
*JDOM
.....
JDK自带一套,是实现W3C规范的
*org.w3c.com.*; 基于DOM解析
*org.xml.sax.*; 基于SAX解析
为了提高我们解析XMl文件的效率,还涉及到XPATH。(是一种标签匹配方式,类似于正则表达式,可以让我们程序快速定位XML文件中的标签)
解析XML文件涉及到:
DOM4j/JDOM/W3C+......Xpath
JDK自带的一套解析
首先在src目录下创建一个xml文件

以下为解析过程
/**
* 使用JDK自带的"Dom解析"XML文件(读)
*/
public class Text04 {
public static void main(String[] args) throws Exception {
//创建文档解析器工厂对象
DocumentBuilderFactory factory= DocumentBuilderFactory.newInstance();
//创建文档解析器对象
DocumentBuilder builder=factory.newDocumentBuilder();
//开始解析XML文件
String path=Thread.currentThread().getContextClassLoader().getResource("db-config.xml").toURI().getPath();
Document document =builder.parse(new File(path));//dom树,在内存中生成了一颗dom树
//获取根元素
Node rootNode=document.getFirstChild();
//获取根元素的名字
System.out.println(rootNode.getNodeName());
//通过根元素获取其他元素
Node driverNode=document.getElementsByTagName("driver").item(0);
String driver =driverNode.getTextContent();
System.out.println(driver);
}
}
输出结果
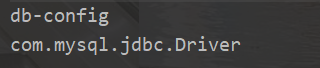
使用dom4j开源项目(基于dom解析)解析xml文件(读)
需要将dom4j开源项目的jar包作为目录导入
/**
* 使用dom4j开源项目解析XML文件(读)
*
* 读XML文件
*
* DOM4j
*
* 基于dom方式
*/
public class Text01 {
public static void main(String[] args) throws Exception {
//创建解析器对象
SAXReader reader=new SAXReader();//虽然使用了SAXReader,但是还是基于DOM的解析方式
//获取文档对象,还是dom树
String path=Thread.currentThread().getContextClassLoader().getResource("db-config.xml").toURI().getPath();
Document document= reader.read(new File(path));
//获取根元素
Element rootElement=document.getRootElement();
//System.out.println(element.getName());
//获取driver元素
Element driverElement =rootElement.element("driver");
//在获取文本
String driver=driverElement.getText();
//System.out.println(driver);
//直接获取元素的文本内容
driver=rootElement.elementText("driver");
System.out.println(driver);
System.out.println(rootElement.elementText("url"));
System.out.println(rootElement.elementText("user"));
System.out.println(rootElement.elementText("password"));
}
}
输出结果
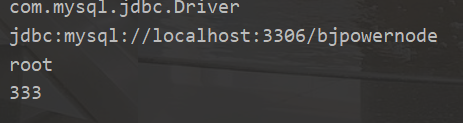
使用dom4j开源项目(基于dom解析)解析xml文件(写)
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
import java.io.File;
import java.io.FileWriter;
/**
* 使用dom4j开源项目解析XML文件(写)
*/
public class Text02 {
public static void main(String[] args) throws Exception {
//创建文档对象
Document document= DocumentHelper.createDocument();
//添加根元素
Element studentInfoElt=document.addElement("学生信息");
//给学生信息节点添加子节点学生节点
Element studentElt=studentInfoElt.addElement("学生");
//给学生节点添加id属性
studentElt.addAttribute("id","110");
//给学生节点添加名字字节点
Element nameElt=studentElt.addElement("名字");
//设置名字节点文本
nameElt.setText("张三");
//给学生节点添加性别字节点
Element sexElt=studentElt.addElement("性别");
//设置名字节点文本
sexElt.setText("男");
//开始写
OutputFormat format= OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");
String path="students.xml";
XMLWriter xmlWriter=new XMLWriter(new FileWriter(new File(path)),format);
xmlWriter.write(document);
xmlWriter.close();
}
}
最终生成的xml文件
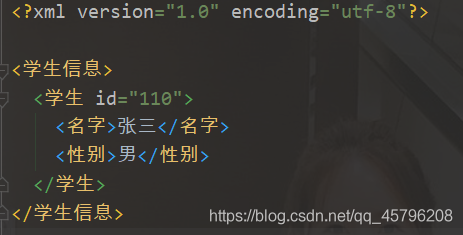
总结
本篇文章就到这里了,希望能给你带来帮助,也希望你能够多多关注自学编程网的更多内容!

- 本文固定链接: https://zxbcw.cn/post/217092/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)