
面试题1:说一下 HashMap 的实现原理?
正经回答:
众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry(包括Key-Value),其中Key 和 Value 允许为null。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。另外,HashMap数组每一个元素的初始值都是Null。

值得注意的是:HashMap不能保证映射的顺序,插入后的数据顺序也不能保证一直不变(如扩容后rehash)。
要说HashMap的原理,首先要先了解他的数据结构,
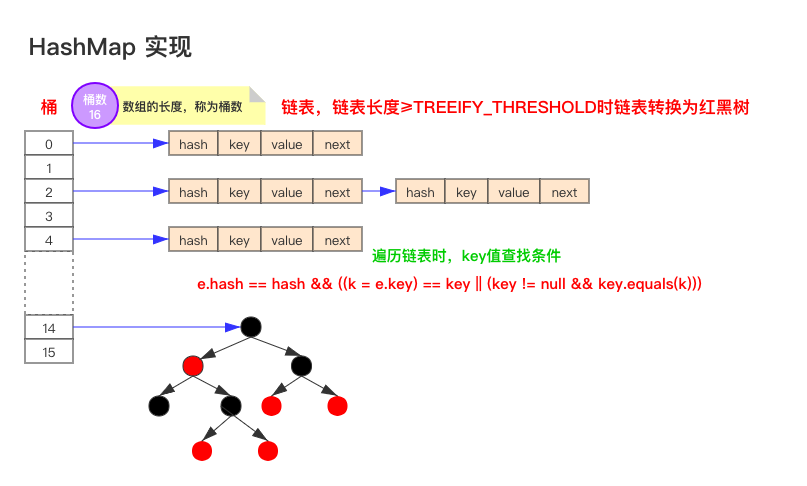
如上图为JDK1.8版本的数据结构,其实HashMap在JDK1.7及以前是一个“链表散列”的数据结构,即数组 + 链表的结合体。JDK8优化为:数组+链表+红黑树。
我们常把数组中的每一个节点称为一个桶。当向桶中添加一个键值对时,首先计算键值对中key的hash值(hash(key)),以此确定插入数组中的位置(即哪个桶),但是可能存在同一hash值的元素已经被放在数组同一位置了,这种现象称为碰撞,这时按照尾插法(jdk1.7及以前为头插法)的方式添加key-value到同一hash值的元素的最后面,链表就这样形成了。
当链表长度超过8(TREEIFY_THRESHOLD - 阈值)时,链表就自行转为红黑树。
注意:同一hash值的元素指的是key内容一样么?不是。根据hash算法的计算方式,是将key值转为一个32位的int值(近似取值),key值不同但key值相近的很可能hash值相同,如key=“a”和key=“aa”等。
通过上述回答的内容,我们明显给了面试官往深入问的多个诱饵,根据我们的回答,下一步他多可能会追问这些问题:
1、如何实现HashMap的有序? 4、put方法原理是怎么实现的? 6、扩容机制原理 → 初始容量、加载因子 → 扩容后的rehash(元素迁移) 2、插入后的数据顺序会变的原因是什么? 3、HashMap在JDK1.7-JDK1.8都做了哪些优化? 5、链表红黑树如何互相转换?阈值多少? 7、头插法改成尾插法为了解决什么问题?
而我们,当然是提前准备好如何回答好这些问题!当你的回答超过面试同学的认知范围时,主动权就到我们手里了。
深入追问: 追问1:如何实现HashMap的有序?
使用LinkedHashMap 或 TreeMap。
LinkedHashMap内部维护了一个单链表,有头尾节点,同时LinkedHashMap节点Entry内部除了继承HashMap的Node属性,还有before 和 after用于标识前置节点和后置节点。可以实现按插入的顺序或访问顺序排序。
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
//将加入的p节点添加到链表末尾
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
//LinkedHashMap的节点类
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
示例代码:
public static void main(String[] args) {
Map<String, String> linkedMap = new LinkedHashMap<String, String>();
linkedMap.put("1", "占便宜");
linkedMap.put("2", "没够儿");
linkedMap.put("3", "吃亏");
linkedMap.put("4", "难受");
for(linkedMap.Entry<String,String> item: linkedMap.entrySet()){
System.out.println(item.getKey() + ":" + item.getValue());
}
}
输出结果:
1:占便宜 2:没够儿 3:吃亏 4:难受
追问2:那TreeMap怎么实现有序的?
TreeMap是按照Key的自然顺序或者Comprator的顺序进行排序,内部是通过红黑树来实现。
TreeMap实现了SortedMap接口,它是一个key有序的Map类。要么key所属的类实现Comparable接口,或者自定义一个实现了Comparator接口的比较器,传给TreeMap用于key的比较。
TreeMap<String, String> map = new TreeMap<String, String>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
追问3:put方法原理是怎么实现的?
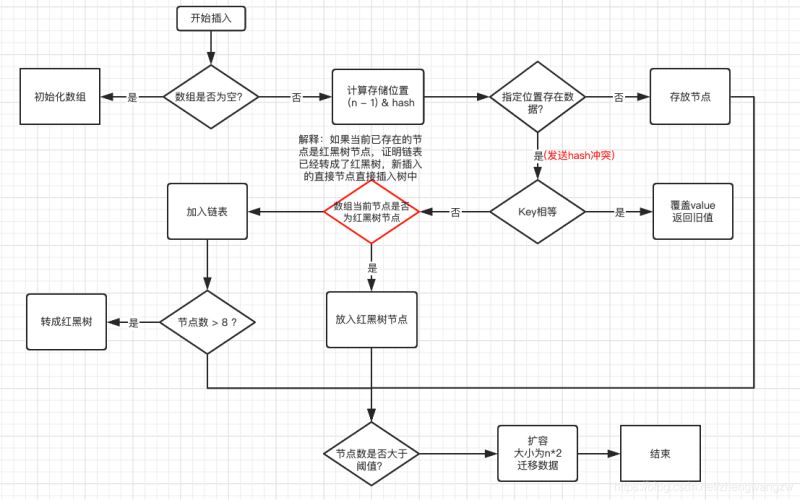
- 判断数组是否为空,为空进行初始化;
- 不为空,计算 k 的 hash 值,通过(n - 1) & hash计算应当存放在数组中的下标 index;
- 查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
- 如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;
- (如果当前节点是树型节点证明当前已经是红黑树了)如果不是树型节点,创建普通Node加入链表中;
- 判断链表长度是否大于 8并且数组长度大于64, 大于的话链表转换为红黑树;
- 插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
下面我们看看源码中的内容:
/**
* 将指定参数key和指定参数value插入map中,如果key已经存在,那就替换key对应的value
*
* @param key 指定key
* @param value 指定value
* @return 如果value被替换,则返回旧的value,否则返回null。当然,可能key对应的value就是null。
*/
public V put(K key, V value) {
//putVal方法的实现就在下面
return putVal(hash(key), key, value, false, true);
}
从源码中可以看到,put(K key, V value)可以分为三个步骤:
- 通过hash(Object key)方法计算key的哈希值。
- 通过putVal(hash(key), key, value, false, true)方法实现功能。
- 返回putVal方法返回的结果。
那么看看putVal方法的源码是如何实现的?
/**
* Map.put和其他相关方法的实现需要的方法
*
* @param hash 指定参数key的哈希值
* @param key 指定参数key
* @param value 指定参数value
* @param onlyIfAbsent 如果为true,即使指定参数key在map中已经存在,也不会替换value
* @param evict 如果为false,数组table在创建模式中
* @return 如果value被替换,则返回旧的value,否则返回null。当然,可能key对应的value就是null。
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果哈希表为空,调用resize()创建一个哈希表,并用变量n记录哈希表长度
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果指定参数hash在表中没有对应的桶,即为没有碰撞
if ((p = tab[i = (n - 1) & hash]) == null)
//直接将键值对插入到map中即可
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果碰撞了,且桶中的第一个节点就匹配了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//将桶中的第一个节点记录起来
e = p;
//如果桶中的第一个节点没有匹配上,且桶内为红黑树结构,则调用红黑树对应的方法插入键值对
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//不是红黑树结构,那么就肯定是链式结构
else {
//遍历链式结构
for (int binCount = 0; ; ++binCount) {
//如果到了链表尾部
if ((e = p.next) == null) {
//在链表尾部插入键值对
p.next = newNode(hash, key, value, null);
//如果链的长度大于TREEIFY_THRESHOLD这个临界值,则把链变为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
//跳出循环
break;
}
//如果找到了重复的key,判断链表中结点的key值与插入的元素的key值是否相等,如果相等,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
//如果key映射的节点不为null
if (e != null) { // existing mapping for key
//记录节点的vlaue
V oldValue = e.value;
//如果onlyIfAbsent为false,或者oldValue为null
if (!onlyIfAbsent || oldValue == null)
//替换value
e.value = value;
//访问后回调
afterNodeAccess(e);
//返回节点的旧值
return oldValue;
}
}
//结构型修改次数+1
++modCount;
//判断是否需要扩容
if (++size > threshold)
resize();
//插入后回调
afterNodeInsertion(evict);
return null;
}
追问4:HashMap扩容机制原理
capacity 即容量,默认16。
loadFactor 加载因子,默认是0.75
threshold 阈值。阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容。
- 一般情况下,当元素数量超过阈值时便会触发扩容(调
用resize()方法)。 - 每次扩容的容量都是之前容量的2倍。
- 扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
这里我们以JDK1.8的扩容为例:
HashMap的容量变化通常存在以下几种情况:
1.空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
2.有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让 阈值 = 容量 x 加载因子 。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
3.如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,加载因子0.75不变)
此外还有几个点需要注意:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;可见
首次扩容可能会调用两次resize()方法。 - 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
扩容时,要扩大空间,为了使hash散列均匀分布,原有部分元素的位置会发生移位。
JDK7的元素迁移
JDK7中,HashMap的内部数据保存的都是链表。因此逻辑相对简单:在准备好新的数组后,map会遍历数组的每个“桶”,然后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
- 这里有几个注意点:
是否要重新计算hash值的条件这里不深入讨论,读者可自行查阅源码。因为是头插法,因此新旧链表的元素位置会发生转置现象。
元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转)。
JDK1.8的元素迁移
JDK1.8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因如下图:
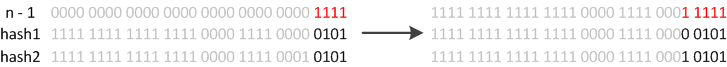
数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:

因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
JDK8的HashMap还有以下细节需要注意:
- JDK8在迁移元素时是正序的,不会出现链表转置的发生。
- 如果某个桶内的元素超过8个,则会将链表转化成红黑树,加快数据查询效率。
追问5:HashMap在JDK1.8都做了哪些优化?
| 不同点 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 存储结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 初始化方式 | 单独函数:inflateTable() | 直接集成到了扩容函数resize()中 |
| hash值计算方式 | 扰动处理 = 9次扰动 = 4次位运算 + 5次异或运算 | 扰动处理 = 2次扰动 = 1次位运算 + 1次异或运算 |
| 存放数据的规则 | 无冲突时,存放数组;冲突时,存放链表 | 无冲突时,存放数组;冲突 & 链表长度 < 8:存放单链表;冲突 & 链表长度 > 8:树化并存放红黑树 |
| 插入数据方式 | 头插法(先讲原位置的数据移到后1位,再插入数据到该位置) | 尾插法(直接插入到链表尾部/红黑树) |
| 扩容后存储位置的计算方式 | 全部按照原来方法进行计算(即hashCode ->> 扰动函数 ->> (h&length-1)) | 按照扩容后的规律计算(即扩容后的位置=原位置 or 原位置 + 旧容量) |
1.数组+链表改成了数组+链表或红黑树;
防止发生hash冲突,链表长度过长,将时间复杂度由O(n)降为O(logn);
2.链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,新节点插入到链表头部,原始节点后移;而JDK1.8会遍历链表,将元素放置到链表的最后;
因为1.7头插法扩容时,头插法可能会导致链表发生反转,多线程环境下会产生环(死循环);
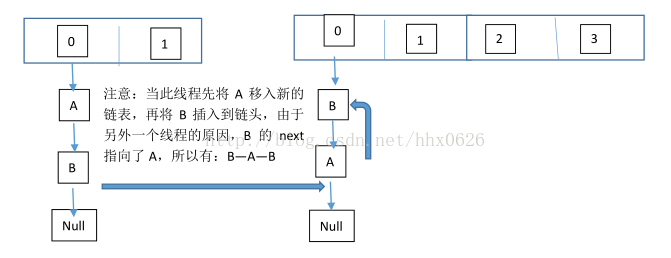
这个过程为,先将A复制到新的hash表中,然后接着复制B到链头(A的前边:B.next=A),本来B.next=null,到此也就结束了(跟线程二一样的过程),但是,由于线程二扩容的原因,将B.next=A,所以,这里继续复制A,让A.next=B,由此,环形链表出现:B.next=A; A.next=B
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B。
3.扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
4.在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
追问6:链表红黑树如何互相转换?阈值多少?
- **链表转红黑树的阈值为:8
- ****红黑树转链表的阈值为:6 **
经过计算,在hash函数设计合理的情况下,发生hash碰撞8次的几率为百万分之6,从概率上讲,阈值为8足够用;至于为什么红黑树转回来链表的条件阈值是6而不是7或9?因为如果hash碰撞次数在8附近徘徊,可能会频繁发生链表和红黑树的互相转化操作,为了预防这种情况的发生。
面试题2:HashMap是线程安全的吗?
正经回答:
不是线程安全的,在多线程环境下,
- JDK1.7:会产生死循环、数据丢失、数据覆盖的问题;
- JDK1.8:中会有数据覆盖的问题。
以1.8为例,当A线程判断index位置为空后正好挂起,B线程开始往index位置写入数据时,这时A线程恢复,执行写入操作,这样A或B数据就被覆盖了。
追问1:你是如何解决这个线程不安全问题的?
在Java中有HashTable、SynchronizedMap、ConcurrentHashMap这三种是实现线程安全的Map。
- HashTable:是直接在操作方法上加synchronized关键字,锁住整个数组,粒度比较大;
- SynchronizedMap:是使用Collections集合工具的内部类,通过传入Map封装出一个SynchronizedMap对象,内部定义了一个对象锁,方法内通过对象锁实现;
- ConcurrentHashMap:使用分段锁(CAS + synchronized相结合),降低了锁粒度,大大提高并发度。
总结
本篇文章就到这里了,希望能给你带来帮助,也希望你能够多多关注自学编程网的更多内容!

- 本文固定链接: https://zxbcw.cn/post/217414/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)