
1、Redis 是单线程还是多线程?
这个问题应该已经看到过无数次了,最近 redis 6 出来之后又被翻出来了。
redis 4.0 之前,redis 是完全单线程的。
redis 4.0 时,redis 引入了多线程,但是额外的线程只是用于后台处理,例如:删除对象,核心流程还是完全单线程的。这也是为什么有些人说 4.0 是单线程的,因为他们指的是核心流程是单线程的。
这边的核心流程指的是 redis 正常处理客户端请求的流程,通常包括:接收命令、解析命令、执行命令、返回结果等。
而在最近,redis 6.0 版本又一次引入了多线程概念,与 4.0 不同的是,这次的多线程会涉及到上述的核心流程。
redis 6.0 中,多线程主要用于网络 I/O 阶段,也就是接收命令和写回结果阶段,而在执行命令阶段,还是由单线程串行执行。由于执行时还是串行,因此无需考虑并发安全问题。
值得注意的时,redis 中的多线程组不会同时存在“读”和“写”,这个多线程组只会同时“读”或者同时“写”。
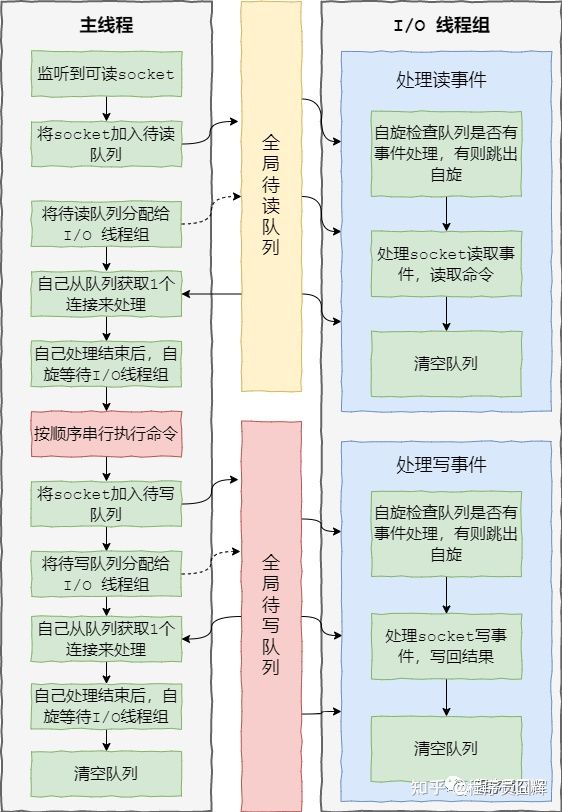
redis 6.0 加入多线程 I/O 之后,处理命令的核心流程如下:
1、当有读事件到来时,主线程将该客户端连接放到全局等待读队列
2、读取数据:1)主线程将等待读队列的客户端连接通过轮询调度算法分配给 I/O 线程处理;2)同时主线程也会自己负责处理一个客户端连接的读事件;3)当主线程处理完该连接的读事件后,会自旋等待所有 I/O 线程处理完毕
3、命令执行:主线程按照事件被加入全局等待读队列的顺序(这边保证了执行顺序是正确的),串行执行客户端命令,然后将客户端连接放到全局等待写队列
4、写回结果:跟等待读队列处理类似,主线程将等待写队列的客户端连接使用轮询调度算法分配给 I/O 线程处理,同时自己也会处理一个,当主线程处理完毕后,会自旋等待所有 I/O 线程处理完毕,最后清空队列。
大致流程图如下:
2、为什么 Redis 是单线程?
在 redis 6.0 之前,redis 的核心操作是单线程的。
因为 redis 是完全基于内存操作的,通常情况下CPU不会是redis的瓶颈,redis 的瓶颈最有可能是机器内存的大小或者网络带宽。
既然CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了,因为如果使用多线程的话会更复杂,同时需要引入上下文切换、加锁等等,会带来额外的性能消耗。
而随着近些年互联网的不断发展,大家对于缓存的性能要求也越来越高了,因此 redis 也开始在逐渐往多线程方向发展。
最近的 6.0 版本就对核心流程引入了多线程,主要用于解决 redis 在网络 I/O 上的性能瓶颈。而对于核心的命令执行阶段,目前还是单线程的。
3、Redis 为什么使用单进程、单线程也很快
主要有以下几点:
1、基于内存的操作
2、使用了 I/O 多路复用模型,select、epoll 等,基于 reactor 模式开发了自己的网络事件处理器
3、单线程可以避免不必要的上下文切换和竞争条件,减少了这方面的性能消耗。
4、以上这三点是 redis 性能高的主要原因,其他的还有一些小优化,例如:对数据结构进行了优化,简单动态字符串、压缩列表等。
4、Redis 在项目中的使用场景
缓存(核心)、分布式锁(set + lua 脚本)、排行榜(zset)、计数(incrby)、消息队列(stream)、地理位置(geo)、访客统计(hyperloglog)等。
5、Redis 常见的数据结构
基础的5种:
- String:字符串,最基础的数据类型。
- List:列表。
- Hash:哈希对象。
- Set:集合。
- Sorted Set:有序集合,Set 的基础上加了个分值。
高级的4种:
- HyperLogLog:通常用于基数统计。使用少量固定大小的内存,来统计集合中唯一元素的数量。统计结果不是精确值,而是一个带有0.81%标准差(standard error)的近似值。所以,HyperLogLog适用于一些对于统计结果精确度要求不是特别高的场景,例如网站的UV统计。
- Geo:redis 3.2 版本的新特性。可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作:获取2个位置的距离、根据给定地理位置坐标获取指定范围内的地理位置集合。
- Bitmap:位图。
- Stream:主要用于消息队列,类似于 kafka,可以认为是 pub/sub 的改进版。提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
6、Redis 的字符串(SDS)和C语言的字符串区别

7、Sorted Set底层数据结构
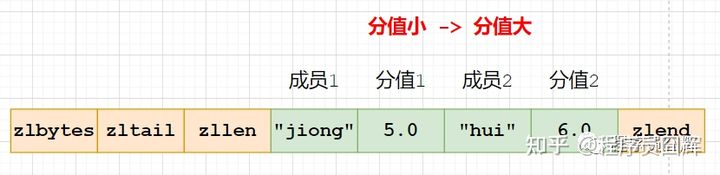
Sorted Set(有序集合)当前有两种编码:ziplist、skiplist
ziplist:使用压缩列表实现,当保存的元素长度都小于64字节,同时数量小于128时,使用该编码方式,否则会使用 skiplist。这两个参数可以通过 zset-max-ziplist-entries、zset-max-ziplist-value 来自定义修改。
skiplist:zset实现,一个zset同时包含一个字典(dict)和一个跳跃表(zskiplist)
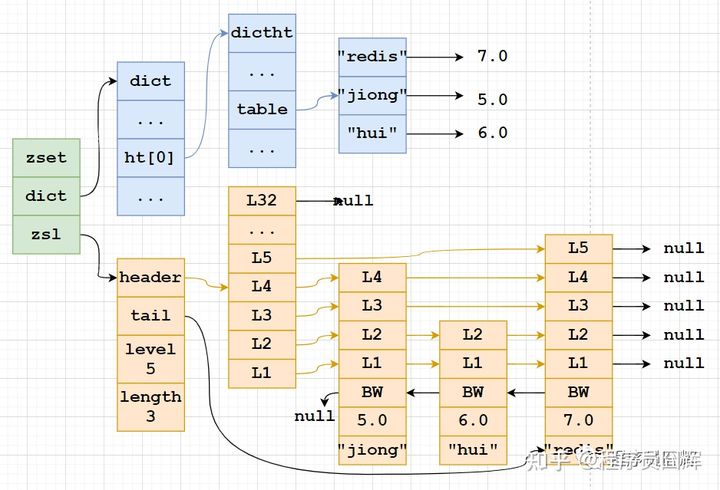
8、Sorted Set 为什么同时使用字典和跳跃表?
主要是为了提升性能。
单独使用字典:在执行范围型操作,比如 zrank、zrange,字典需要进行排序,至少需要 O(NlogN) 的时间复杂度及额外 O(N) 的内存空间。
单独使用跳跃表:根据成员查找分值操作的复杂度从 O(1) 上升为 O(logN)。
9、Sorted Set 为什么使用跳跃表,而不是红黑树?
主要有以下几个原因:
1)跳表的性能和红黑树差不多。
2)跳表更容易实现和调试。
网上有同学说是因为作者不会红黑树,我觉得挺有可能的。

10、Hash 对象底层结构
Hash 对象当前有两种编码:ziplist、hashtable
ziplist:使用压缩列表实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的节点推入到压缩列表的表尾,然后再将保存了值的节点推入到压缩列表表尾。
因此:1)保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;2)先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加的会被放在表尾方向。

hashtable:使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值来保存,跟 java 中的 HashMap 类似。
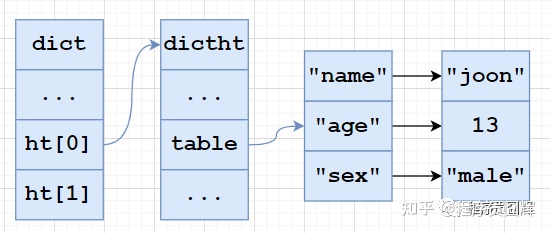
11、Hash 对象的扩容流程
hash 对象在扩容时使用了一种叫“渐进式 rehash”的方式,步骤如下:
1)计算新表 size、掩码,为新表 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
2)将 rehash 索引计数器变量 rehashidx 的值设置为0,表示 rehash 正式开始。
3)在 rehash 进行期间,每次对字典执行添加、删除、?苏摇⒏?虏僮魇保?绦虺?酥葱兄付ǖ牟僮饕酝猓?够岽シ⒍钔獾 rehash 操作,在源码中的 _dictRehashStep 方法。
_dictRehashStep:从名字也可以看出来,大意是 rehash 一步,也就是 rehash 一个索引位置。
该方法会从 ht[0] 表的 rehashidx 索引位置上开始向后查找,找到第一个不为空的索引位置,将该索引位置的所有节点 rehash 到 ht[1],当本次 rehash 工作完成之后,将 ht[0] 索引位置为 rehashidx 的节点清空,同时将 rehashidx 属性的值加一。
4)将 rehash 分摊到每个操作上确实是非常妙的方式,但是万一此时服务器比较空闲,一直没有什么操作,难道 redis 要一直持有两个哈希表吗?
答案当然不是的。我们知道,redis 除了文件事件外,还有时间事件,redis 会定期触发时间事件,这些时间事件用于执行一些后台操作,其中就包含 rehash 操作:当 redis 发现有字典正在进行 rehash 操作时,会花费1毫秒的时间,一起帮忙进行 rehash。
5)随着操作的不断执行,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash 至 ht[1],此时 rehash 流程完成,会执行最后的清理工作:释放 ht[0] 的空间、将 ht[0] 指向 ht[1]、重置 ht[1]、重置 rehashidx 的值为 -1。
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注自学编程网的更多内容!

- 本文固定链接: https://zxbcw.cn/post/217503/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)