
拆分实现流程
请看下面这张图
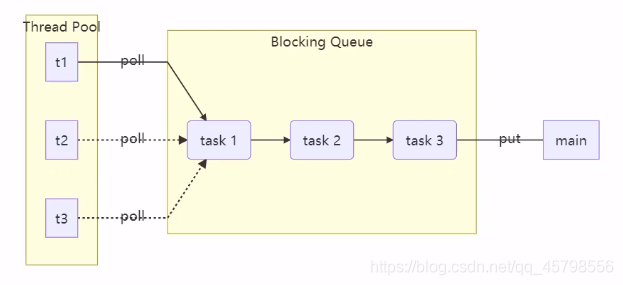
首先我们得对线程池进行一个功能拆分
- Thread Pool 就是我们的线程池,t1,t2,t3代表三个线程
- Blocking Queue代表阻塞队列
- main代表main方法的线程
- task1,task2,task3代表要执行的每个任务
现在我们梳理一下执行的流程,注意这里是简略版的,文章后面我会给出详细版的
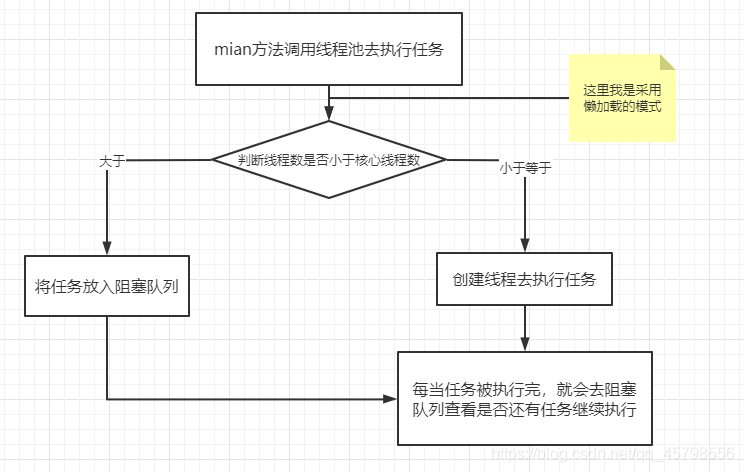
所以此时,我们发现了需要创建几个类,或者说几个角色,分别是
- 线程池
- 工作线程
- 阻塞队列
- 拒绝策略(干嘛的?就是当线程数已经满了,并且阻塞队列也满了,还有任务想进入阻塞队列的时候,就可以拒绝这个任务)
实现方式
1.拒绝策略
/**
* 拒绝策略
*/
@FunctionalInterface
interface RejectPolicy<T>{
//queue就是我们自己实现的阻塞队列,task是任务
void reject(BlockingQueue<T> queue,T task);
}
2.阻塞队列
我们需要实现四个方法,获取和添加,超时获取和超时添加,至于方法实现的细节,我都备注了大量的注释进行解释。
/**
* 阻塞队列
*/
class BlockingQueue<T>{
//阻塞队列
private Deque<T> queue = new ArrayDeque<>();
//锁
private ReentrantLock lock = new ReentrantLock();
//生产者条件变量
private Condition fullWaitSet = lock.newCondition();
//消费者条件变量
private Condition emptyWaitSet = lock.newCondition();
//容量
private int capacity;
public BlockingQueue(int capacity){
this.capacity = capacity;
}
//带有超时阻塞获取
public T poll(long timeout, TimeUnit timeUnit){
lock.lock();
try {
//将timeout统一转换为纳秒
long nanos = timeUnit.toNanos(timeout);
while(queue.isEmpty()){
try {
if(nanos <= 0){
//小于0,说明上次没有获取到,代表已经超时了
return null;
}
//返回值是剩余的时间
nanos = emptyWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
//通知生产者
fullWaitSet.signal();
return t;
}finally {
lock.unlock();
}
}
//阻塞获取
public T take(){
lock.lock();
try{
while(queue.isEmpty()){ //如果任务队列为空,代表线程池没有可以执行的内容
try {
/*
也就说此时进来的线程是执行不了任务的,所以此时emptyWaitSet消费者要进行阻塞状态
等待下一次唤醒,然后继续判断队列是否为空
*/
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/*
代码执行到这里。说明任务队列不为空,线程池就从任务队列拿出一个任务出来执行
也就是说把阻塞队列的一个任务出队
*/
T t = queue.removeFirst();
/*
然后唤醒之前存放在生成者Condition休息室,因为由于之前阻塞队列已满,fullWaitSet才会进入阻塞状态
所以当阻塞队列删除了任务,就要唤醒之前进入阻塞状态的fullWaitSet
*/
fullWaitSet.signal();
//返回任务
return t;
}finally {
lock.unlock();
}
}
//阻塞添加
public void put(T task){
lock.lock();
try {
while(queue.size() == capacity){ //任务队列满了
try {
System.out.println("等待加入任务队列"+task);
/*
也就说此时进来的任务是进不了阻塞队列的,已经满了,所以此时生产者Condition要进入阻塞状态
等待下一次唤醒,然后继续判断队列是否为空
*/
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//任务队列还未满
System.out.println("加入任务队列"+task);
//把任务加入阻塞队列
queue.addLast(task);
/*
然后唤醒之前存放在消费者Condition休息室,因为由于之前阻塞队列为空,emptyWaitSet才会进入阻塞状态
所以当阻塞队列加入了任务,就要唤醒之前进入阻塞状态的emptyWaitSet
*/
emptyWaitSet.signal();
}finally {
lock.unlock();
}
}
//带超时阻塞时间添加
public boolean offer(T task,long timeout,TimeUnit timeUnit){
lock.lock();
try {
long nanos = timeUnit.toNanos(timeout);
while(queue.size() == capacity){
try {
if(nanos < 0){
return false;
}
System.out.println("等待加入任务队列"+task);
//不会一直阻塞,超时就会继续向下执行
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("加入任务队列"+task);
queue.addLast(task);
emptyWaitSet.signal();
return true;
}finally {
lock.unlock();
}
}
//获取任务数量
public int size(){
lock.lock();
try{
return queue.size();
}finally {
lock.unlock();
}
}
//尝试添加任务,如果阻塞队列已经满了,就使用拒绝策略
public void tryPut(RejectPolicy<T> rejectPolicy, T task){
lock.lock();
try {
//判断队列是否已满
if(queue.size() == capacity){
rejectPolicy.reject(this,task);
}else{ //有空闲
System.out.println("加入任务队列"+task);
queue.addLast(task);
emptyWaitSet.signal();
}
}finally {
lock.unlock();
}
}
}
3.线程池和工作线程
我把工作线程当成线程池的内部类去实现。方便调用变量。
/**
* 线程池
*/
class ThreadPool{
//阻塞队列
private BlockingQueue<Runnable> taskQueue;
//线程集合
private HashSet<Worker> workers = new HashSet<>();
//核心线程数
private int coreSize;
//获取任务的超时时间
private long timeout;
private TimeUnit timeUnit;
private RejectPolicy<Runnable> rejectPolicy;
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapacity,RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapacity);
this.rejectPolicy = rejectPolicy;
}
//执行任务
public void execute(Runnable task){
synchronized (workers){
if(workers.size() <= coreSize){ //当前的线程数小于核心线程数
Worker worker = new Worker(task);
workers.add(worker);
//让线程开始工作,执行它的run方法
worker.start();
}else{
// 1) 死等
// 2) 带超时等待
// 3) 让调用者放弃任务执行
// 4) 让调用者抛出异常
// 5) 让调用者自己执行任务
taskQueue.tryPut(rejectPolicy,task);
}
}
}
/**
* 工作线程,也就是线程池里面的线程
*/
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task){
this.task = task;
}
@Override
public void run() {
//执行任务
// 1) 当 task 不为空,执行任务
// 2) 当 task 执行完毕,再接着从任务队列获取任务并执行
while (task != null || (task = taskQueue.poll(timeout, timeUnit)) != null) {
try {
System.out.println("正在执行的任务" + task);
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
//代表这个任务已经执行完了
task = null;
}
}
synchronized (workers) {
System.out.println("worker 被移除" + this);
workers.remove(this);
}
}
}
}
策略模式
细心的小伙伴已经发现,我在拒绝策略这里使用了23种设计模式的策略模式,因为我没有将拒绝的方式写死,而是交给了调用者去实现。
对比JDK的线程池
下面是JDK自带的线程池
经典的七大核心参数
- corePoolSize:核心线程数
- queueCapacity:任务队列容量(阻塞队列)
- maxPoolSize:最大线程数
- keepAliveTime:线程空闲时间
- TimeUnit unit:超时时间单位
- ThreadFactory threadFactory:线程工程
- rejectedExecutionHandler:任务拒绝处理器
实际上我们自己实现的也大同小异,只不过JDK官方的更为复杂。
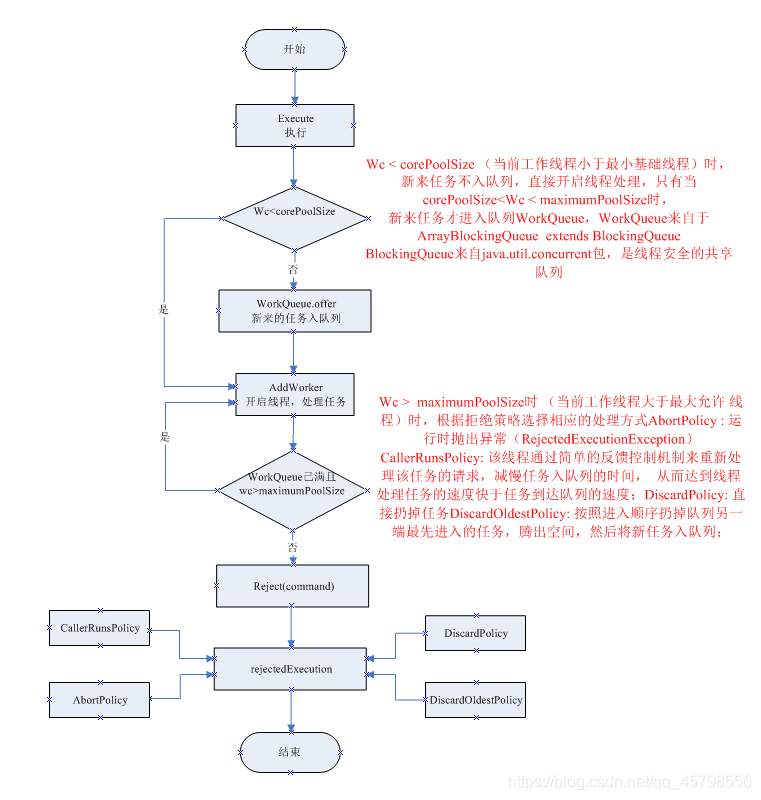
JDK线程执行的流程图
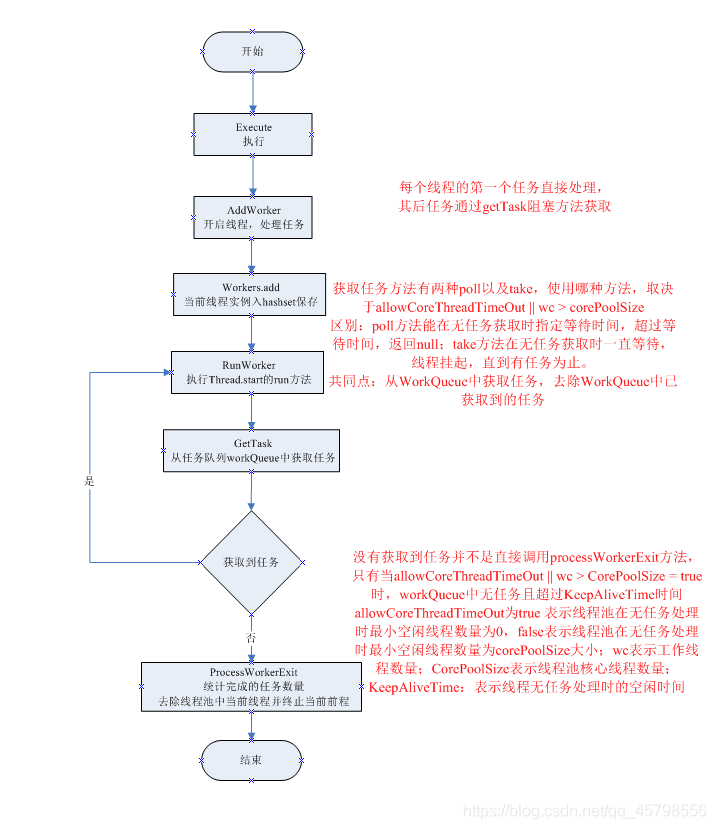
线程池的状态转化
线程我们知道在操作系统层面有5种状态
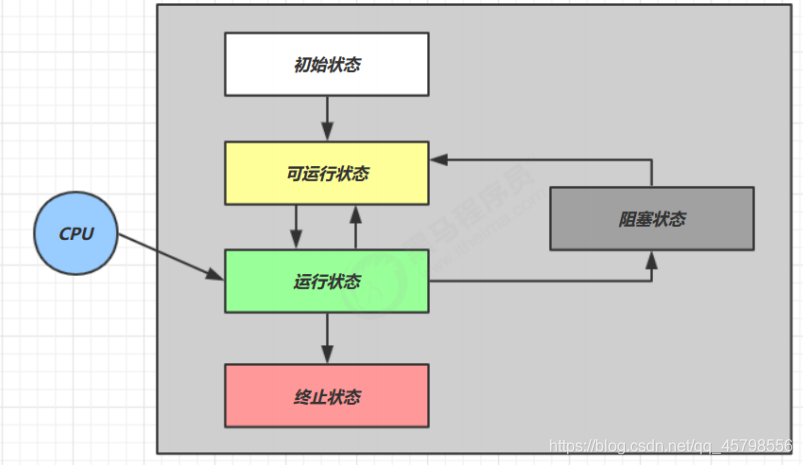
- 初始状态:仅是在语言层面创建了线程对象,还未与操作系统线程关联
- 可运行状态(就绪状态):指该线程已经被创建(与操作系统线程关联),可以由 CPU 调度执行
- 运行状态:指获取了 CPU 时间片运行中的状态,当 CPU 时间片用完,会从【运行状态】转换至【可运行状态】,会导致线程的上下文切换
- 阻塞状态
- 如果调用了阻塞 API,如 BIO 读写文件,这时该线程实际不会用到 CPU,会导致线程上下文切换,进入【阻塞状态】
- 等 BIO 操作完毕,会由操作系统唤醒阻塞的线程,转换至【可运行状态】
- 与【可运行状态】的区别是,对【阻塞状态】的线程来说只要它们一直不唤醒,调度器就一直不会考虑调度它们
- 终止状态:表示线程已经执行完毕,生命周期已经结束,不会再转换为其它状态
线程在Java API层面有6种状态
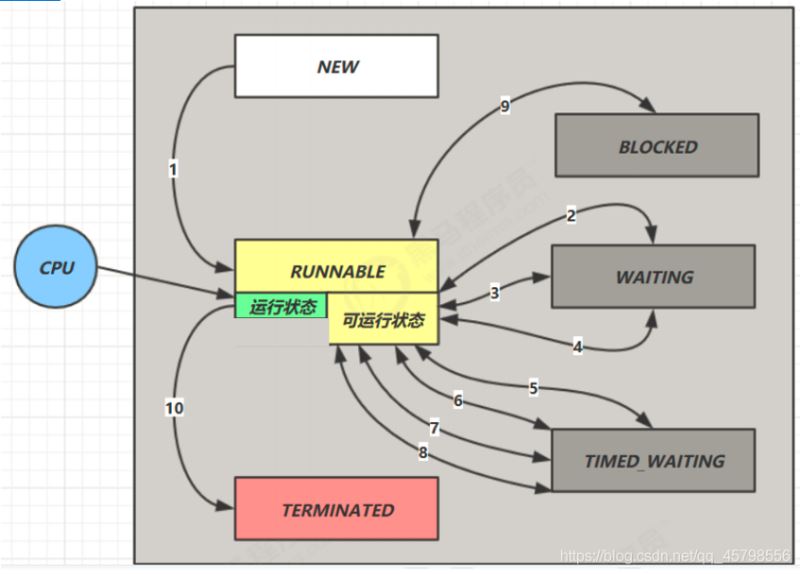
- NEW 线程刚被创建,但是还没有调用 start() 方法
- RUNNABLE 当调用了 start() 方法之后,注意,Java API 层面的
- RUNNABLE 状态涵盖了 操作系统 层面的【可运行状态】、【运行状态】
- BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分
- TERMINATED 当线程代码运行结束
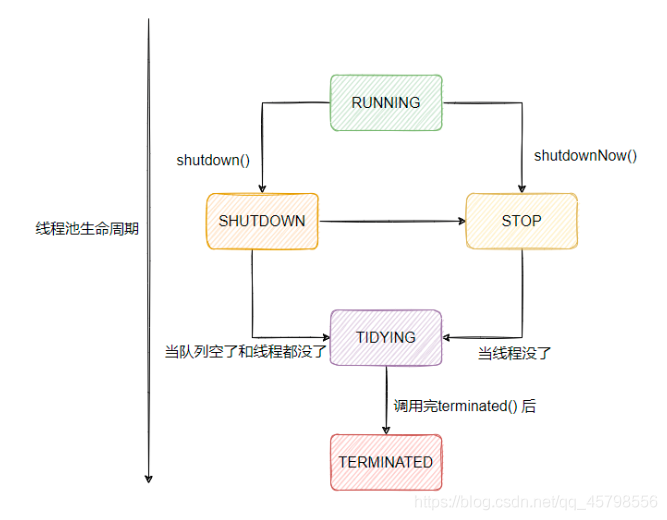
线程池有5种状态
- RUNNING:能接受新任务,并处理阻塞队列中的任务
- SHUTDOWN:不接受新任务,但是可以处理阻塞队列中的任务
- STOP:不接受新任务,并且不处理阻塞队列中的任务,并且还打断正在运行任务的线程,就是直接不干了!
- TIDYING:所有任务都终止,并且工作线程也为0,处于关闭之前的状态
- TERMINATED:已关闭。
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注自学编程网的更多内容!

- 本文固定链接: https://zxbcw.cn/post/217518/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)