
Sharding-JDBC中的分片策略有两个维度,分别是:
- 数据源分片策略(DatabaseShardingStrategy)
- 表分片策略(TableShardingStrategy)
其中,数据源分片策略表示:数据路由到的物理目标数据源,表分片策略表示数据被路由到的目标表。
特别的,表分片策略是依赖于数据源分片策略的,也就是说要先分库再分表,当然也可以只分表。
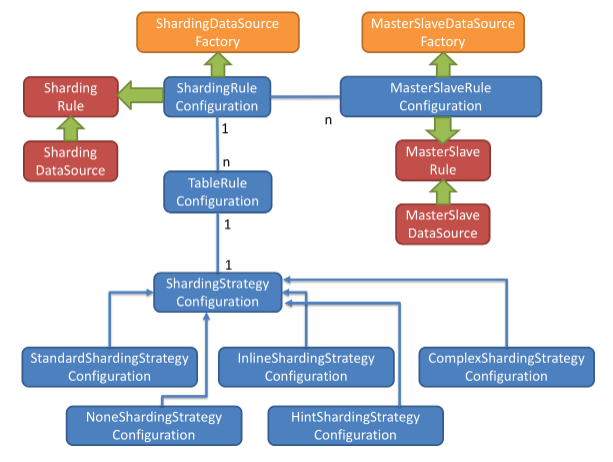
Sharding-JDBC的数据分片策略
Sharding-JDBC的分片策略包含了分片键和分片算法。由于分片算法与业务实现紧密相关,因此Sharding-JDBC没有提供内置的分片算法,而是通过分片策略将各种场景提炼出来,提供了高层级的抽象,通过提供接口让开发者自行实现分片算法。
以下内容引用自官方文档。官方文档
首先介绍四种分片算法。
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。
分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,
因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,
提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如:t_user_$->{u_id % 8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
不分片策略
对应NoneShardingStrategy。不分片的策略。
SQL Hint
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
实战–自定义复合分片策略
由于目的为贴近实战,因此着重讲解如何实现复杂分片策略,即实现ComplexShardingStrategy接口定制生产可用的分片策略。
AdminIdShardingAlgorithm 复合分片算法代码如下:
import com.google.common.collect.Range;
import io.shardingjdbc.core.api.algorithm.sharding.ListShardingValue;
import io.shardingjdbc.core.api.algorithm.sharding.PreciseShardingValue;
import io.shardingjdbc.core.api.algorithm.sharding.RangeShardingValue;
import io.shardingjdbc.core.api.algorithm.sharding.ShardingValue;
import io.shardingjdbc.core.api.algorithm.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.commons.lang.StringUtils;
import org.apache.log4j.Logger;
import java.util.*;
/**
*/
public class AdminIdShardingAlgorithm implements ComplexKeysShardingAlgorithm {
private Logger logger = Logger.getLogger(getClass());
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, Collection<ShardingValue> shardingValues) {
Collection<String> routTables = new HashSet<String>();
if (shardingValues != null) {
for (ShardingValue shardingValue : shardingValues) {
// eq in 条件
if (shardingValue instanceof ListShardingValue) {
ListShardingValue listShardingValue = (ListShardingValue) shardingValue;
Collection<Comparable> values = listShardingValue.getValues();
if (values != null) {
Iterator<Comparable> it = values.iterator();
while (it.hasNext()) {
Comparable value = it.next();
String routTable = getRoutTable(shardingValue.getLogicTableName(), value);
if (StringUtils.isNotBlank(routTable)) {
routTables.add(routTable);
}
}
}
// eq 条件
} else if (shardingValue instanceof PreciseShardingValue) {
PreciseShardingValue preciseShardingValue = (PreciseShardingValue) shardingValue;
Comparable value = preciseShardingValue.getValue();
String routTable = getRoutTable(shardingValue.getLogicTableName(), value);
if (StringUtils.isNotBlank(routTable)) {
routTables.add(routTable);
}
// between 条件
} else if (shardingValue instanceof RangeShardingValue) {
RangeShardingValue rangeShardingValue = (RangeShardingValue) shardingValue;
Range<Comparable> valueRange = rangeShardingValue.getValueRange();
Comparable lowerEnd = valueRange.lowerEndpoint();
Comparable upperEnd = valueRange.upperEndpoint();
Collection<String> tables = getRoutTables(shardingValue.getLogicTableName(), lowerEnd, upperEnd);
if (tables != null && tables.size() > 0) {
routTables.addAll(tables);
}
}
if (routTables != null && routTables.size() > 0) {
return routTables;
}
}
}
throw new UnsupportedOperationException();
}
private String getRoutTable(String logicTable, Comparable keyValue) {
Map<String, List<KeyShardingRange>> keyRangeMap = KeyShardingRangeConfig.getKeyRangeMap();
List<KeyShardingRange> keyShardingRanges = keyRangeMap.get(KeyShardingRangeConfig.SHARDING_ID_KEY);
if (keyValue != null && keyShardingRanges != null) {
if (keyValue instanceof Integer) {
keyValue = Long.valueOf(((Integer) keyValue).intValue());
}
for (KeyShardingRange range : keyShardingRanges) {
if (keyValue.compareTo(range.getMin()) >= 0 && keyValue.compareTo(range.getMax()) <= 0) {
return logicTable + range.getTableKey();
}
}
}
return null;
}
private Collection<String> getRoutTables(String logicTable, Comparable lowerEnd, Comparable upperEnd) {
Map<String, List<KeyShardingRange>> keyRangeMap = KeyShardingRangeConfig.getKeyRangeMap();
List<KeyShardingRange> keyShardingRanges = keyRangeMap.get(KeyShardingRangeConfig.SHARDING_CONTENT_ID_KEY);
Set<String> routTables = new HashSet<String>();
if (lowerEnd != null && upperEnd != null && keyShardingRanges != null) {
if (lowerEnd instanceof Integer) {
lowerEnd = Long.valueOf(((Integer) lowerEnd).intValue());
}
if (upperEnd instanceof Integer) {
upperEnd = Long.valueOf(((Integer) upperEnd).intValue());
}
boolean start = false;
for (KeyShardingRange range : keyShardingRanges) {
if (lowerEnd.compareTo(range.getMin()) >= 0 && lowerEnd.compareTo(range.getMax()) <= 0) {
start = true;
}
if (start) {
routTables.add(logicTable + range.getTableKey());
}
if (upperEnd.compareTo(range.getMin()) >= 0 && upperEnd.compareTo(range.getMax()) <= 0) {
break;
}
}
}
return routTables;
}
}
范围 map 如下:
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
/**
* 分片键分布配置
*/
public class KeyShardingRangeConfig {
private static Map<String, List<KeyShardingRange>> keyRangeMap = new LinkedHashMap<String, List<KeyShardingRange>>();
public static final String SHARDING_ORDER_ID_KEY = "id";
public static final String SHARDING_USER_ID_KEY = "adminId";
public static final String SHARDING_DATE_KEY = "createTime";
static {
List<KeyShardingRange> idRanges = new ArrayList<KeyShardingRange>();
idRanges.add(new KeyShardingRange(0, "_0", 0L, 4000000L));
idRanges.add(new KeyShardingRange(1, "_1", 4000001L, 8000000L));
idRanges.add(new KeyShardingRange(2, "_2", 8000001L, 12000000L));
idRanges.add(new KeyShardingRange(3, "_3", 12000001L, 16000000L));
idRanges.add(new KeyShardingRange(4, "_4", 16000001L, 2000000L));
keyRangeMap.put(SHARDING_ID_KEY, idRanges);
List<KeyShardingRange> contentIdRanges = new ArrayList<KeyShardingRange>();
contentIdRanges.add(new KeyShardingRange(0, "_0", 0L, 4000000L));
contentIdRanges.add(new KeyShardingRange(1, "_1", 4000001L, 8000000L));
contentIdRanges.add(new KeyShardingRange(2, "_2", 8000001L, 12000000L));
contentIdRanges.add(new KeyShardingRange(3, "_3", 12000001L, 16000000L));
contentIdRanges.add(new KeyShardingRange(4, "_4", 16000001L, 2000000L));
keyRangeMap.put(SHARDING_CONTENT_ID_KEY, contentIdRanges);
List<KeyShardingRange> timeRanges = new ArrayList<KeyShardingRange>();
timeRanges.add(new KeyShardingRange("_0", 20170701L, 20171231L));
timeRanges.add(new KeyShardingRange("_1", 20180101L, 20180630L));
timeRanges.add(new KeyShardingRange("_2", 20180701L, 20181231L));
timeRanges.add(new KeyShardingRange("_3", 20190101L, 20190630L));
timeRanges.add(new KeyShardingRange("_4", 20190701L, 20191231L));
keyRangeMap.put(SHARDING_DATE_KEY, timeRanges);
}
public static Map<String, List<KeyShardingRange>> getKeyRangeMap() {
return keyRangeMap;
}
}
核心逻辑解析
梳理一下逻辑,首先介绍一下该方法的入参
参数名 解释
availableTargetNames 有效的物理数据源,即配置文件中的 t_order_0,t_order_1,t_order_2,t_order_3
shardingValues 分片属性,如:{“columnName”:”order_id”,”logicTableName”:”t_order”,”values”:[“UD020003011903261545436593200002”]} ,包含:分片列名,逻辑表名,当前列的具体分片值
该方法返回值为
参数名 解释
Collection<String> 分片结果,可以是目标数据源,也可以是目标数据表,此处为数据源
接着回来看业务逻辑,伪代码如下
首先打印了一下数据源集合 availableTargetNames 以及 分片属性 shardingValues的值,执行测试用例后,日志输出为:
availableTargetNames:["t_order_0","t_order_1","t_order_2","t_order_3"],
shardingValues:[{"columnName":"user_id","logicTableName":"t_order","values":["UD020003011903261545436593200002"]},
{"columnName":"order_id","logicTableName":"t_order","values":["OD000000011903261545475143200001"]}]
从日志可以看出,我们可以在该路由方法中取到配置时的物理数据源列表,以及在运行时获取本次执行时的路由属性及其值
完整的逻辑流程如下:
- 定义一个集合用于放置最终匹配好的路由数据源,接着对shardingValues进行遍历,目的为至少命中一个路由键
- 遍历shardingValues循环体中,打印了当前循环的shardingValue,即实际的分片键的数值,如:订单号、用户id等。通过getIndex方法,获取该分片键值中包含的物理数据源索引
- 接着遍历数据源列表availableTargetNames,截取当前循环对应availableTargetName的索引值,(eg: ds0则取0,ds1则取1…以此类推)将该配置的物理数据源索引与 第2步 中解析到的数据源路由索引进行比较,两者相等则表名我们期望将该数据路由到该匹配到的数据源。
- 执行这个过程,直到匹配到一个路由键则停止循环,之所以这么做是因为我们是复合分片,至少要匹配到一个路由规则,才能停止循环,最终将路由到的物理数据源(ds0/ds1/ds2/ds3)通过add方法添加到事先定义好的集合中并返回给框架。
- 逻辑结束。
小结
本文中,基本完成了Sharding-JDBC中复合分片路由算法的自定义实现,并经过测试验证符合预期,该实现方案在生产上已经经历过考验。定义分片路由策略的核心还是要熟悉ComplexKeysShardingAlgorithm,对如何解析 doSharding(CollectionavailableTargetNames, CollectionshardingValues)的参数有明确的认识,最简单的方法就是实际打印一下参数,相信会让你更加直观的感受到作者优良的接口设计能力,站在巨人的肩膀上我们能看到更远。
到此这篇关于Sharding-Jdbc 自定义复合分片的实现的文章就介绍到这了,更多相关Sharding-Jdbc 自定义复合分片内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/218500/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)