
requests 库最常见的操作
请求参数以及请求方法
导入 requests 库之后,基本都在围绕 requests.get 做文章,这里重点要回顾的是 get 方法的参数,其中包含如下内容,下述内容在官方手册没有呈现清单,通过最新版源码分析。
除 url 参数外,其余都为可选参数,即非必选。
- url:请求地址;
- params:要发送的查询字符串,可以为字典,列表,元组,字节;
- data:body 对象中要传递的参数,可以为字段,列表,元组,字节或者文件对象;
- json:JSON 序列化对象;
- headers:请求头,字典格式;
- cookies:传递 cookie,字段或 CookieJar 类型;
- files:最复杂的一个参数,一般出现在 POST 请求中,格式举例 "name":文件对象 或者 {'name':文件对象},还可以在一个请求中发送多个文件,不过一般爬虫场景不会用到;
- auth:指定身份验证机制;
- timeout:服务器等待响应时间,在源码中检索到可以为元组类型,这个之前没有使用过,即 (connect timeout, read timeout);
- allow_redirects:是否允许重定向;
- proxies:代理;
- verify:SSL 验证;
- stream:流式请求,主要对接流式 API;
- cert:证书。
以上内容就是 GET 请求中可以配置的参数,除了 GET 请求外,requests 还内置了其他的服务器请求方式,如下所示,这些方法需要的参数与上述清单一致。
GET, OPTIONS, HEAD, POST, PUT, PATCH, or DELETE
在 Python 爬虫的实战当中,主要以 GET 与 POST 为主,常用的参数为:
url,params,data,headers,cookies,timeout,proxies,verify。
响应对象的属性与方法
使用 requests 库请求之后,会得到一个 Response 对象,该对象最重要的内容就是属性与方法,通过 dir 函数可以获取 Response 对象的属性和方法。
help(res)
print(dir(res))
获取到的内容如下所示,其中有我们之前案例中常见的一些内容。
['__attrs__', '__bool__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__nonzero__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_content', '_content_consumed', '_next', 'apparent_encoding', 'close', 'connection', 'content', 'cookies', 'elapsed', 'encoding', 'headers', 'history', 'is_permanent_redirect', 'is_redirect', 'iter_content', 'iter_lines', 'json', 'links', 'next', 'ok', 'raise_for_status', 'raw', 'reason', 'request', 'status_code', 'text', 'url']
如果只将 requests 库应用在爬虫采集领域,那上述属性与方法中,比较常用的有:
属性 property
- ok:只要状态码 status_code 小于 400,都会返回 True;
- is_redirect:重定向属性;
- content:响应内容,字节类型;
- text:响应内容,Unicode 类型;
- status_code:响应状态码;
- url:响应的最终 URL 位置;
- encoding:当访问 r.text 时的编码;
方法
- json:将响应结果序列化为 JSON;
会话对象
在本专栏前面的文章中,存在一个被忽略的 requests 高级特性,即会话对象
该对象能够在跨域请求的时候,保持住某些参数,尤其是 cookie
如果你想向同一主机发送多个请求,使用会话对象可以将底层的 TCP 连接进行重用,带来显著的性能提升。
- 会话对象使用非常简单,在发起 requests 对象之前,增加如下所示代码即可。
# 建立会话对象
s = requests.Session()
# 后续都使用会话对象进行进行,而不是直接使用 requests 对象
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)
由于专栏前面并未涉及相关案例,故直接引入官方手册案例说明。
- 下述代码演示的是会话也可用来为请求方法提供缺省数据,顾名思义就是直接给会话对象增加的请求参数,在后续代码中默认可用。
import requests
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# both 'x-test' and 'x-test2' are sent
r = s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})
print(r.text)
接下来官网案例还展示了 法级别的参数也不会被跨请求保持,即在 s.get() 方法中如果传递了 cookie,那不会被保持住,这两个案例,从正面与反面为我们核心展示的就是,如何使用会话对象保持参数
- 通过会话对象的属性设置的参数,能被保持,
- 而通过会话对象方法传递的参数,不能被保持。
SSL 证书验证,客户端证书,CA 证书
在爬虫采集数据的过程中,碰到 https 的网站在正常不过,requests 库使用过程中 SSL 验证是默认开启的,如果证书验证失败,即抛出 SSLError错误。
不过更多的时候,我们通过设置 verify = False ,忽略对 SSL 证书的验证,除非及其特殊的情况,必须增加相关证书逻辑。
代理
有的网站在采集过程中,会针对 IP 进行限制,此时就需要使用代理进行跳过操作,设置 proxies 参数即可,本部分内容比较简单,后续很多案例还会复用到。
除了 HTTP 代理外, requests 2.10 版本之后,增加了 SOCKS 代理,如果你需要使用,需要通过 pip 安装相应库。
pip install requests[socks]
安装完毕,出现新的第三方库 PySocks,使用方式与 HTTP 代理一致。
Cookie
爬虫采集过程会大量的与 cookie 打交道,
获取网站响应的 cookie,使用 response 对象的 cookies 属性即可。
- 如果希望向服务器传递 cookie,可以通过 cookies 参数,例如下述代码:
url = 'http://httpbin.org/cookies' cookies = dict(cookies_are='working') r = requests.get(url, cookies=cookies)
- 如果你希望对 cookie 有更加细致的操作,重点研究 requests.cookies.RequestsCookieJar 对象即可,简单的代码使用如下所示:
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
url = 'http://httpbin.org/cookies'
r = requests.get(url, cookies=jar)
print(r.text)
RequestsCookieJar 对象具备更加丰富的接口,适合跨域名跨路径使用,相关接口查询:
https://docs.python-requests.org/zh_CN/latest/api.html#requests.cookies.RequestsCookieJar
requests 非常适合作为 Python 爬虫入门阶段第一选择,其简单的接口与代码封装
- 能大幅度降低网络请求代码编写难度,让你专注与目标数据的提取,
- 更有基于高级请求的封装作为提高部分,该库完全可以贯穿你的整个爬虫工程师生涯。
lxml 库
lxml 库是一款 Python 数据解析库,参考重要文档在 https://lxml.de/,项目开源地址在:https://github.com/lxml/lxml,在一顿检索之后,发现 lxml 没有中文相关手册,不过好在英文文档阅读难度不大,我们可以直接进行学习。
lxml.etree
纵览之前的博客内容,出场率最高的就是 lxml.etree ,其次就是 Element 对象,我们在解析数据的时候,大量的代码都是基于 Element 对象的 API 实现。
- 在爬虫代码采集过程中,通过 etree.HTML 直接将字符串实例化为 element 对象。
import requests
from lxml import etree
res = requests.get("http://www.jsons.cn/zt/")
html = res.text
root_element = etree.HTML(html)
print(root_element)
print(root_element.tag)
上述代码输出内容如下所示:
<Element html at 0x3310508>
html
- 其中需要注意的是 Element 后面的 html,该字符串表示对象的标签名为 html,如果使用下述代码:
print(root_element[1])
- 上述内容得到的是 <Element body at 0x356e248>,即 body 标签,同样的操作可以使用子元素获取。
print("*"*100)
for child in root_element:
print(child.tag)
上述代码输出的内容为:
head
body
该输出表示在 html 标签中,只包含head 与 body 标签,实际情况也确实如此,为了验证,你可以在 循环中继续嵌套一层。
此时输出的内容就变得丰富了需求,如下图所示:
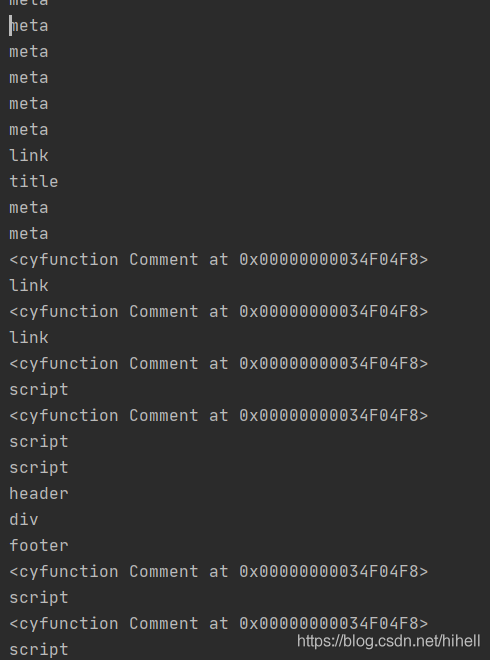
你也可以通过 etree.tostring(element对象) 直接将该对象转换为字符串进行输出。
for child in root_element:
for item in child:
print(item.tag)
print(etree.tostring(item))
XPath
lxml 库可以配合其他的解析引擎进行工作,首次接触的就是 XPath,关于 XPath 相关的知识,我们后续会细化学习,本节课依旧从 lxml 的角度出发,为你介绍。
在爬虫代码编写中,直接使用 html.xpath("xpath表达式") 即可获取目标数据,例如获取网页 title。
print(root_element.xpath('//title'))
获取网页所有文本:
print(root_element.xpath('string()'))
获取到 element 对象之后,可调用 text 属性,获取对应文本,在使用的时候,需要注意使用 XPath 获取到的 element 对象,都是列表。
title_element = root_element.xpath('//title')
print(title_element[0].text)
在 lxml 中,还内置了一款 简单的类似 XPath 的路径语言,称为 ElementPath,例如查询 title,需要从 head 开始检索,否则返回 None。
print(root_element[0].find("title"))
官方提供的方法如下:
- iterfind(): 返回查找到的数据,迭代器形式返回;
- findall(): 返回匹配到的列表;
- find(): 返回第一个匹配到的数据;
- findtext(): 返回匹配到的文本数据,第一个。
lxml 其他说明
lxml 除了可以配合 XPath 实现数据解析外,还可以与 cssselect ,BeautifulSoup,html5lib 配合使用,这部分在后续的案例中,将逐步进行展开。
lxml 在爬虫领域,更多的是在提取数据,因此较于该库本身,掌握 XPath 等解析表达式的写法更加重要。
鉴于该库手册没有被翻译,后期可以尝试将其翻译为中文。
到此这篇关于总结python常用request库与lxml库常用操作的文章就介绍到这了,更多相关python中request库与lxml库内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/220022/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)