
前言
一年多没更新博客了,原因是疫情期间《骑马与砍杀2》发售,然后去写游戏MOD去了。
用C#大概写了7个月的游戏MOD,每天晚上肝到很晚,然后期间又因为介绍这个游戏MOD,学习了PR,然后做起了B站的UP主。
再到后面有了些别的想法和公司业务调整,也懒得写博客,不知不觉一年多也就过去了。
收获还是有的:
- 比如在断更这个MOD时,不论是在中文站还是3DM的MOD站,这个MOD的下载量都是排第一的,而且甩第二名相当远。如果有玩《骑砍2》MOD的朋友,应该猜出来我是谁了。
- 又比如在B站收获了五千多粉丝,从一开始说话结结巴巴,到最后也还是说得结结巴巴。不过因为自己的剪辑,观看效果也还不错。
- 又比如深刻认识到做个UP和主播有多麻烦,就我这拉胯的数据其实已经领先了B站很多UP主了。UP主中更多的不是头部UP,而是视频0播放的UP主。你可以看一下B站的最新视频,翻了几十页全是0播放,极为壮观。
- 有趣的人生体验增加了
好了,言归正传。
现在基本MOD断更,UP主也懒得继续认真做了。
这里主要还是谈一下技术相关的,也就是一个纯前端实现,用于写MOD的XML在线编辑器。
它是一个仿VSCode风格的编辑器,可以自动学习游戏MOD文件生成约束规则,帮助我们实现代码提示和代码校验。
更重要的是它可以直接修改你电脑上的的文件。
这是最终成品的代码仓库:https://gitee.com/vvjiang/mod-xml-editor
以及一张成品展示图:
本篇博客所涉及到的技术:
- CodeMirror
- react-codemirror2
- xmldom
- FileReader
- IndexDB
- Web Worker
- File System Access
让我们从头开始讲起。
在线XML编辑器的需求
在做《骑砍2》的MOD时,需要经常写XML文件。
因为骑砍2的数据配置就是以XML的形式保存,然后MOD加载后,用MOD的XML去覆盖官方自己的XML。
通常我们做MOD数据这块,就是参考官方的XML自己去写XML文件。
但是这样会遇到一个问题,XML这东西没有代码提示和代码校验,写错一个字符也很难发现。
又或者有时候游戏更新,它的XML规则可能会改动。
官方是不会发布通知告诉你这些改动点的,所以如果你还是用的以前的元素和属性那就等于写错了。
写错的结果往往是游戏加载MOD时直接崩溃,也不会给你任何提示,你只能慢慢去寻找BUG。
而骑砍2作为一个大型游戏,每次启动时间都很长,导致你测试一个MOD数据是否配置正确的测试流程会非常长。
妈耶,多少个夜晚,游戏崩溃的那一瞬间,我人就崩溃了。
所以后来我就想着做一个XML在线编辑器去解决这个问题。
技术预研
可视化编程
其实我一开始没有做这个XML编辑器的想法,因为这玩意一看就难搞,而是想通过一个可视化编程,通过拖拉拽元素和属性的方式去实现。
你别说,我还真的做了一套初步方案出来,结果配置一个大型的XML这玩意拖拉拽无数次,心态逐渐爆炸,遂放弃此方案。
VSCODE插件
想看看有没有什么VSCode插件可以进行代码提示,有一个使用XSD进行代码校验的,貌似还是IBM提供的。
但是很可惜已经废弃,然后用不了了,放弃此方案。
在线编辑器
后来之所以使用在线编辑器的方式做这个,是因为三四月份公司这边想要做一个在线编辑java项目环境xml配置文件的一个东西。
然后我这边就尝试着做了一个,了解到了CodeMirror。
CodeMirror通过自己配置tags来支持xml的代码提示,但是并不支持xml的代码校验,所以需要自己去做xml的代码校验。
并且因为通常我们去校验xml用的是xsd,所以还需要将xsd转换成CodeMirror的tags配置。
这个不论是百度Google,还是说Github,都是查不到相对应的方案,所以只能自己写代码去实现。
在这个过程中,我对CodeMirror,xsd,htmllint都有了比较深的一个了解,最终完成了项目。
因为这是之前公司的代码,所以这里就不放出来了。
总之,在这个过程中了解到CodeMirror这么个东西,才有了用CodeMirror去做MOD的在线编辑器的想法。
最初形态:简单的在线XML编辑器
好了,废话不说,拿起键盘就是无脑干。
最初形态没有左侧的文件树,只有一个单纯的编辑器和一个规则学习弹框。
涉及到的技术就三个:
CodeMirror
FileReader
xmldom
用CodeMirror做编辑器
CodeMirror这块主要使用的react的一个封装版react-codemirror2,反正就是看文档和Demo自己配。
唯一的难度就是网上一大堆的CodeMirror配置介绍很多都是抄来抄去,转载来转载去,还是个错的,简直离谱。

总之你想玩的话最好还是看官方文档(https://codemirror.net/) 和文档上的Demo,然后自己研究下,抄别人配置的话水很深,你把握不住的。
我这里贴一段我封装的编辑器组件的配置代码吧,反正绝对可用,绝大多数编辑器的功能都OK,不过仅仅适用于编辑XML。
里面的注释比较详尽了,包括常用的代码折叠,代码格式化都有,我就懒得一一讲了,你可以参考官网自己看看。
其中的一些引用代码我就不贴了,有兴趣的可以去上面提到的代码仓库看看。
import { useEffect } from 'react'
import { Controlled as ControlledCodeMirror } from 'react-codemirror2'
import CodeMirror from 'codemirror'
import 'codemirror/lib/codemirror.css'
import 'codemirror/theme/ayu-dark.css'
import 'codemirror/mode/xml/xml.js'
// 光标行代码高亮
import 'codemirror/addon/selection/active-line'
// 折叠代码
import 'codemirror/addon/fold/foldgutter.css'
import 'codemirror/addon/fold/foldcode.js'
import 'codemirror/addon/fold/xml-fold.js'
import 'codemirror/addon/fold/foldgutter.js'
import 'codemirror/addon/fold/comment-fold.js'
// 代码提示补全和
import 'codemirror/addon/hint/xml-hint.js'
import 'codemirror/addon/hint/show-hint.css'
import './hint.css'
import 'codemirror/addon/hint/show-hint.js'
// 代码校验
import 'codemirror/addon/lint/lint'
import 'codemirror/addon/lint/lint.css'
import CodeMirrorRegisterXmlLint from './xml-lint'
// 输入> 时自动键入结束标签
import 'codemirror/addon/edit/closetag.js'
// 注释
import 'codemirror/addon/comment/comment.js'
// 用于调整codeMirror的主题样式
import style from './index.less'
// 注册Xml代码校验
CodeMirrorRegisterXmlLint(CodeMirror)
// 格式化相关
CodeMirror.extendMode("xml", {
commentStart: "<!--",
commentEnd: "-->",
newlineAfterToken: function (type, content, textAfter, state) {
return (type === "tag" && />$/.test(content) && state.context) ||
/^</.test(textAfter);
}
});
// 格式化指定范围
CodeMirror.defineExtension("autoFormatRange", function (from, to) {
var cm = this;
var outer = cm.getMode(), text = cm.getRange(from, to).split("\n");
var state = CodeMirror.copyState(outer, cm.getTokenAt(from).state);
var tabSize = cm.getOption("tabSize");
var out = "", lines = 0, atSol = from.ch === 0;
function newline() {
out += "\n";
atSol = true;
++lines;
}
for (var i = 0; i < text.length; ++i) {
var stream = new CodeMirror.StringStream(text[i], tabSize);
while (!stream.eol()) {
var inner = CodeMirror.innerMode(outer, state);
var style = outer.token(stream, state), cur = stream.current();
stream.start = stream.pos;
if (!atSol || /\S/.test(cur)) {
out += cur;
atSol = false;
}
if (!atSol && inner.mode.newlineAfterToken &&
inner.mode.newlineAfterToken(style, cur, stream.string.slice(stream.pos) || text[i + 1] || "", inner.state))
newline();
}
if (!stream.pos && outer.blankLine) outer.blankLine(state);
if (!atSol && i < text.length - 1) newline();
}
cm.operation(function () {
cm.replaceRange(out, from, to);
for (var cur = from.line + 1, end = from.line + lines; cur <= end; ++cur)
cm.indentLine(cur, "smart");
cm.setSelection(from, cm.getCursor(false));
});
});
// Xml编辑器组件
function XmlEditor(props) {
const { tags, value, onChange, onErrors, onGetEditor, onSave } = props
useEffect(() => {
// tags 每次变动时,都会重新改变校验规则
CodeMirrorRegisterXmlLint(CodeMirror, tags, onErrors)
}, [onErrors, tags])
// 开始标签
function completeAfter(cm, pred) {
if (!pred || pred()) setTimeout(function () {
if (!cm.state.completionActive)
cm.showHint({
completeSingle: false
});
}, 100);
return CodeMirror.Pass;
}
// 结束标签
function completeIfAfterLt(cm) {
return completeAfter(cm, function () {
var cur = cm.getCursor();
return cm.getRange(CodeMirror.Pos(cur.line, cur.ch - 1), cur) === "<";
});
}
// 属性和属性值
function completeIfInTag(cm) {
return completeAfter(cm, function () {
var tok = cm.getTokenAt(cm.getCursor());
if (tok.type === "string" && (!/['"]/.test(tok.string.charAt(tok.string.length - 1)) || tok.string.length === 1)) return false;
var inner = CodeMirror.innerMode(cm.getMode(), tok.state).state;
return inner.tagName;
});
}
return (
<div className={style.editor} >
<ControlledCodeMirror
value={value}
options={{
mode: {
name: 'xml',
// xml 属性换行的时候是否加上标签的长度
multilineTagIndentPastTag: false
},
indentUnit: 2, // 换行的默认缩进多少个空格
theme: 'ayu-dark', // 编辑器主题
lineNumbers: true,// 是否显示行号
autofocus: true,// 自动获取焦点
styleActiveLine: true,// 光标行代码高亮
autoCloseTags: true, // 在输入>时自动键入结束元素
toggleComment: true, // 开启注释
// 折叠代码 begin
lineWrapping: true,
foldGutter: true,
gutters: ['CodeMirror-linenumbers', 'CodeMirror-foldgutter', 'CodeMirror-lint-markers'],
// 折叠代码 end
extraKeys: {
// 代码提示
"'<'": completeAfter,
"'/'": completeIfAfterLt,
"' '": completeIfInTag,
"'='": completeIfInTag,
// 注释功能
"Ctrl-/": (cm) => {
cm.toggleComment()
},
// 保存功能
"Ctrl-S": (cm) => {
onSave()
},
// 格式化
"Shift-Alt-F": (cm) => {
const totalLines = cm.lineCount();
cm.autoFormatRange({ line: 0, ch: 0 }, { line: totalLines })
},
// Tab自动转换为空格
"Tab": (cm) => {
if (cm.somethingSelected()) {// 选中后整体缩进的情况
cm.indentSelection('add')
} else {
cm.replaceSelection(Array(cm.getOption("indentUnit") + 1).join(" "), "end", "+input")
}
}
},
// 代码提示
hintOptions: { schemaInfo: tags, matchInMiddle: true },
lint: true
}}
editorDidMount={onGetEditor}
onBeforeChange={onChange}
/>
</div>
)
}
export default XmlEditor
学习XML,并提取出tags规则
当我们使用CodeMirror做一个简单的编辑器时,想要进行一个XML的代码提示,是需要使用到tags。
很明显,不同的游戏有不同的XML规则,包括游戏更新之后XML规则也会更改。
所以我们必须要保证有一个机制去不断地学习这些XML规则,所以这里我做了一个学习XML文件规则的弹窗去做这个事情。
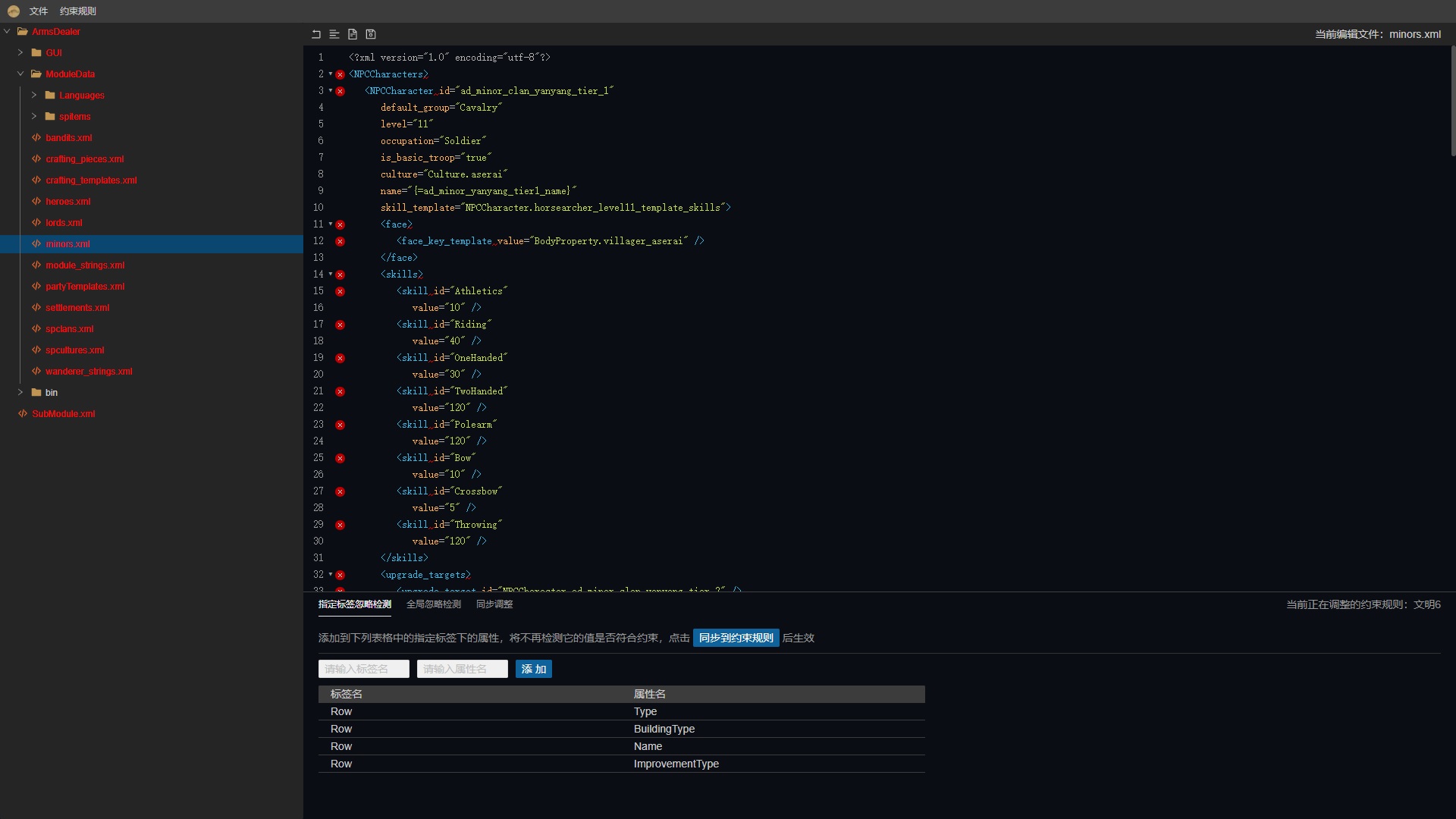
点击编辑器左上方的 约束规则——>新增约束规则
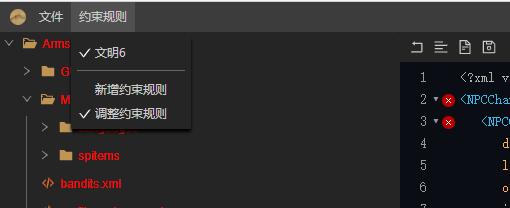
会弹出这样一个弹窗:
通过FileReader读取指定文件夹的XML文件,然后使用xmldom来依次解析这些xml文件的文本,生成文档对象。
再分析这些文档对象得到最终的tags规则。
这一步骤只需要对xml有所了解,其实也蛮基础的,所以不讲了。
总之现在我们完成了它的最初形态,你每次使用它需要将你编辑的XML文件内容复制到这个在线编辑器,编辑完后,再将完成的文本复制到原XML文件保存覆盖。
进化形态:加载树形文件结构和全文件校验功能的在线XML编辑器
上面的编辑器其实使用场景非常窄,只能在新写一个XML时使用。
一个MOD往往几十上百,甚至几千个文件,不可能一个个粘贴到编辑器中进行校验。
所以我们需要在这个编辑器中,加载MOD的所有XML文件,并进行一个代码校验。
涉及到的技术就两个:
- FileReader
- Web Worker
左侧文件树
左侧这个文件树使用Ant Design的Tree组件完成,这里配置什么的就不讲了。
在点击打开文件夹这个按钮时
同样使用FileReader来读取MOD文件夹中的文件。
但是FileReader获取到的是一个文件数组,要想生成我们左侧的树形结构需要自己手动解析每个XML文件的路径,并据此生成一个树形结构。
全文件校验功能
在打开文件夹的一瞬间,我们需要对全部的XML文件进行一次代码校验,如果校验有误,需要在左侧文件夹上将相关的文件及它父级祖级的一系列文件夹全部标红。
这个功能表面上很简单,其实坑点很大,因为校验的计算量实际上并不小,特别是你的MOD中有几百几千个文件的时候,非常容易搞得你js阻塞,页面无响应。
在这里我使用了Web Worker新开一个线程去处理这个校验过程,在校验完成后将结果返回给我。
在这个过程中,我对Web Worker的使用也有了更多的了解。
印象中一直以为是一个new Worker(某js文件)这样的方式去玩,感觉很难结合react的模块化开发来使用。
但是实际上现在在webpack里配置上worker-loader,可以很方便使用Web Worker。
首先我们的worker代码可以写成下面这样:
import { lintFileTree } from '@/utils/files'
onmessage = ({ data }) => {
lintFileTree(data.fileTree, data.currentTags).then(content => {
postMessage(content)
})
}
然后我们使用这个Worker时,可以如下所示
import { useWebWorkerFromWorker } from 'react-webworker-hook'
import lintFileTreeWorker from '@/utils/webWorker/lintFileTree.webworker'
const worker4LintFileTree = new lintFileTreeWorker()
const [lintedFileTree, startLintFileTree] = useWebWorkerFromWorker(worker4LintFileTree)
然后你再用个useEffect依赖这个lintedFileTree,如果变动了就做某些操作,所以写起来就像用useState一样轻松。
非递归遍历树
大家可以看到上面我们用到的这些东西,很多都与树相关,比如遍历文件树去校验代码。
又或者我们切换了某个约束规则后,也是需要遍历整个文件树进行重新校验的。
遍历的过程中,之前我用的是递归遍历整个树,这样做不好的地方在于递归的时候内存得不到释放,所以后来我换了一种算法,采用非递归的方式遍历整个树。
IndexDB保存文件内容
因为我们的MOD文件内容比较多比较大,所以内存占用可能会很大,不可能一直把这些文件内容放到内存中。
所以我读取到文件内容会依次放入IndexDB中,只展示当前编辑文件的内容。
只有在需要的时候,比如全文件校验或者切换文件时,才从IndexDB再次获取文件内容。
究极进化形态:突破浏览器沙盒限制,实现对电脑本地文件的增删改
通过之前的操作,我们终于完成了一个基本可用的在线XML编辑器。
但是它有一个致命缺点,就是受到浏览器沙盒环境的限制,我们在修改了文件后,没法直接保存到电脑上,而必须依靠手动将修改好的代码一一复制到对应的文件中。
这个操作繁琐复杂,导致我们编辑器的功能可能只能用来辅助编写代码和批量校验。
之前我以为只能做到这种程度,但是后来我在知乎上偶然看了一个帖子,发现Chrome86+的版本多了一个功能API:FileSystemAccess。
另外,除非是本地localhost环境,否则这个API只在https环境下才能调用,也就是说你在一个http的网站上,即使你用的是Chrome86+或者是Edge86+,那也是调用不了的。
这个API可以让我们直接操作本地电脑上的文件,而不是像FileReader一样只能读,或者像FileSystem一样只能在浏览器沙盒内操作。
通过FileSystemAccess我们不仅可以实现对文件夹中的文件进行读取修改,还能新增和删除文件。
所以我使用这个API全面替换了之前使用FileReader的各个点,实现了在文件树上右键进行文件夹和文件的新增和删除。(这里是不支持对文件进行重命名的,不过其实我们可以使用删除后再新增的方式来模拟重命名,但是我就懒得做了)
同时在按保存按钮或者按保存的快捷键Ctrl+S后,就可以直接对文件进行保存操作。
下面是一个使用FileSystemAccess打开文件夹的组件代码:
import React from 'react'
// 自定义的打开文件夹组件
const FileInput = (props) => {
const { children, onChange } = props
const handleClick = async () => {
const dirHandle = await window.showDirectoryPicker()
dirHandle.requestPermission({ mode : "readwrite" })
onChange(dirHandle)
}
return <span onClick={handleClick}>
{children}
</span>
}
export default FileInput
只要被这个组件包裹的元素(比如按钮)被点击后,会立即调用showDirectoryPicker,请求打开文件夹。
在打开文件夹后,通过获得的文件夹handle去请求文件夹写入权限,然后再把这个文件夹handle传到外部,获取文件树结构。
这里的操作是有瑕疵的,因为请求打开文件夹时浏览器会弹框向用户获取读取文件夹的权限,
打开完毕后又直接会弹第二次框获取写入权限,也就是说在打开文件夹时会弹两次框。
但是我也只能通过这种手法一次性请求到所有的权限,要不然等到要保存时再去请求权限也不太好。
不过瑕不掩瑜,通过这个API不仅实现了文件的增删改,还解除了对IndexDB的使用。
因为我们随时可以通过文件Handle获取到相应的文件内容,所以没必要将文件内容保存到IndexDB中。
更多的功能与细节
以上我只是对技术上的核心功能进行了概述,实际上这个编辑器还有N多的细节。
比如调整tags规则的面板,比如那些工具栏的按钮,比如对dva的简单封装处理,比如对xml进行分析时,如果属性值是数字,那么就不进行提示,而是直接忽略,因为数字往往没太大意义而且枚举值太大。
这一切的一切,都太多太多,但是它们的应用都比较基础,所以不想赘述细节,否则这篇博客就会变得非常长,而且难以突出核心思路。
不足与总结
这里的不足更多的是因为懒,比如之前说的文件夹和文件重命名功能,还有调整tags规则的自定义规则那里不支持修改删除。
可以实现,只是懒得做了。
这个东西前前后后做了几个月,也不是说每天晚上都在写这个,主要是有灵感了就来写一下,或者发现哪里可以更好地改进一下就再写一下。
合起来约摸着有两三周的每个晚上在做这个事情,然后当它愈加趋近于完善和可用时,就愈加懒得做了。
因为剩下的操作不太重要,且脑补一下就可以完成,没有太多有挑战性的地方了。
不过总体来说,这个东西现在的可用性还是很强的。
不仅仅可以用于《骑马与砍杀2》、《了不起的修真模拟器》、《文明6》等一系列游戏的XML文件的辅助编写,还可以用于那些没有XSD规则,又过于复杂的XML配置,甚至它还可以学习你自定义的XML规则。
到此这篇关于js制作xml在线编辑器实例的文章就介绍到这了,更多相关js制作xml在线编辑器内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/220629/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)