
环境:
scala:2.12.10
spark:3.0.3
1、创建scala maven项目,如下图所示:
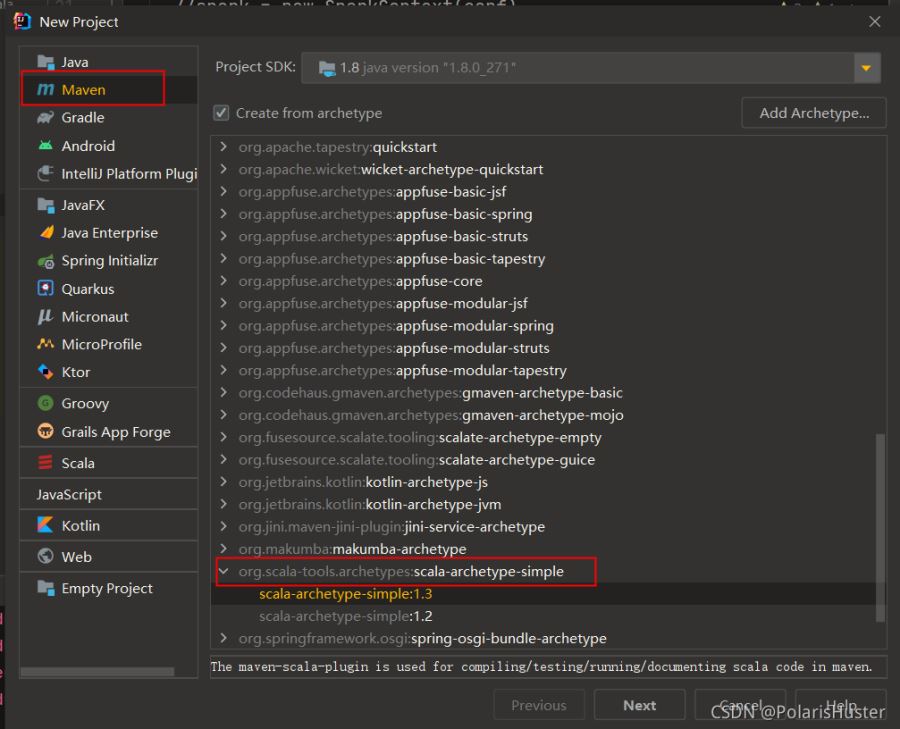 2、
2、
不同版本scala编译参数可能略有不同,笔者使用的scala版本是2.12.10,scala-archetype-simple插件生成的pom文件
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
要去除-make:transitive这个参数,否则会报错。
3、创建SparkPi Object类
object SparkPi {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("Spark Pi")
.master("spark://172.21.212.114:7077")
.config("spark.jars","E:\\work\\polaris\\polaris-spark\\spark-scala\\target\\spark-scala-1.0.0.jar")
.config("spark.executor.memory","2g")
.config("spark.cores.max","2")
.config("spark.driver.host", "172.21.58.28")
.config("spark.driver.port", "9089")
.getOrCreate()
//spark = new SparkContext(conf).
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
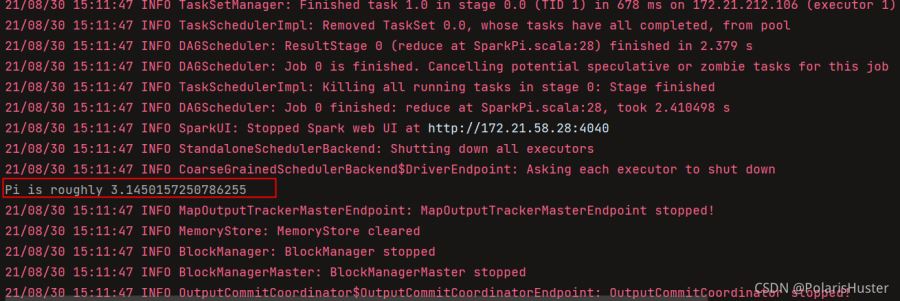
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}
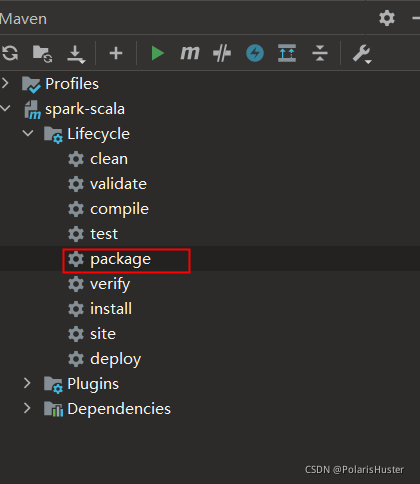
4、执行打包命令:
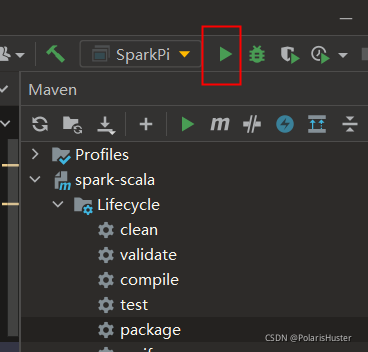
5、点击Idea Run执行即可:
6、结果如下所示:
PS:
1、创建SparkSession时需要指定Idea所在机器ip地址,因为默认会把Spark Driver所在机器域名发送过去,导致无法解析(在spark 服务器上配置IDEA所在机器域名也可以,但是这样太不灵活)
2、spark-3.0.3默认使用的scala版本是2.12.10,所以要注意IDEA使用scala版本,否则会出现SerailizableId不一致的兼容问题
到此这篇关于IDEA创建spark maven项目并连接远程spark集群的文章就介绍到这了,更多相关IDEA spark集群内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/221232/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)