
今天把这段时间学习完shell后完成工作上的一个小案件整理了一下,分享给大家!
说来也巧了,作为一个刚刚毕业半年的菜鸟,进入公司后,听公司的大牛推荐学习linux–”鸟哥的私房菜“,基本上是从去年8月份开始到了今年的1月份,基本上是把基础篇看完了,开始了解shell脚本的相关知识。刚好公司有了一个shell脚本的案件给我了,时间上也没有多紧。然后就一边学习一边开始做,虽然中途客户反映先前的业务逻辑有问题耽搁了两周,但总算是到最后完成了,自己学习的东西能用到很开心,今天闲了,把代码整理了一下,分享给大家
具体是这样:
要求是写一个shell脚本,安装要求查询数据,将符合条件的数据按照客户给定的xml样式进行组装,然后加入到crontab中,定时执行通过scp或者ftp放到客户服务器上。
具体实现步骤:
一、编写生成xml文档的代码
网上搜索了一篇博客:http://blog.csdn.net/dengzhaoqun/article/details/7262271 拿来学习了一下,感觉好用,自己就根据自己的实际情况修改了一下:
#! /bin/bash
# filename: create_xml.sh
# create_wangxb_20150123
#
# 从外部传入的第一个参数作为xml的文件名
outfile=$1
# xml中的缩进位
tabs=0
# ++++++++++++++++++++++++++++
# 组装一个节点,输出到文件
# 说一说传参数时的这几个区别:假如有下面这个脚本执行的命令
# /path/to/scriptname opt1 opt2 opt3 opt4
# $0: 的值是默认是脚本的名字,从$1-$4 开始就是参数的值
# $# :代表后接的参数『个数』
# $@ :代表『 "$1" "$2" "$3" "$4" 』之意,每个变量是独立的(用双引号括起来);
# $* :代表『 "$1c$2c$3c$4" 』,其中 c 为分隔字节,默认为空白键, 所以本例中代表『 "$1 $2 $3 $4" 』之意。
# 在shell中我们可以也可以使用${}包含变量名,来调用变量
# ++++++++++++++++++++++++++++
put(){
echo '<'${*}'>' >> $outfile
}
# 这里也是输出一个xml的节点,只是比上面的节点有更多的设置
# ${@:2} 的意思:它的值就是由第二个参数开始到最后一个参数,为什么要这样?有时可能你的第二个参数中有空格,shell接受参数是以空格计算的
put_tag() {
echo '<'$1'>'${@:2}'</'$1'>' >> $outfile
}
# 同样是一个输出节点函数,但是添加了CDATA,防止特殊字符造成xml解析失败
put_tag_cdata() {
echo '<'$1'><![CDATA['${@:2}']]></'$1'>' >> $outfile
}
put_head(){
put '?'${1}'?'
}
# 这是一个缩进的算法,自行理解
out_tabs(){
tmp=0
tabsstr=""
while [ $tmp -lt $((tabs)) ]
do
tabsstr=${tabsstr}'\t'
tmp=$((tmp+1))
done
echo -e -n $tabsstr >> $outfile
}
tag_start(){
out_tabs
put $1
tabs=$((tabs+1))
}
tag() {
out_tabs
if [ "$1" == 0 ]
then
put_tag $2 $(echo ${@:3})
elif [ "$1" == 1 ]
then
put_tag_cdata $2 $(echo ${@:3})
fi
}
tag_end(){
tabs=$((tabs-1))
out_tabs
put '/'${1}
}
这里有一些基础知识:
关于参数:
假如有下面这个脚本执行的命令
/path/to/scriptname opt1 opt2 opt3 opt4
$0: 的值是默认是脚本的名字,从$1-$4 开始就是参数的值
$# :代表后接的参数『个数』
$@ :代表『 "$1" "$2" "$3" "$4" 』之意,每个变量是独立的(用双引号括起来);
$* :代表『 "$1c$2c$3c$4" 』,其中 c 为分隔字节,默认为空白键, 所以本例中代表『 "$1 $2 $3 $4" 』之意。
在shell中我们可以也可以使用${}包含变量名,来调用变量
关于 ${@:2} 这种形式的说明,我转载了一篇博客:http://www.cnblogs.com/wxb0328/p/4276751.html
二、从数据库查数据利用上面的函数,制作xml文件
#!/bin/bash
# filename: ts_xml.sh
# create_wangxb_20150126
#
PATH=/u01/app/oracle/product/10.2.0/db_1/bin:/usr/kerberos/bin:/usr/local/bin:/bin:/usr/bin:/opt/dell/srvadmin/bin:/home/p3s_batch/tools:/home/p3s_batch/bin
export PATH
# Database account information file
source ~/.p3src
#++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# set some variable
# XMLSCRIPT: 脚本的绝对路径
# MATCHING_RESULT_XML: xml_1的文件名
# XML_FUNC_FILE: 生成xml函数文件路径
# MATCHING_RESULT_QUERY_DATA: sqlplus 查出数据保存的零时文件
# MATCHING_RESULT_QUERY_SQL: sqlplus 查询的sql语句
#++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# 下面是一些基础的设置
export XMLSCRIPT=/usr/p3s/batch/jaaa_match/tmp_xa_wangxb
XML_DIR="$XMLSCRIPT/xmldata"
XML_FUNC_FILE="xml_func.sh"
MATCHING_RESULT_XML="matching_result_"$(date '+%Y%m%d_%H%M%S')".xml"
MATCHING_RESULT_QUERY_DATA="matching_result_query_data.tmp"
MATCHING_RESULT_QUERY_SQL="matching_result_query.sql"
CLIENT_LIST_XML="client_list_"$(date '+%Y%m%d_%H%M%S')".xml"
CLIENT_LIST_QUERY_DATA="client_list_query_data.tmp"
CLIENT_LIST_QUERY_SQL="client_list_query.sql"
# add_wangxb_20150225
if [ ! -d "$XML_DIR" ];
then
mkdir $XML_DIR
fi
#+++++++++++++++++++++++++++
# modify_wangxb_20150224
# check for temporary file
#+++++++++++++++++++++++++++
if [ -e "$XML_DIR/$MATCHING_RESULT_XML" ];
then
rm -f $XML_DIR/$MATCHING_RESULT_XML
fi
if [ -e "$XMLSCRIPT/$MATCHING_RESULT_QUERY_DATA" ];
then
MATCHING_RESULT_QUERY_DATA="matching_result_query_data_"$(date '+%Y%m%d%H%M%S')".tmp"
fi
#+++++++++++++++++++++++++++++++++++++++++++++++++
# add_wangxb_20150225
# check system time, choice query time period
# 这是是根据crontab每天执行的时间,取得我们查询数据库时的where条件的时间区间
#+++++++++++++++++++++++++++++++++++++++++++++++++
sys_datetime=$(date '+%Y%m%d%H')
first_chk_datetime="$(date '+%Y%m%d')04"
second_chk_datetime="$(date '+%Y%m%d')12"
third_chk_datetime="$(date '+%Y%m%d')20"
# 由于服务器crontab是上面的时间,但是执行的shell比较多,在调用我这个shell的时候,不一定就是04:30 ,12:30, 20:30所以,这里的根据系统的时间判断时 范围给的比较宽
case $sys_datetime in
"$first_chk_datetime"|"$(date '+%Y%m%d')05"|"$(date '+%Y%m%d')06"|"$(date '+%Y%m%d')07")
chk_start=$(date '+%Y-%m-%d 21:00:00' -d '-1 day')
chk_end=$(date '+%Y-%m-%d 04:29:59')
;;
"$second_chk_datetime"|"$(date '+%Y%m%d')13"|"$(date '+%Y%m%d')14"|"$(date '+%Y%m%d')15")
chk_start=$(date '+%Y-%m-%d 04:30:00')
chk_end=$(date '+%Y-%m-%d 12:29:59')
;;
"$third_chk_datetime"|"$(date '+%Y%m%d')21"|"$(date '+%Y%m%d')22"|"$(date '+%Y%m%d')23")
chk_start=$(date '+%Y-%m-%d 12:30:00')
chk_end=$(date '+%Y-%m-%d 20:59:59')
;;
*)
chk_start=$(date '+%Y-%m-%d 00:00:00')
chk_end=$(date '+%Y-%m-%d 23:59:59')
;;
esac
# modify_wangxb_20150310
# 下面的是做一个oracle数据库连接的测试,如果连接失败,后续代码不再执行,并且写入错误日志
$ORACLE_HOME/bin/sqlplus -s $ORAUSER_WEB_PASDB << EOF
set echo off
set feedback off
alter session set nls_date_format='YYYY-MM-DD:HH24:MI:SS';
select sysdate from dual;
quit
EOF
if [ $? -ne 0 ]
then
echo "********** DBへのリンク己窃した **********"
exit
else
echo "********** DBへのリンクOKです **********"
fi
# sqlplus就是oracle的一个客户端软件,具体使用方法可以问度娘,这里传入要执行的sql和参数,将结果 > 输出到指定文件
$ORACLE_HOME/bin/sqlplus -s $ORAUSER_WEB_PASDB @$XMLSCRIPT/$MATCHING_RESULT_QUERY_SQL "$chk_start" "$chk_end" > $XMLSCRIPT/$MATCHING_RESULT_QUERY_DATA
# create matching result's xml file
# add_wangxb_20150227
# 下面的算法就是将查出的数据进行分析,调用xml函数生成xml文件
source "$XMLSCRIPT/$XML_FUNC_FILE" "$XML_DIR/$MATCHING_RESULT_XML"
put_head 'xml version="1.0" encoding="utf-8"'
tag_start 'ROOT'
if [ -s "$XMLSCRIPT/$MATCHING_RESULT_QUERY_DATA" ];
then
datas=${XMLSCRIPT}/${MATCHING_RESULT_QUERY_DATA}
#for res in $datas
while read res;
do
stock_id=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $1}')
seirino=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $2}')
match_flg=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $3}')
unmatch_riyuu=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $4}')
up_date_tmp=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $5}')
up_date=$(echo $up_date_tmp | awk 'BEGIN {FS="@"} {print $1 " " $2}')
tag_start 'MATCHING'
tag 0 'STOCKID' ${stock_id:-""}
tag 0 'SEIRINO' ${seirino:-""}
tag 0 'RESULT' ${match_flg:-""}
tag 1 'REASON' ${unmatch_riyuu:-""}
tag 0 'UPDATE_DATE' ${up_date:-""}
tag_end 'MATCHING'
done < $datas
fi
tag_end 'ROOT'
rm $XMLSCRIPT/$MATCHING_RESULT_QUERY_DATA
# create client list's xml file
# add_wangxb_2015027
# 下面的是再生成一个xml文件,和上面一样
if [ -e "$XML_DIR/$CLIENT_LIST_XML" ];
then
rm -f $XML_DIR/$CLIENT_LIST_XML
fi
if [ -e "$XMLSCRIPT/$CLIENT_LIST_QUERY_DATA" ];
then
CLIENT_LIST_QUERY_DATA="client_list_query_data_"$(date '+%Y%m%d%H%M%S')".tmp"
fi
$ORACLE_HOME/bin/sqlplus -s $ORAUSER_MND @$XMLSCRIPT/$CLIENT_LIST_QUERY_SQL > $XMLSCRIPT/$CLIENT_LIST_QUERY_DATA
source "$XMLSCRIPT/$XML_FUNC_FILE" "$XML_DIR/$CLIENT_LIST_XML"
put_head 'xml version="1.0" encoding="utf-8"'
tag_start 'ROOT'
if [ -s "$XMLSCRIPT/$CLIENT_LIST_QUERY_DATA" ];
then
datas=${XMLSCRIPT}/${CLIENT_LIST_QUERY_DATA}
#for res in $datas
while read res;
do
corporation_id=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $1}')
corporation_name=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $2}')
client_id=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $3}')
client_print_name=$(echo $res | awk 'BEGIN {FS="\\^\\*\\^"} {print $4}')
tag_start 'CLIENT'
tag 0 'CORPORATION_ID' ${corporation_id:-""}
tag 1 'CORPORATION_NAME' ${corporation_name:-""}
tag 0 'CLIENT_ID' ${client_id:-""}
tag 1 'CLIENT_PRINT_NAME' ${client_print_name:-""}
tag_end 'CLIENT'
done < $datas
fi
tag_end 'ROOT'
rm $XMLSCRIPT/$CLIENT_LIST_QUERY_DATA
# add_wangxb_20150304
# Convert xml file encoding
# 这是将xml文件进行转码,命令是iconv
if [ -e "$XML_DIR/$MATCHING_RESULT_XML" ];
then
echo "********** matching_result.xmlファイルコ〖ドを啪垂し、**********"
iconv -f euc-jp -t utf-8 $XML_DIR/$MATCHING_RESULT_XML -o $XML_DIR/$MATCHING_RESULT_XML.utf-8
mv $XML_DIR/$MATCHING_RESULT_XML.utf-8 $XML_DIR/$MATCHING_RESULT_XML
fi
if [ -e "$XML_DIR/$CLIENT_LIST_XML" ];
then
echo "********** client_list.xmlフィルコ〖ドを啪垂し、**********"
iconv -f euc-jp -t utf-8 $XML_DIR/$CLIENT_LIST_XML -o $XML_DIR/$CLIENT_LIST_XML.utf-8
mv $XML_DIR/$CLIENT_LIST_XML.utf-8 $XML_DIR/$CLIENT_LIST_XML
fi
# add_wangxb_20150304
# Send the xml file to the destination server by ftp
#ftp_host="222.***.***.***"
#USER="***"
#PASS="***"
#ftp -i -n $ftp_host << EOF
#user $USER $PASS
#cd /
#lcd $XML_DIR/
#put $MATCHING_RESULT_XML
#put $CLIENT_LIST_XML
#quit
#EOF
# test ftp
# 通过ftp将xml文件放到客户服务器上,ftp_host:客户服务器地址,user登录名,pass密码
ftp_host="***.***.***.***"
USER="***"
PASS="***"
dir="/upload"
ftp -i -n $ftp_host << EOF
user $USER $PASS
cd /upload/
lcd $XML_DIR/
put $MATCHING_RESULT_XML
put $CLIENT_LIST_XML
quit
EOF
# Save the program log file
YYMM=$(date +'%Y%m%d%H%M')
cp /tmp/create_xml.log /usr/p3s/batch/jaaa_match/tmp_xa_wangxb/logs/create_xml.log.$YYMM
# Send error log files into the Admin mailbox
info_to_mail_1="**@**.co.jp"
info_to_mail_2="***@**.co.jp"
# nkf 日文转码的一个命令
title=$(echo "test" | nkf -j)
nkf -j < /tmp/create_xml.log | mail -s $title $info_to_mail_1 $info_to_mail_2
#exit
关于nkf 日文转码:http://www.cnblogs.com/wxb0328/p/4333820.html
本来是用scp传送的,但是后面修改了,这里把自己为scp传送找到的一个,不用密码可立即登入的 ssh 用户
在鸟哥私房菜的服务器架设篇的第十一章中有介绍:http://vbird.dic.ksu.edu.tw/linux_server/0310telnetssh_2.php#ssh_nopasswd
下面是执行的两个sql文件
SET PAGESIZE 0
SET FEEDBACK OFF
SET VERIFY OFF
SET ECHO OFF
SET HEADING OFF
SET TIMI OFF
SET LINESIZE 1000
SET WRAP OFF
SELECT s.STOCKID|| '^*^' ||a.SERI_NO|| '^*^' ||a.MATCH_FLG|| '^*^' ||a.UNMATCH_RIYUU|| '^*^' ||to_char(a.UP_DATE,'YYYY-MM-DD@HH24:MI:SS') UP_DATE FROM aaa_stock_db a LEFT JOIN SENDDATAAPPRAISALPROTO s ON a.SERI_NO=s.SEIRINO WHERE a.UP_DATE BETWEEN to_date('&1','yyyy-mm-dd hh24:mi:ss') AND to_date('&2','yyyy-mm-dd hh24:mi:ss') AND a.DEL_FLG=0 ORDER BY a.UP_DATE DESC;
exit
SET PAGESIZE 0 SET FEEDBACK OFF SET VERIFY OFF SET ECHO OFF SET HEADING OFF SET TIMI OFF SET LINESIZE 1000 SET WRAP OFF SELECT a.CORPORATION_ID|| '^*^' ||a.CORPORATION_NAME|| '^*^' ||b.CLIENT_ID|| '^*^' ||(select CLIENT_PRINT_NAME from CLIENT_MASTER where CLIENT_ID = b.CLIENT_ID) as CLIENT_PRINT_NAME FROM M_CORPORATION_MASTER a LEFT JOIN M_CORPORATION_GROUP b ON (a.CORPORATION_ID = b.CORPORATION_ID) WHERE a.DEL_FLG=0 AND b.DEL_FLG=0; exit
三、来看看效果
当然中间出现了许多bug,不过慢慢修改吗,兵来将挡,水来土掩,bug来了自己调么
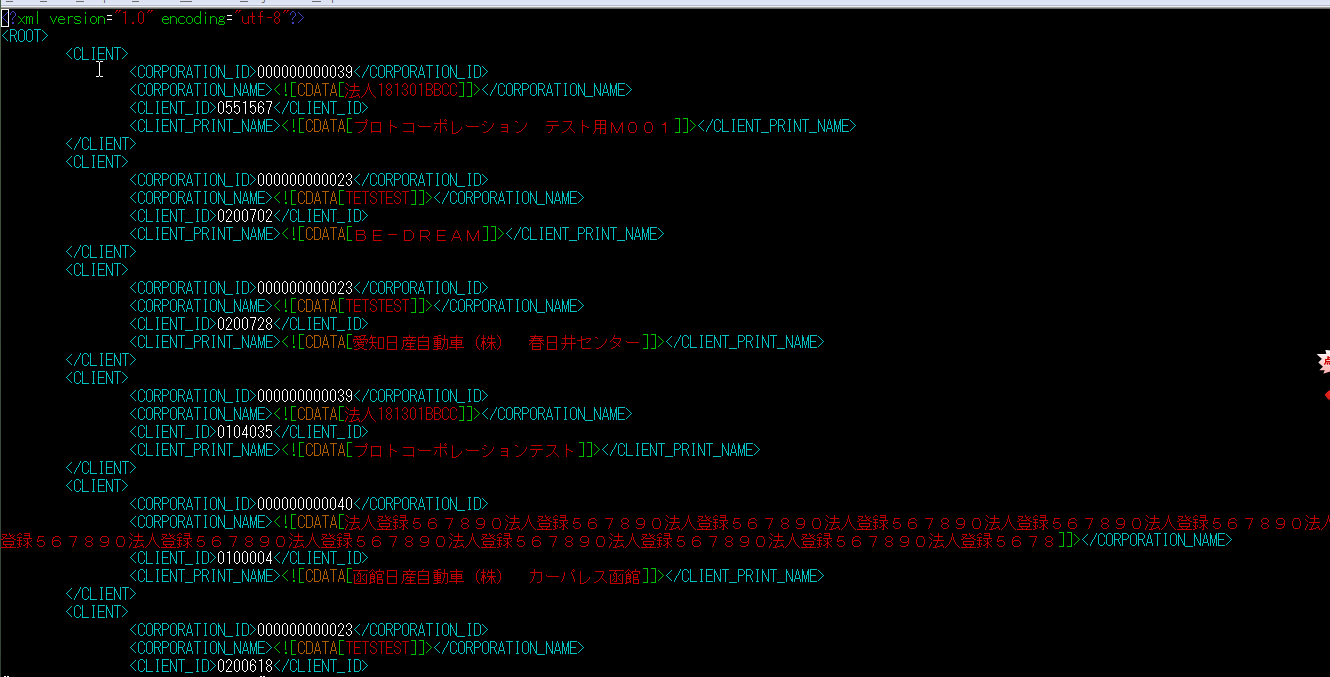
就这样简单的整理一下,可能光这么写不够完整,但是,中间设计的知识也很多,不能展开了说,做个分享,大家有用到的时候也是个思路,具体的某些知识点可以用到了再去找资料了。

- 本文固定链接: https://zxbcw.cn/post/3116/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)