
标识(ID / Identifier)是无处不在的,生成标识的主体是人,那么它就是一个命名过程,如果是计算机,那么它就是一个生成过程。如何保证分布式系统下,并行生成标识的唯一与标识的命名空间有着密不可分的关系。在世界里,「潜意识下的命名空间里,相对的唯一标识」是普遍存在的,例如:
-
每个人出生的时候,就获得了一个「相对的唯一标识」——姓名。
-
城市的道路,都基本上采用了唯一的命名(当然这也需要一个 过程 )。
显然,对于每个标识,都需要有一个命名空间(namespace),来保证其相对唯一性。
可以说,在人的意识里,对于的实体的描述是基于名字进行的,人们并不希望同名的出现太多,这会在沟通过程中的产生理解困难。
对于人来说,在家庭里会有小名,在社会中会有正式名字,在社交过程中还会产生绰号。
在中国,对于企业来说,除了企业有名称之外,还有组织机构代码证、有税务登记证、有工商营业执照,并分别对应三个编号。(当然,目前五证合一也在进行中)。
回到计算机领域,围绕主机在网络上的地址,在不同的命名空间中,都会存在一个「相对的唯一标识」用来描述一个实体:
-
每个以太网网卡,都有一个48-bit 的MAC地址
-
每个MAC地址,可能有一个或者多个IP地址
-
每个网卡,都可能有一个或者多个IP地址
-
每个IP地址,都可能有多个域名
-
当然,每个主机,都会有一个主机名
接续上面的例子,事实上,MAC地址是由 IEEE Standards Association Registration Authority 完成地址段的分配。
对于目前的 1530 个顶级根域(gTLD),以及 IPv4 / IPv6 地址,都由IANA对其进行管理。
上面我通过类比的方式简单介绍了标识,总结来说它是无处不在的。我们在理解技术里的ID的同时,一定要联系生活中的场景,对比着琢磨和分析。
-
标识是从一个典型的场景,对客观事物进行统一编码的过程。
-
采用 半集中与半自主相结合 的方法,是一种实现「分而治之」十分普遍和有效的设计模式。
-
标识的唯一性是根据命名空间紧密相关的。
标识的使用
在不同命名空间中实现标识的转换
在中国,对于人名,通常是由公安局出入境管理局完成中文至英文的翻译,同时,他们会把翻译结果写到数据库中,印到护照上。 这中间的翻译规则,通常是根据中文与汉语拼音、汉语拼音与英文字母的两次转换关系完成的。
对于计算机网络,则会有 NAT完成IP地址间的转换,RAP/RARP完成IP地址与MAC地址的双向转换,DNS完成域名至IP地址的转换。
可是,为什么需要那么多不同命名空间的标识标识一个实体?可能最直观的回答通常是这样:
-
域名为了方便人的记忆与使用
-
IP地址是为了更广范围的计算机互联
-
MAC则是为了在物理上保证唯一
-
OSI开放系统互联7层模型决定的
人们会在不同的领域(也是命名空间)中定义自己的命名规范,这可以认为是领域主权的体现,同时伴生的会是一套与相关领域标识的转换协议。
结构化与别名效应
结构化是把数据的元信息以位置的方式固化是数据中。也就是说,代表某个意义的信息,一定会出现在一个约定好的位置上。
由于标识是被人经常使用的,那么在使用过程中会对大脑形成一定的训练。
人在看到了010-XXXXXXXX,021-XXXXXXXX号码之后,自然而言会产生条件反射,认为两者分别代表了北京和上海;同样的人在看到了139和186之后,分别产生了中国移动以及中国联通的运营商联想。
对于使用者,这种场景,数字类似是一个名称别名。对于程序员,这十分接近「数据字典」的设计模式。
标识转换过程的两面性
别名和正名,同样是来自于两个不同命名空间的标识,之间自然而然的会进行转换。
当然,人们也不会忘记去Hack这些转换协议的设计。
一些是有益的,是实现了更为便利的应用场景。例如:将不同的域名指向相同的IP地址(使用A或者CNAME记录),并结合相关软硬件实现「虚拟主机」,达到资源复用的目的。
一些却是有害的,例如,诈骗电话也经常采用改号的方法,让接听者误以为那是来自某个官方的外呼电话。
同样的,在计算机领域,一样有DNS劫持、DNS污染。
有矛就有盾,进行安全性扩展的 DNSSEC 就是为了对DNS结果,验证不存在性和校验数据完整性验证,不过依然没有实现全面部署。
小结
-
在关注如何生成标识的同时,还需要关注标识的易用性和直观性
不同命名空间的标识,在互通时需要进行转换
-
转换的过程,可能是一个简单的规则,也可能是一个独立第三方服务
-
标识的唯一性是基本诉求,同时嵌入其他维度的信息是减少实时关联查询的有效手段
思路一:基于数据库生成
标识的生成方法有很多,有集中式的,分布式的;有后端的,前端的,当然还有人工的。 并没有一种通用的生成方法来适应各种应用场景。
人工生成的确是一种方式,比如电子邮箱,微信ID,各种论坛的账号。在人想出标识的那一刻,是无法判断是否是唯一的,对这种生成方式的结果,显然在录入时都需要进行唯一性校验。所以,下面描述的几种生成方式,是在生成的那一刻就在一个命名空间内唯一,而不再需要进行唯一性校验。
而基于数据库生成,一般包含以下几种:
-
MySQL(5.6) AUTO_INCREMENT 特性
-
Postgres(REL 9.6 Stable) SEQUENCE 特性
-
Oracle 数据库的 SEQUENCE 特性,有知道这一特性如何实现的,可以在 知乎 做一下解答。
-
Flickr Ticket Servers ,同时支持Sharding (文章发表于2010年2月8日,算法上线于2006年1月13日)。
一般地,这种类型的生成方案,都可以设置其实初始值,以及增量步长。
思路二:基于分布式集群协调器生成
在不使用数据库的情况下,通过一个后台服务对外提供高可用的、固定步长标识生成,则需要分布式的集群协调器进行。
一般的,主流协调器有两类:
-
以强一致性为目标的:ZooKeeper为代表
-
以最终一致性为目标的:Consul为代表
ZooKeeper的强一致性,是由Paxos协议保证的;Consul的最终一致性,是由Gossip协议保证的。
在步长累计型生成算法中,最核心的就是保持一个累计值在整个集群中的「强一致性」。同时,这也会为唯一性标识的生成带来新的形成瓶颈。
思路三:划分命名空间并行生成
似乎对于分布式的ID生成,以Twitter Snowflake为代表的, Flake 系列算法,经常可以被搜索引擎找到,但似乎MongoDB的ObjectId算法,更早地采用了这种思路。MongoDB 1.0 是在2009年8月27日 发布 的,并且0.9.10(2009年8月24日发布)和1.0两个版本没有差异。
在StackOverflow上,最早的一个关于ObjectId的问题( http://stackoverflow.com/questions/2138687/whats-mongodb-hashs-size/2146071 ),时间是2010年1月27日。不知道Twitter的同学,是不是受此启发呢?
MongoDB ObjectId
12-byte MongoDB ObjectId 的结构是:
-
a 4-byte value representing the seconds since the Unix epoch,
-
a 3-byte machine identifier,
-
a 2-byte process id, and
-
a 3-byte counter, starting with a random value.
可以看出,这个方案所支持的最小划分粒度是「秒 * 进程实例」,单进程实例的每秒容量是 3-byte (24-bit),也就是接近16777216个ID。
有兴趣的,还可以进一步 看代码(MonogoDB 3.3.x Java Driver) 研究:Timestamp, Machine Identifier、Process Identifier、计数器的初始值分别是如何获得的:
1. Timestamp

2. Machine Identifier
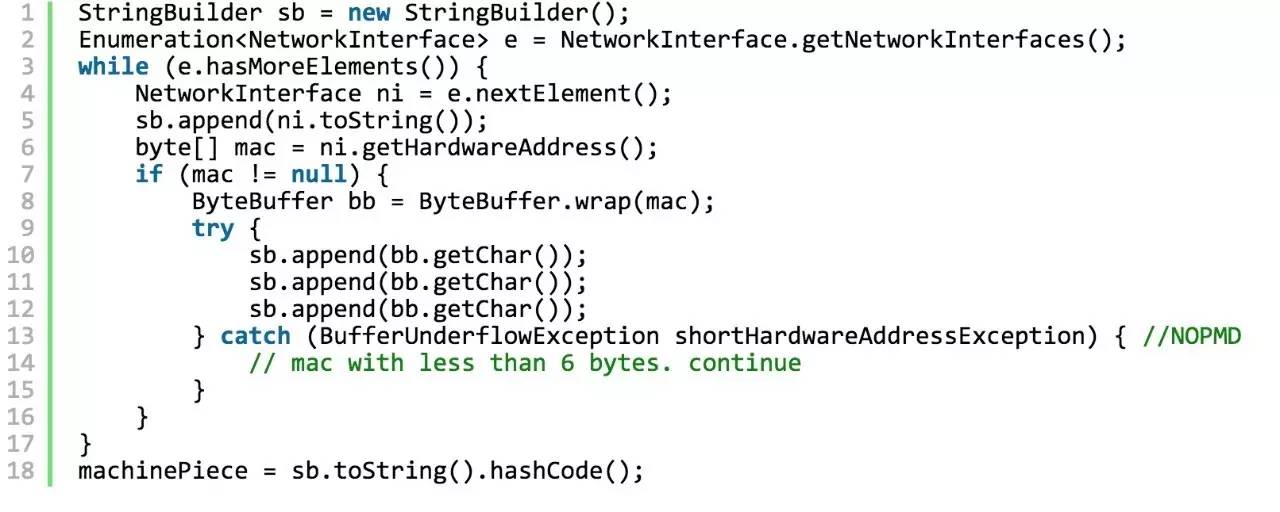
3. Process ID
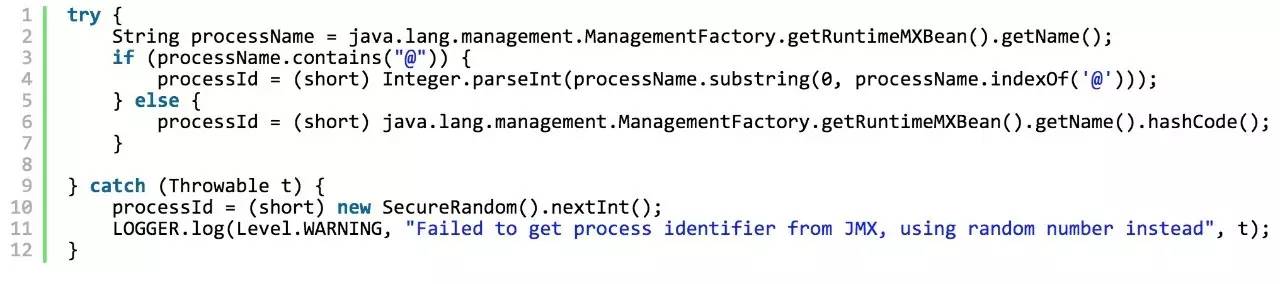
4. COUNTER
此处需要注意的是MongoDB的 NEXT_COUNTER 其初始值是一个随机数,这是有利于分库分表的。因为在小并发的条件下,非随机数的初始值,容易产生 偏库偏表, 不均匀的现象。
Twitter Snowflake
Twitter在2010年6月1日(在Flickr那篇文章发布不到4个月之后),Ryan King 在Twitter的Blog 撰文 写道:
-
Ticket Servers方案缺乏顺序的保证
-
考虑过采用UUID,不过128-bit太长了
-
也考虑过采用ZooKeeper所提供的 *Unique Naming* Seuence Nodes 所提供的 Unique Naming 特性,但是性能不能满足。(个人认为,Sequence Nodes的设计目标是解决分布式锁的问题,但不解决性能要求极高的ID生成问题,直接应用是一种Hack行为)
在这种情况下,Twitter给出了 64-bit 长的 Snowflake ,它的结构是:
-
1-bit reserved
-
41-bit timestamp
-
10-bit machine id
-
12-bit sequence
在过了不到4年,2014年的5月31日,Twitter 更新了 Snowflake 的 README,其中陈述了两个容易被忽视的事实:
-
"We have retired the initial release of Snowflake ..."
-
"... heavily relies on existing infrastructure at Twitter to run. "
可以看出,这个方案所支持的最小划分粒度是「毫秒 * 线程」,单线程(Snowflake 里对应的概念是 Worker)的每秒容量是12-bit,也就是接近4096。
翻一下Snowflake的 归档代码 (Scala),可以看到:
1. 关于初始化Sequence的处理

可以看到此处Snowflake对于 sequence 的赋值为0。
2. 关于每秒超过4096个ID生成请求的处理
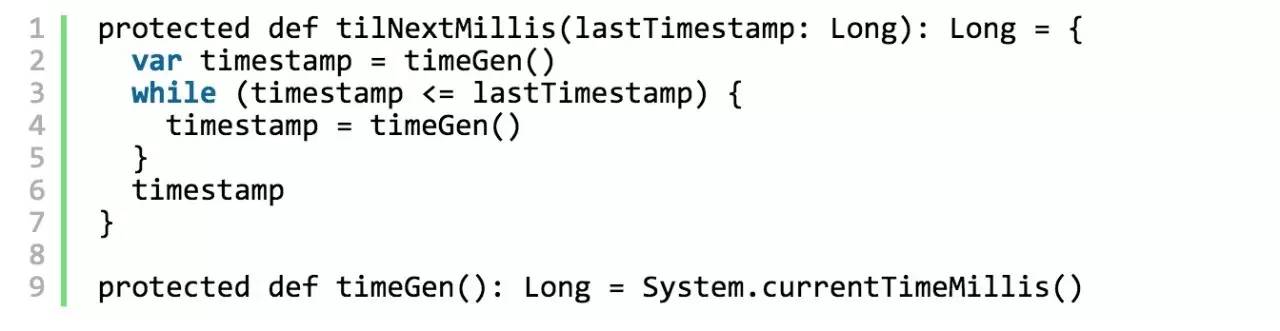
noeqd
2011年11月23日,用Go语言实现的,基于Snowflake的 neoqd 出现了。
它的特点是,除了使用Go语言进行了实现,更是把ID生成做成了一个网络服务。支持客户端向ID生成服务申请ID。它还支持:
-
简单预共享Token的客户端身份证认证(只是加强了那么一点点的安全性,可以忽略)
-
支持批量获取ID,最多256个(因为使用一个byte表示申请个数)
同时,作者还建议使用 Doozerd 一个用Go语言写的 -- a highly-available, completely consistent store for small amounts of extremely important data. 进行Machine ID的分配。
(关于 ZooKeeper / Etcd / Consul / Doozerd 的比较,也是可以期待下)
Boundary Flake
2012年1月, Boundary Flake 同样的,用Erlang语言把Snowflake,变成了一个网络服务,提供128-bit长的ID生成服务。
不过,根据其RoadMap的描述,这个项目并没100%完成。例如,批量的ID生成,HTTP 接口,客户端Library都列在里面待实现。
CruftFlake
2012年7月, CruftFlake 更显然的,是想以一个PHP变种身份出现。
它在结构上与Snowflake基本一致,存在两个区别:
-
在timestamp上的取值略有区别
-
可以自行决定是否采用ZooKeeper作为协调器
基于LableOrg/java-uniqueid
2014年7月18日,LableOrg 写了一个通过ZooKeeper进行协调的,128-bit长的算法 java-uniqueid。其 结构组成 依然十分相似:
-
Timestamp
-
Sequence counter
-
Generator IDs
-
Cluster IDs
前台浏览器生成
这里的前台,主要是指以「浏览器」为代表的客户端。
2015年2月16日,Sudhanshu Yadav (看面相像印度人),用Javascript写了Flake的又一个变种实现 FlakeId 。其核心代码是:

它的Machine Identifier则是作为构造函数的选项参数 options.mid 传入。

没思路,全自主随机生成?
选择UUID?
可以说,成熟的、全自主生成方案,可能只有 128-bit UUID 一种,具体的说,是UUID Version 4。另外,微软对它实现,称之为 GUID 。
一般的,使用的最多的是UUID Version 4,很大程度上是因为其依赖的其他服务最少。
这里,通过python (2.5+) 对UUID的实现,体验一下UUID的生成效果:
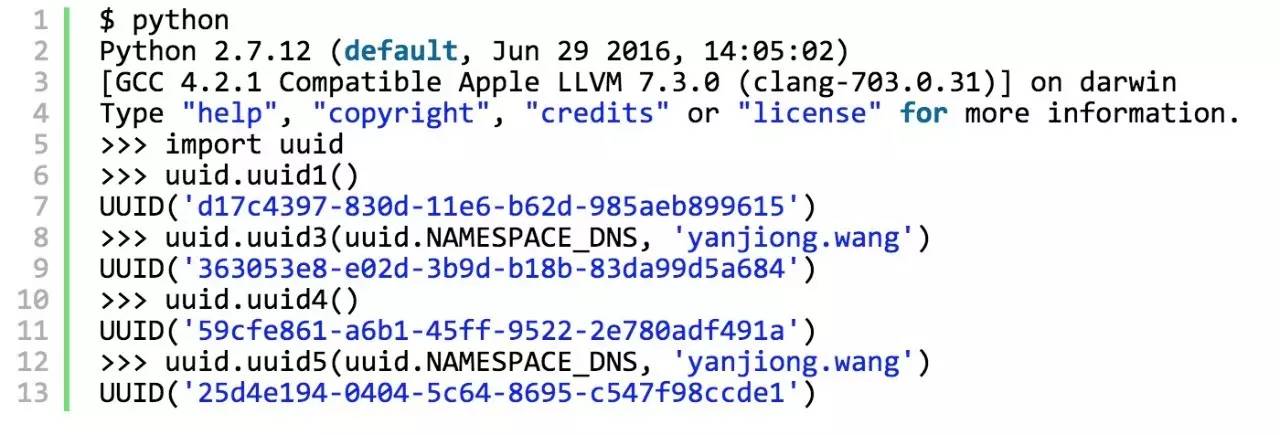
另外,我们看一下网卡的MAC地址:
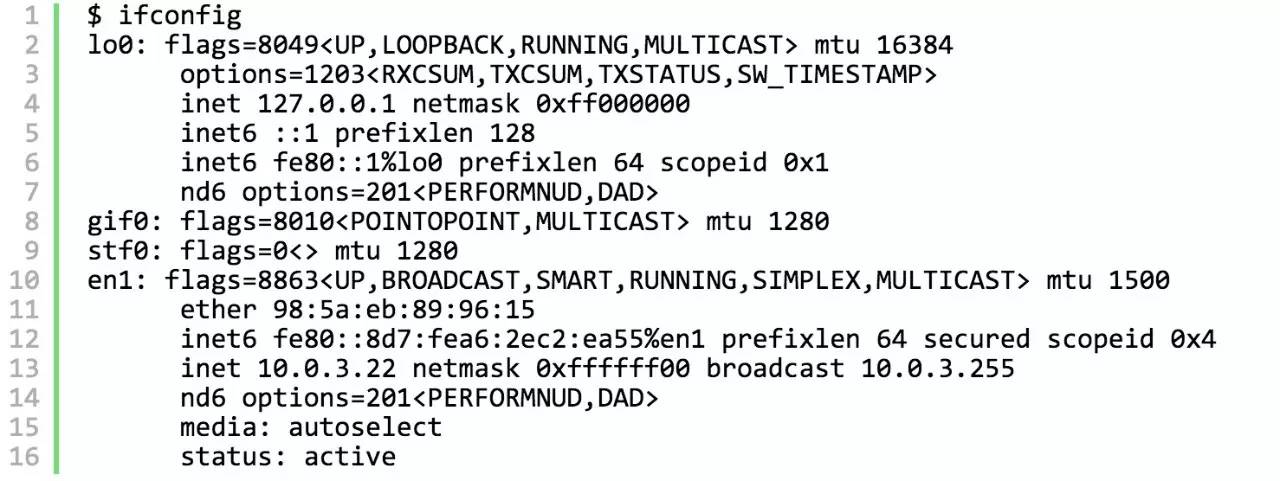
(因为UUID Version 1会泄露网卡的MAC地址,所以我对MAC地址做了下小手术)
可以看到UUID Version 1 最后一组数值 985aeb899615 与网卡的 MAC地址是一样一样的 98:5a:eb:89:96:15。
个人一直认为,采用UUID Version 4是一种偷懒的,没有针对具体应用场景,缺乏必要设计的做法。
一方面,它是依据概率确保无碰撞的,计算的过程与概率上的「生日问题」是一样的,不再展开。
另一方面,从使用的角度,UUID还有以下缺点:
-
太长,即便是转换成36个字符,不利于输入
-
过于随机,没有规律,在开发调试、线上故障定位,都容易看花眼。
-
如果作为数据库主键,对索引不利。
基于Hash算法?
众多的Hash算法,例如「MD5 / SHA-1 / SHA-2 / SHA-3」,都看可以对内容进行摘要计算,形成一个定长的Hash值。
这些Hash算法,都会存在一个Hash冲突的问题,以及碰撞攻击的问题。
以UUID类似,其文本化之后的随机特征,不太适合应用在ID生成方面。
标识生成总结
-
人工生成的标识,在相同的命名空间里,需要后续唯一性验证才能保证唯一
-
由计算机生成,在低并发的场景下,适合通过一个服务集中生成,并保障此服务的高可用性
-
由计算机生成,在高并发的场景下,适合通过一个保障命名空间独立的命名规范下,由多个服务并行生成。
-
采用步长和增长相结合的生成算法,本质上都是对某个状态进行累积的结果。
-
对于取模进行分库分表的场景,初始化值随机有利于均匀分布。
-
(MongoDB 的 ObjectId 更是Flake系列算法的鼻祖,并在初始值上进行了随机化处理)
设计一个「合适」的标识
1. 区分实体和关系
实体是点,而关系是线。
一般而言,面向实体的标识生成速度,要小于面向关系的生成速度。
具体的例子,以电商为例:买家、卖家、商品这些实体的录入速度,要远比订单生成小的多。也因此,主数据要比交易数据稳定的多。
并且,关系还可能包含层次关系,进而体现为一个依赖树。
面向实体的标识
面向实体的标识,更多的与概念相关(名称)、与形态相关(型号),有很多的人为因素参与,随机因素有限,命名的主体也来自于人。
对于实体制造,为任意一个产品进行标识,大致会分为六个方面:品牌、品类、品名,型号、批号、产品序列号。
对于前四者,更多的是人为的进行命名。例如,给定中文,找到对应英文,再进行缩写。
对于批号,则会增加一些时间因素,以关联到产品的生产时间。例如,采用20160925表示具体某一天,或者采用201640表示具体某一周。(一般来说,同一个批号的产品,所使用的原材料是也是同一批。)
对于产品序列号,最简单的是采用自然数法进行编号。
这一类的标识,在分布式系统下,在系统并发量小,集群规模小的情况下,可以采用基于数据库或者协调器的生成方案。
面向关系的标识
自然的,关系源于两个或两个以上的实体之间所进行的某一个活动,并且具有一定的时效性。
常见的关系的表现形式有:交易流水号,会话标识等等。
这一类的标识,在分布式系统下,在系统并发量大,应当采用基于服务的内置生成方案。唯一依赖的是在实例部署时、启动前,为期分配唯一的Machine Identifier。这个Machine Identifier可以交由以强一致性保证的协调器完成。
当然,在系统并发量小的情况下,任然可以采用基于数据库的生成方案,因为没有协调器集群的参与,系统整体的复杂度更低,更利于维护。
2. 标识的容量
任何采用文字所表达的标识,最终在计算机里,都会根据一定的格式,被转换为字节byte进行处理,这个过程称之为「序列化」。 这种序列化方式,本质上是一种编码方式。
变长编码
一般来说,采用变长的编码方式,主要的目的是为了应对不可预期大小的信息量。
常见的有 TLV(Type-Length-Value) 方式。 Google的 Protocol Buffers 非常有意思地采用了 Base 128 Varints 的编码方式。
本质上,一个 URI 也是一个变长标识,它可以标识一个功能,也可以标识一个虚拟实体。
RESTful是对此类命名方式的一种实践方式,也是对 URI和HTTP协议组合之后,「表征力」的一个深入挖掘。
定长编码
在回顾一下前文所提到的IPv4地址,它似乎、可能、或许会在2019年 完全枯竭, 因为它只有32-bit。相比之下,MAC地址有48-bit,IPv6有128-bit。即便是它们都没那么容易枯竭,但也不代表由于人为因素,导致无法有效使用。
再回想下,每个人的身份证、手机号码,都是采用定长的形式进行编码。
选择定长有利于预先分配计算机资源,不管是内存、文件系统,还是数据库。同时,对于人的心理来说,可预期性大大增强了。
标识的命名空间
命名空间有三个层面:
-
异构切分:对于不同的场景和视角,以树形进行层次划分。
-
同构切分:对于异构切分的结果,切分出不同的分片。
-
时间切分:对于同一个分片,在不同时间点上的状态。
一般地:
-
首先,采用并行无状态的生成算法,一般都采用时间作为首要的命名空间,并且此命名空间的实效性小于生成者的重启时间
-
其次,采用生成器实例自身的标识作为次要命名空间,以保证各个生成器的时间即便是不同步也不会产生重复标识
同时,需要注意的是,这可能导致唯一标识产生,大段跳跃,原因有:
-
单位时间的并发量远小于子命名空间的容量
-
生成器重启
-
标识的冗余
不管标识是在运行时的内存出现,还是记录到数据库中或者文件里,它都需要占用硬件资源。
还是拿身份证举例,一方面,一个18个字符长度的身份证,那么需要18个字节进行存储。18个字节意味着144-bit,比IPv6的128bit还长。
如果简单的标识全世界每个人,以目前全地球超过70亿人口的总量,那么33个bit就足够了。
采用这种冗余设计的原因,一方面是「半集中,半自主」和现实的行政、地域结构对齐,另一方面是实现关联信息的集成。
小结
-
标识编码后的长度,则决定了一个标识方案的整体容量。
-
在一个统一的命名空间内,有多个标识生成者并行生成时,需要划分独立的子命名空间,以保证生成的标识在整个命名空间内唯一。
-
单个命名空间的标识,承载的信息量有限,在标识的使用过程中,需要扩展与包含一些其他视角的信息以进行冗余。
3. 标识的文本兼容
和人工取名字不一样,自动生成ID的主体,是计算机本身,但使用这个ID的主体,有两个:人和计算机。
对于计算机,最擅长处理的是结构化数组、条形码或者二维码;而对人,最擅长使用的是文本、图形或者视频。
一般而言,在大量的RESTful设计的应用,其URI中会包含大量的ID,用来标识用户、商品、订单等等,它们经常会出现在URI中。
以ASCII编码为基础的各种文本化编码算法,从Base16开始,正常的有Base32,Base64,Base58,Base85等等。
其中,Base16是最为「字节友好」的,因为不需要进行任何Padding操作,就可以以把 4-bit/half-byte 转换为 [0-9a-f] 这十六个字符,因此Base16还有别名:Hex。另外对于键盘输入,这16个英文字母,又是相对纯数字之外,最方便的。
而Base32, Base64等等,都需要Padding。因为Base32是每 5-bit 进行分组编码,Base64则是 6-bit ,都无法直接对齐一个 byte(8-bit)。
另外,Base16还对 URI 友好,不需要进行任何的 URLEncode/Decode操作。
以64-bit长的ID为例,它既可以转化为 long,也可以Base16成为16个字符的``HexString``,同时它大小写不敏感。
相比之下,如果采用Base64的文本化方案,其长度虽然少了5个字符,为11个,但其大小写敏感,不利于人机交互的输入,还会包含URI不友好,还会被转义为「 %3D」的符号「=」。
一个精巧的标识文本化算法,并不应该简单的把一个二进制值转为HexString。在日志里,应该有相应的解码算法,解析出符合人类阅读的字符,比如:精确到秒、且带格式时间,生成改标识的主体,等等。
4. 标识的安全性
标识的信息泄露
采用连续,或者固定步长的标识,容易从一个标识猜测其他标识的存在性。
常见的例子有:
-
通过局域网扫描工具,扫描某个子网的活动的IP地址
-
通过端口扫描工具,扫描一个目标主机开放的端口,以初步确定主机操作系统类型
另外,在物联网领域,如果采用的EPC编码,那么很容易通过连续编码,估计某个产品的具体产量。
标识的自校验能力
还是使用身份证号这个例子,根据国家标准(GB11643-1999),身份证号的前17位为本体码,最后1位为校验码。也就是说,它是通过前17位进行数学公式计算之后获得,主要目的是用于检验录入过程是否产生差错。
这样设计的好处是,每当输入完18位身份证号后,可以直接判断一个身份证号,是否在逻辑上是「合规的」,对于系统而言不用查询数据库,可以减少IO操作。不过,这不代表这个身份证号是有效的,也有可能是一个无效,但符合校验规则的身份证号。
由于标识的长度有限,能够加入的冗余信息较少,一般的基于公钥密码体制的签名机制,都难以在一个短标识中嵌入。
来自:http://mp.weixin.qq.com/s?__biz=MzA5Nzc4OTA1Mw==&mid=2659598286&idx=1&sn=3172172ccea316b0ed83429ae718b54d&

- 本文固定链接: https://zxbcw.cn/post/5391/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)