
前面我们主要分享了MySQL中的常见知识与使用。这里我们主要分享一下MySQL中的高阶使用,主要包括:函数、存储过程和存储引擎。
对于MySQL中的基础知识,可以参见
1 函数
函数可以返回任意类型的值,也可以接收这些类型的参数。
字符函数
| 函数名称 | 描述 |
|---|---|
| CONCAT() | 字符连接 |
| CONCAT_WS() | 使用指定的分隔符进行字符连接 |
| FORMAT() | 数字格式化 |
| LOWER() | 转换成小写字母 |
| UPPER() | 转换成大写字母 |
| LEFT() | 获取左侧字符 |
| RIGHT() | 获取右侧字符 |
| LENGTH() | 获取字符串长度 |
| LTRIM() | 删除前导空格 |
| RTRIM() | 删除后续空格 |
| TRIM() | 删除前导和后续空格 |
| SUBSTRING() | 字符串截取 |
| [NOT] LIKE | 模式匹配 |
| REPLACE() | 字符串替换 |
函数可以嵌套使用。
% (百分号):代表任意个字符。
_ (下划线):代表任意一个字符。
# 删除前导'?'符号
SELECT TRIM(LEADING '?' FROM '??MySQL???');
# 删除后续'?'符号
SELECT TRIM(TRAILING '?' FROM '??MySQL???');
# 删除前后'?'符号
SELECT TRIM(BOTH '?' FROM '??My??SQL???');
# 将'?'符号替换成'!'符号
SELECT REPLACE('??My??SQL???', '?', '!');
# 从中'MySQL'第1个开始,截取2个字符
SELECT SUBSTRING('MySQL', 1, 2);
# 从中'MySQL'截取最后1个字符
SELECT SUBSTRING('MySQL', -1);
# 从中'MySQL'第2个开始,截取至结尾
SELECT SUBSTRING('MySQL', 2);
数值运算符函数
| 函数名称 | 描述 |
|---|---|
| CEIL() | 进一取整 |
| DIV | 整数除法 |
| FLOOR() | 舍一取整 |
| MOD | 取余数(取模) |
| POWER() | 幂运算 |
| ROUND() | 四舍五入 |
| TRUNCATE() | 数字截取 |
比较运算符函数
| 函数名称 | 描述 |
|---|---|
| [NOT]BETWEEN…AND.. | [不]在范围之内 |
| [NOT]IN() | [不]在列出值范围内 |
| IS[NOT]NULL | [不]为空 |
日期时间函数
| 函数名称 | 描述 |
|---|---|
| NOW() | 当前日期和时间 |
| CURDATE() | 当前日期 |
| CURTIME() | 当前时间 |
| DATE_ADD() | 日期变化 |
| DATEDIFF() | 日期差值 |
| DATE_FORMAT() | 日期格式化 |
# 时间增加1年
SELECT DATE_ADD('2016-05-28', INTERVAL 365 DAY);
# 时间减少1年
SELECT DATE_ADD('2016-05-28', INTERVAL -365 DAY);
# 时间增加3周
SELECT DATE_ADD('2016-05-28', INTERVAL 3 WEEK);
# 日期格式化
SELECT DATE_FORMAT('2016-05-28', '%m/%d/%Y');
# 更多时间格式可以前往MySQL官网查看手册
信息函数
| 函数名称 | 描述 |
|---|---|
| CONNECTION_ID() | 连接ID |
| DATEBASE() | 当前数据库 |
| LAST_INSERT_ID() | 最后插入记录的ID号 |
| USER() | 当前用户 |
| VERSION() | 版本信息 |
聚合函数
| 函数名称 | 描述 |
|---|---|
| AVG() | 平均值 |
| COUNT() | 计数 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| SUM() | 求和 |
加密函数
| 函数名称 | 描述 |
|---|---|
| MD5() | 信息摘要算法 |
| PASSWORD() | 密码算法 |
自定义函数
用户自定义函数(user-defined function,UDF)是一种对MySQL扩展的途径,其用法与内置函数相同。UDF是对MySQL扩展的一种途径。
必要条件
- 参数:可以有零个或多个
- 返回值:只能有一个
参数和返回值没有必然的联系。
创建自定义函数
CREATE FUNCTION function_name RETURNS {STRING|INTEGER|REAL|DECIMAL} routine_body
函数体(routine_body)
- 函数体由合法的SQL语句构成;
- 函数体可以是简单的SELECT或INSERT语句;
- 函数体如果为复合结构则使用BEGIN…END语句;
- 复合结构可以包含声明,循环,控制结构。
示例
# 不带参数
CREATE FUNCTION f1() RETURNS VARCHAR(30) RETURN DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s');
# 带参数
CREATE FUNCTION f2(num1 SMALLINT UNSIGNED, num2 SMALLINT UNSIGNED) RETURNS FLOAT(10, 2) UNSIGNED RETURN (num1 + num2) / 2;
# 具有复合结构函数体
# 可能需要使用DELIMITER命令修改分隔符
CREATE FUNCTION f3(username VARCHAR(20)) RETURNS INT UNSIGNED
BEGIN
INSERT test(username) VALUES(username);
RETURN LAST_INSERT_ID();
END
2 存储过程
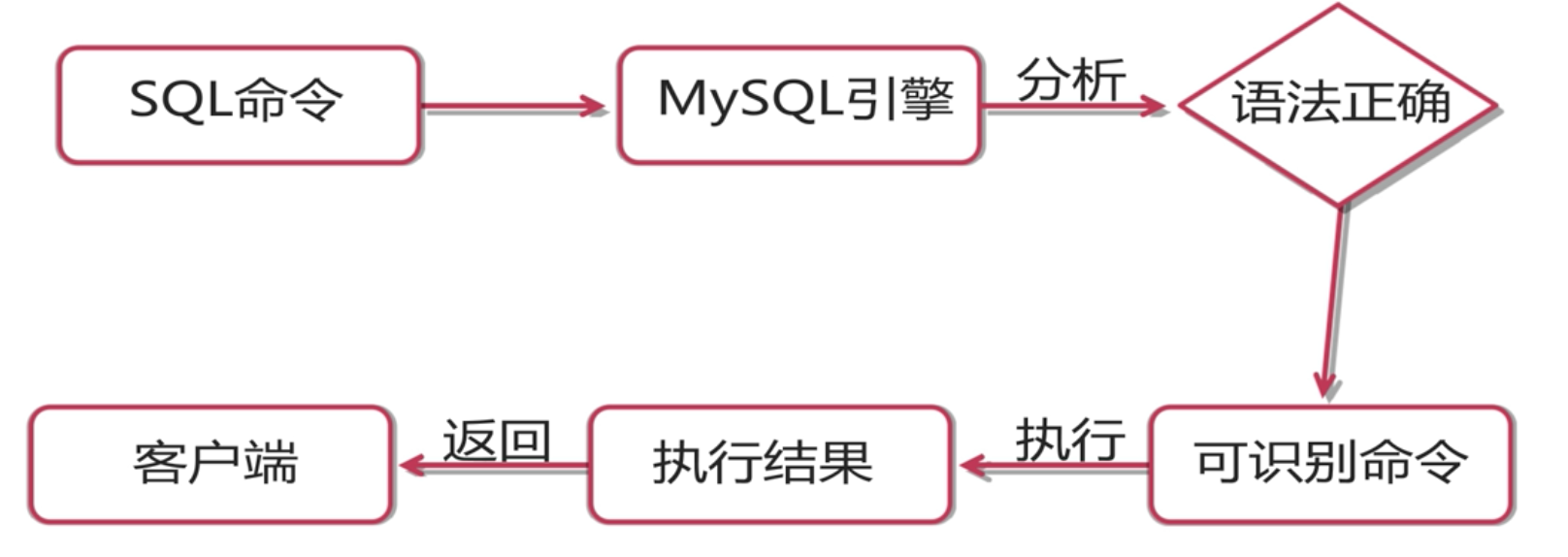 存储过程是SQL语句和控制语句的预编译集合,以一个名称存储作为一个单元处理。可以由用户调用执行,允许用户声明变量以及进行流程控制。存储过程可以接收输入类型的参数,也可以接收输出类型的参数,并可以存在多个返回值。执行效率比单一的SQL语句高。
存储过程是SQL语句和控制语句的预编译集合,以一个名称存储作为一个单元处理。可以由用户调用执行,允许用户声明变量以及进行流程控制。存储过程可以接收输入类型的参数,也可以接收输出类型的参数,并可以存在多个返回值。执行效率比单一的SQL语句高。
优点
- 增强SQL语句的功能和灵活性
在存储过程中可以写控制语句具有很强的灵活性,可以完成复杂的判断及较复杂的运算。
- 实现较快的执行速度
如果某一操作包含了大量的SQL语句,那么这些SQL语句都将被MySQL引擎执行语法分析、编译、执行,所以效率相对过低。而存储过程是预编译的,当客户端第一次调用存储过程时,MySQL的引擎将对它进行语法分析、编译等操作,然后把这个编译的结果存储到内存中,所以说第一次使用的时候效率和以前是相同的。但是以后客户端再次调用这个存储过程时,直接从内存中执行,所以说效率比较高,速度比较快。
- 减少网络流量
如果通过客户端每一个单独发送SQL语句让服务器来执行,那么通过http协议来提交的数据量相对来说较大。
创建
CREATE [DEFINER = {user|CURRENT_USER}] PROCEDURE sp_name ([proc_parameter[, ...]]) [characteristic ...] routine_body
proc_parameter :
[IN | OUT | INOUT] param_name type
参数:
IN ,表示该参数的值必须在调用存储过程时指定。
OUT ,表示该参数值可以被存储过程改变,并且可以返回。
INOUT ,表示该参数的调用时指定,并且可以被改变和返回。
特性:
COMMENT 注释
CONTAINS SQL 包含SQL语句,但不包含读或写数据的语句。
NO SQL 不包含SQL语句。
READS SQL DATA 包含读写数据的语句。
MODIFIES SQL DATA 包含写数据的语句。
SQL SECURITY {DEFINER | INVOKER} 指明谁有权限来执行。
过程体
- 过程体由合法的SQL语句构成;
- 过程体可以是任意SQL语句;
不能通过存储过程来创建数据表、数据库。可以通过存储过程对数据进行增、删、改、查和多表连接操作。 - 过程体如果为复合结构则使用BEGIN…END语句;
- 复合结构中可以包含声明、循环、控制结构。
调用
CALL sp_name ([parameter[, ...]])
CALL sp_name[()]
删除
DROP PROCEDURE [IF EXISTS] sp_name
修改
ALTER PROCEDURE sp_name [characteristic ...] COMMENT 'string'
| {CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA}
| SQL SECURITY {DEFINER | INVOKER}
存储过程与自定义函数的区别
- 存储过程实现的功能要复杂一些,而函数的针对性更强。
- 存储过程可以返回多个值,函数只能有一个返回值。
- 存储过程一般独立执行,函数可以作为其他SQL语句的组成部分来实现。
示例:
# 创建不带参数的存储过程
CREATE PROCEDURE sp1() SELECT VERSION();
# 创建带有IN类型参数的存储过程(users为数据表名)
# 参数的名字不能和数据表中的记录名字一样
CREATE PROCEDURE removeUserById(IN p_id INT UNSIGNED)
BEGIN
DELETE FROM users WHERE id = p_id;
END
# 创建带有IN和OUT类型参数的存储过程(users为数据表名)
CREATE PROCEDURE removeUserAndReturnUserNumsById(IN p_id INT UNSIGNED, OUT userNums INT UNSIGNED)
BEGIN
DELETE FROM users WHERE id = p_id;
SELECT COUNT(id) FROM users INTO userNums;
END
# 创建带有多个OUT类型参数的存储过程(users为数据表名)
CREATE PROCEDURE removeUserAndReturnInfosByAge(IN p_age SMALLINT UNSIGNED, OUT delUser SMALLINT UNSIGNED, OUT userNums SMALLINT UNSIGNED)
BEGIN
DELETE FROM users WHERE age = p_age;
SELECT ROW_COUNT INTO delUser;
SELECT COUNT(id) FROM users INTO userNums;
END
3 存储引擎
MySQL可以将数据以不同的技术存储在文件(内存)中,这种技术就称为存储引擎。
每一种存储引擎使用不同的存储机制、索引技巧、锁定水平,最终提供广泛且不同的功能。
-
锁
共享锁(读锁):在同一时间段内,多个用户可以读取同一个资源,读取过程中数据不会发生任何变化。
排他锁(写锁):在任何时候只能有一个用户写入资源,当进行写锁时会阻塞其他的读锁或者写锁操作。
-
锁颗粒
表锁:是一种开销最小的锁策略。
行锁:是一种开销最大的锁策略。
-
并发控制
当多个连接记录进行修改时保证数据的一致性和完整性。
-
事务
事务用于保证数据库的完整性。
举例:用户银行转账
用户A 转账200元 用户B
实现步骤:
1)从当前账户减掉200元(账户余额大于等于200元)。
2)在对方账户增加200元。
事务特性:
1)原子性(atomicity)
2)一致性(consistency)
3)隔离性(isolation)
4)持久性(durability)
-
外键
是保证数据一致性的策略。
-
索引
是对数据表中一列或多列的值进行排序的一种结构。
类型
MySQL主要支持以下几种引擎类型:
- MyISAM
- InnoDB
- Memory
- CSV
- Archive
各类存储引擎特点
| 特点 | MyISAM | InnoDB | Memory | Archive |
|---|---|---|---|---|
| 存储限制 | 256TB | 64TB | 有 | 无 |
| 事务安全 | - | 支持 | - | - |
| 支持索引 | 支持 | 支持 | 支持 | |
| 锁颗粒 | 表锁 | 行锁 | 表锁 | 行锁 |
| 数据压缩 | 支持 | - | - | 支持 |
| 支持外键 | - | 支持 | - | - |
CSV:实际上是由逗号分隔的数据引擎,在数据库子目录为每一个表创建一个 .csv 的文件,这是一种普通的文本文件,每一个数据行占用一个文本行。不支持索引。
BlackHole:黑洞引擎,写入的数据都会消失,一般用于做数据复制的中继。
MyISAM:适用于事务的处理不多的情况。
InnoDB:适用于事务处理比较多,需要有外键支持的情况。
索引分类:普通索引、唯一索引、全文索引、btree索引、hash索引…
修改存储引擎
- 通过修改MySQL配置文件
default-storage-engine=engine_name - 通过创建数据表命令实现
CREATE TABLE table_name(...)ENGINE=engine_name - 通过修改数据表命令实现
ALTER TABLE table_name ENGINE[=]engine_name
4 管理工具
-
phpMyAdmin
需要有PHP环境
-
Navicat
- MySQL Workbench
来自:http://chars.tech/2017/05/29/mysql-advanced-study/

- 本文固定链接: https://zxbcw.cn/post/5783/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)