
本文主要介绍了数据结构中的八大排序算法,利用Python分别将他们进行实现。

前言
八大排序,三大查找是《数据结构》当中非常基础的知识点,在这里为了复习顺带总结了一下常见的八种排序算法。
常见的八大排序算法,他们之间关系如下:
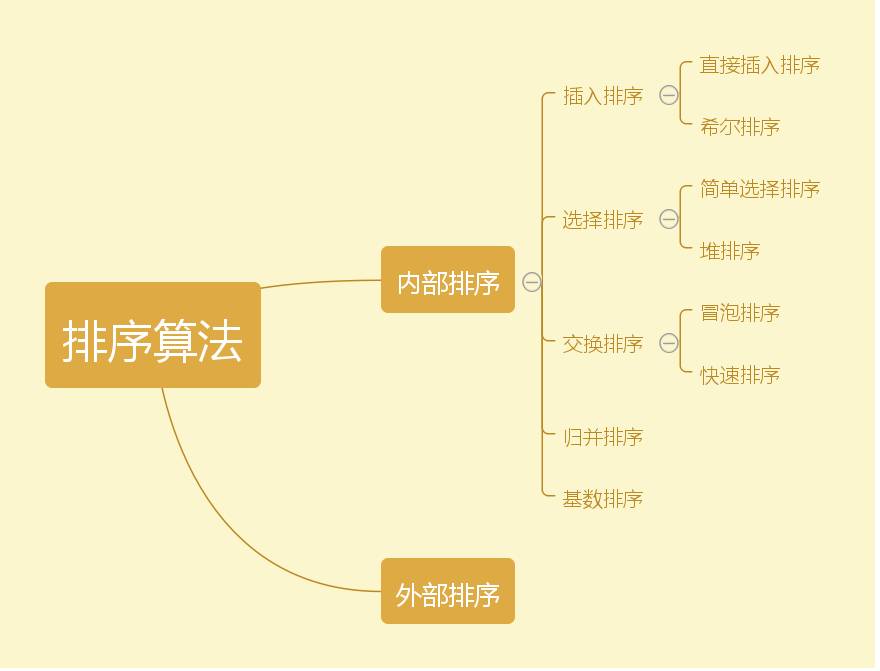
排序算法
他们的性能比较:
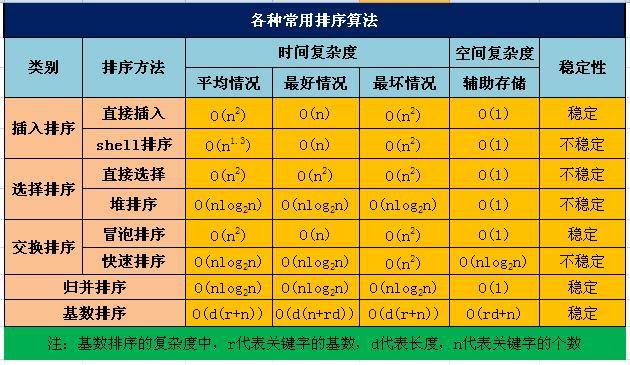
性能比较
下面,利用Python分别将他们进行实现。
直接插入排序
算法思想:
直接插入排序
直接插入排序的核心思想就是:将数组中的所有元素依次跟前面已经排好的元素相比较,如果选择的元素比已排序的元素小,则交换,直到全部元素都比较过。
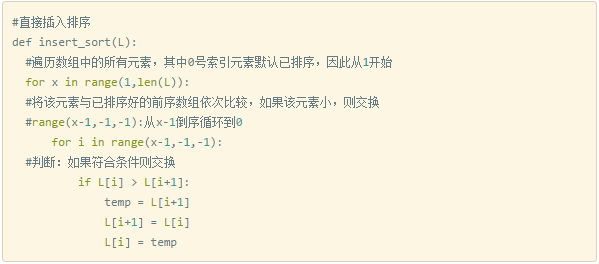
因此,从上面的描述中我们可以发现,直接插入排序可以用两个循环完成:
第一层循环:遍历待比较的所有数组元素
第二层循环:将本轮选择的元素(selected)与已经排好序的元素(ordered)相比较。如果:selected > ordered,那么将二者交换
代码实现:
希尔排序
算法思想:
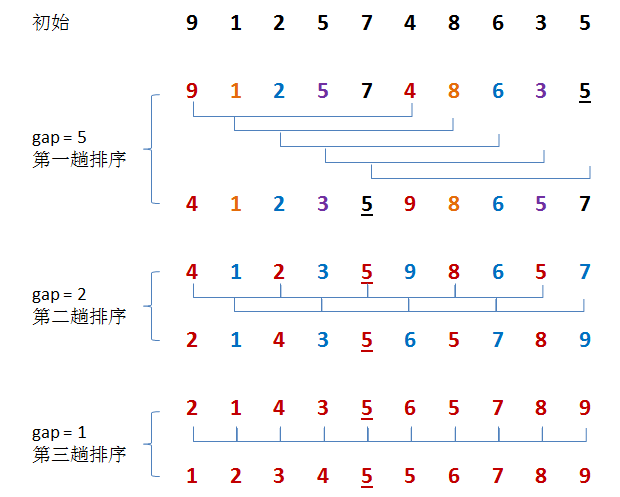
希尔排序
希尔排序的算法思想:将待排序数组按照步长gap进行分组,然后将每组的元素利用直接插入排序的方法进行排序;每次将gap折半减小,循环上述操作;当gap=1时,利用直接插入,完成排序。
同样的:从上面的描述中我们可以发现:希尔排序的总体实现应该由三个循环完成:
第一层循环:将gap依次折半,对序列进行分组,直到gap=1
第二、三层循环:也即直接插入排序所需要的两次循环。具体描述见上。
代码实现:

简单选择排序
算法思想:

简单选择排序
简单选择排序的基本思想:比较+交换。
从待排序序列中,找到关键字最小的元素;
如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
从余下的 N - 1 个元素中,找出关键字最小的元素,重复(1)、(2)步,直到排序结束。
因此我们可以发现,简单选择排序也是通过两层循环实现。
第一层循环:依次遍历序列当中的每一个元素
第二层循环:将遍历得到的当前元素依次与余下的元素进行比较,符合最小元素的条件,则交换。
代码实现:

堆排序
堆的概念:
堆:本质是一种数组对象。特别重要的一点性质:任意的叶子节点小于(或大于)它所有的父节点。对此,又分为大顶堆和小顶堆,大顶堆要求节点的元素都要大于其孩子,小顶堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求。
利用堆排序,就是基于大顶堆或者小顶堆的一种排序方法。下面,我们通过大顶堆来实现。
基本思想:
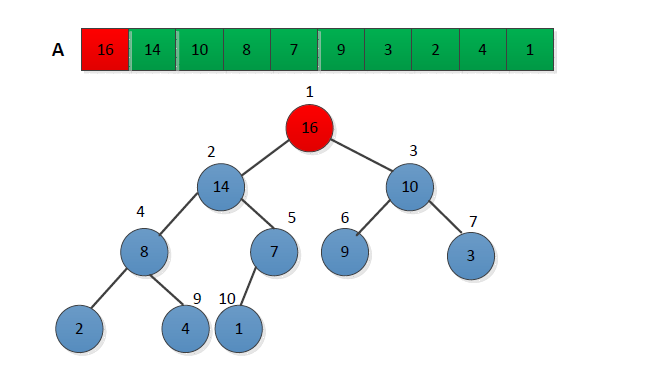
堆排序可以按照以下步骤来完成:
首先将序列构建称为大顶堆(这样满足了大顶堆那条性质:位于根节点的元素一定是当前序列的最大值);
构建大顶堆
取出当前大顶堆的根节点,将其与序列末尾元素进行交换(此时:序列末尾的元素为已排序的最大值;由于交换了元素,当前位于根节点的堆并不一定满足大顶堆的性质);
对交换后的n-1个序列元素进行调整,使其满足大顶堆的性质;
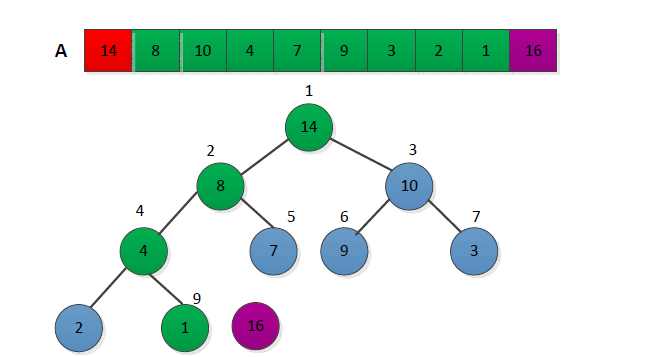
重复2.3步骤,直至堆中只有1个元素为止。
代码实现:

冒泡排序
算法思想:

冒泡排序
冒泡排序思路比较简单:
将序列当中的左右元素,依次比较,保证右边的元素始终大于左边的元素( 第一轮结束后,序列最后一个元素一定是当前序列的最大值);
对序列当中剩下的n-1个元素再次执行步骤1。
对于长度为n的序列,一共需要执行n-1轮比较(利用while循环可以减少执行次数)。
代码实现:

快速排序
算法思想:
快速排序
快速排序的基本思想:挖坑填数+分治法
从序列当中选择一个基准数(pivot),在这里我们选择序列当中第一个数最为基准数;
将序列当中的所有数依次遍历,比基准数大的位于其右侧,比基准数小的位于其左侧;
重复步骤1.2,直到所有子集当中只有一个元素为止。用伪代码描述如下:
i =L; j = R; 将基准数挖出形成第一个坑a[i]。
j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
再重复执行2,3二步,直到i==j,将基准数填入a[i]中
代码实现:

归并排序
算法思想:

归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个典型的应用。它的基本操作是:将已有的子序列合并,达到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
归并排序其实要做两件事:
分解:将序列每次折半拆分
合并:将划分后的序列段两两排序合并
因此,归并排序实际上就是两个操作,拆分+合并
如何合并?
L[first...mid]为第一段,L[mid+1...last]为第二段,并且两端已经有序,现在我们要将两端合成达到L[first...last]并且也有序。
首先依次从第一段与第二段中取出元素比较,将较小的元素赋值给temp[]
重复执行上一步,当某一段赋值结束,则将另一段剩下的元素赋值给temp[]
此时将temp[]中的元素复制给L[],则得到的L[first...last]有序
如何分解?
在这里,我们采用递归的方法,首先将待排序列分成A,B两组;然后重复对A、B序列分组;直到分组后组内只有一个元素,此时我们认为组内所有元素有序,则分组结束。
代码实现:

基数排序
算法思想:

基数排序
基数排序:通过序列中各个元素的值,对排序的N个元素进行若干趟的“分配”与“收集”来实现排序。
分配:我们将L[i]中的元素取出,首先确定其个位上的数字,根据该数字分配到与之序号相同的桶中
收集:当序列中所有的元素都分配到对应的桶中,再按照顺序依次将桶中的元素收集形成新的一个待排序列L[ ]
对新形成的序列L[]重复执行分配和收集元素中的十位、百位...直到分配完该序列中的最高位,则排序结束。
根据上述“基数排序”的展示,我们可以清楚的看到整个实现的过程。
代码实现:

后记
写完之后运行了一下时间比较:
1w个数据时:

10w个数据时:
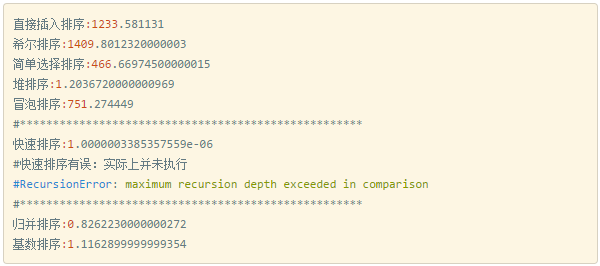
从运行结果上来看,堆排序、归并排序、基数排序真的快。
对于快速排序迭代深度超过的问题,可以将考虑将快排通过非递归的方式进行实现。
来自:http://www.uml.org.cn/python/201712121.asp

- 本文固定链接: https://zxbcw.cn/post/5880/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)