
京东弹性数据库不是一个单一的产品,而是京东在对数据库的使用、运维和开发过程中遇到的一系列问题的解决方案,和运维经验的总结升华进而形成的一套产品系列,主要包括三大功能模块:
- 核心功能模块:JED,提供数据查询和写入的自动路由、自动弹性伸缩、自动FailOver、自动负载调度和数据库服务智能自治的功能。
- 实时数据发布与订阅模块: BinLake,完全自助、无状态、自动负载、完全自治、可横向扩展的集群化Binlog采集和订阅服务。
- 自动化运维模块:DBS,实现了京东线上所有数据库服务申请、DDL/DML上线、数据抽取等的流程化和自动化。
分享大纲:
1、发展历程
2、功能特性
3、整体架构
4、实现细节
5、使用情况
一、发展历程
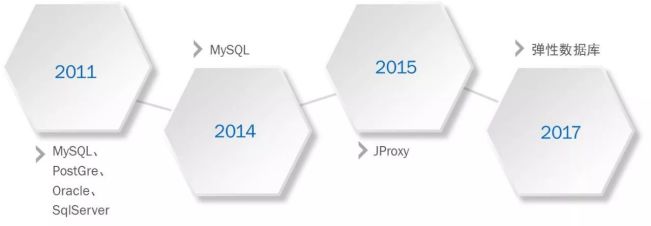
在我2011年加入京东之初,京东的数据库正是处于诸侯混战的阶段,各种数据库都有,包括:MySQL、PostGre、Oracle、SQL Sever,在2011年之后,开始去IOE,到了2014年,京东基本上完成了去IOE,所有的业务系统都迁移到了MySQL上。
在大规模使用MySQL的过程中,我们发现,随着业务数据量的增长,很多业务开始了漫长的分库、分表之旅,起初各个业务系统在自己的业务代码中维护分库分表的路由规则,而且各个业务系统的路由规则和整体设计都不一样,后来由于人员更迭以至于业务代码无法维护,不同业务使用的数据库分库分表模式不尽相同,导致数据库的维护工作也难如登天。这时我们开始重新思考应该提供什么样的数据库服务,得出了以下几点:
- 统一分库分表标准
- 路由针对业务透明
- 数据库服务伸缩无感知
- 统一数据服务
- 业务研发自助申请服务
- 数据库运维工作自动化
为了实现上述功能特点,我们分为两步走:第一步是优先解决业务和运维窘境,从而争取足够的时间和技术buffer进一步完善产品,第二步是最终完美形态的产品研发。
因此,我们首先在2015年开发了JProxy,优先解决紧急的业务和运维难题:分库分表规则统一化和路由透明化。在拿到充分的时间buffer后,我们从2016年开始以匠人的精神精雕细琢京东弹性数据库。
二、功能特性
如前面所说:京东弹性数据库是一个产品系列,主要是解决数据库的运维、使用和研发过程中的问题,具备动态伸缩、高可用、查询透明路由、集群化日志服务和自动化运维等功能。
本章将就京东弹性数据库三个核心模块的功能进行详细说明。
1、JED(JD Elastic DataBase)
JED是JProxy功能的父集,它除了具备透明路由、统一分库分表标准之外,还提供了五大功能:

(1)在线动态扩容
起初某个业务可能申请了4个分库,后面随着业务的发展,数据量越来越大,可能需要扩容到 8个分库,一般的数据库中间件在扩容时,需要与业务研发部门协商一个业务低谷期停业务,然后进行扩容,扩容完毕后重新启动业务。为了解决这个问题,JED提供了在线动态扩容功能,扩容只会对业务造成秒级影响,且无需人工介入。我们现在可以触发自动扩容,设置的策略是当磁盘的使用率达到80%,就自动进行扩容。
(2)自动Failover
Master一旦出现宕机,哨兵检测系统就会第一时间检测到,会自动触发注册在哨兵检测系统中的Hook程序,Hook程序就会选择一个最新的Slave替换Master,然后更新ETCD中的元数据信息,业务方的下一次请求就会发送新的Master上。
(3)兼容MySQL协议
JED是完全兼容MySQL协议的,即通过MySQL的Client端或者标准的JDBC Driver都可以连接到JED的Gate层,然后进行查询和计算。
(4)多源数据迁移
我们基于ghost进行改造,开发了京东的数据传输和接入工具: JTransfer,实现了业务数据的动态迁移。如果以前你的业务是运行在MySQL上的,现在要迁到JED上,你不需要停止任何业务,直接启动JTransfer的数据迁移服务,就可以在后台自动完成数据的同步和迁移。迁移完毕后,JTransfer会自行比对JED上的数据与原来数据的一致性和lag计算,当数据完全一致,且lag小于5秒时,就会邮件通知业务方进行复验,复验没有问题,业务方直接将数据库连接指向到JED就可以正常提供服务了。
(5) 数据库审计
JED具有数据库审计的功能,该功能实现在Gate层,在Gate层我们会得到应用发送给JED的所有SQL,然后将SQL语句或者SQL模板发送给MQ。由于是在Gate层实现的,而Gate层与MySQL服务不在一个容器上,因此对MySQL服务不会产生任何的负面影响。
2、BinLake
BinLake只做一样工作:集群化Binlog的采集和订阅服务。BinLake之前,我们使用Canal进行binlog采集,但我们发现存在资源浪费等问题:若一个业务需要采集MySQL Binlog,并且还需要HA保证的话,我们至少需要两台服务器。那多个业务怎么办?于是我们开发了BinLake,其功能特性如下:

(1) 无状态集群化BinLog采集
BinLake是一个集群化的BinLog采集和订阅服务,并且与常规意义上的集群不一样,我们的集群是没有master节点的,而且集群中的所有工作节点都是完全平等的,这也就意味着,只要集群中的节点没有全部宕机,BinLake集群可以一直提供服务。
(2) 高可用与自动故障转移
针对于某个Mya实例的采集instance(每个instance代表一个线程)一旦挂掉,会在集群中的负载最低的工作节点上重新启动一个instance,继续从上次挂掉的Offset进行采集,不会造成Binlog的丢失和重复。
(3) 负载自动均衡
假设所有Binlog的集群有八个节点,其中有七个节点的负载比较高,当你在接入Binlog时,在没有人工介入的衡量下,整个集群会将以新接入的一个Instance采集实例,自动选择一个健康度最高的Wave服务,然后启动Binlog采集。
(4) 支持多种MQ
BinLake采集到的所有binlog的event会被封装成Message发送给MQ,目前我们支持JMQ和Kafka两种MQ产品。
(5) 支持集群横向扩容
当BinLake集群的服务能力达到了瓶颈,我们可以简单地将新的工作节点启动,只需要在新的工作节点配置文件中配置上与线上的工作节点相同的ZooKeeper路径,新的工作节点就会自动加入到已存在的BinLake集群中。
3、DBS
DBS主要完成自动化运维的工作。它可以完成数据库服务的自动化交付、数据库操作的流程化管理、数据库健康指数全面监控、数据库自动备份及结转,以及调度作业的多样化调度(包括定时、依赖以及触发三种调度模式)。

三、整体架构
这是京东数据库的一个整体架构图。可以看到,最底层是JDOS2.0,JDOS 2.0是京东新一代的容器技术,是Docker的管理平台,实际上京东所有的数据库服务现在已经完全运行在Docker之上了,这一点是让我们比较引以为豪的工作成绩,而这些都离不开京东JDOS的底层支持。
JED包括六大组件:
- JED-Gate:实现分库分表的透明化路由和审计功能。
- JED-Ctl:命令行控制工具。
- JED-Ctld:也提供集群控制功能,但是它是以服务的方式提供API接口。
- Topology:是整个JED的元数据管理中心,所有的元数据是通过Topology进行管理的。
- JED –Tablet:是每一个MySQL前端的Proxy,提供MySQL查询缓存和流复制等。
- JTransfer:在线数据迁移和接入工具。
BinLake的服务角色比较简单,只有两种服务:Wave和Tower。
BinLake整个集群是完全无状态的。我们所知道的大部分集群化服务都是有状态集群和不对等集群。所谓不对等集群就是集群里要有Master服务角色,负责整个集群的管理;还要有Worker服务角色,负责实际任务的执行。但整个BinLake是没有任何Master的,只有一种服务角色:Wave,就是你的工作节点。Tower只是一个可以与集群进行交互式操作的HTTP服务。Tower与传统Master节点的不同之处在于:它不负责任何元数据的管理,它只是向Topology服务发送命令,更新或者获取存储在ETCD或ZooKeeper中的元数据信息。
DBS是构建于我们的API Platform之上的,API Platform是我们自己开发的一个简单的Faas平台,有了API Platform,在京东只要是会写代码的人,不管你用何种开发语言,只要是满足Restful协议的服务,都可以注册到API Platform中,并不断丰富DBS。
DBS包括几个核心模块:
- JGurd 是一个分布式检测系统,它提供了对MySQL服务的完全分布式检测,避免了因为网络抖动而产生对MySQL健康状况的误判。
- Scheduler是调度平台,是基于Oozie改造开发的集群调度平台。
- JProcess Maker是DBS的流程引擎。
- DBS-Tools是我们在数据库运维过程中需要用到的一些数据库工具,比如说AWS报告、监控工具、Master切换工具、域名漂移工具等。
- Authentication是京东内部的身份认证和权限控制组件。
下面我们针对JED、BinLake和DBS的架构进行详细讲解。
1、JED
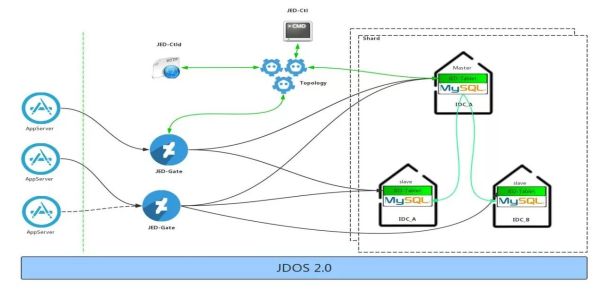
JED的前端是AppServer,从整体架构上,JED和Appserver直接打交道的只有一个角色,就是JED-Gate,JED-Gate完全兼容MySQL协议,AppServer可以一些查询语句发送给JED-Gate,JED-Gate层对所有查询的查询执行计划都会做缓存,并且根据查询执行计划,通过Topology服务获得查询所涉及表的路由源数据信息,根据元数据信息将查询语句改写或者拆分发送到底层的Shard上去。目前JED已经满足了广域分布架构,实现了异地多活。
2、BinLake
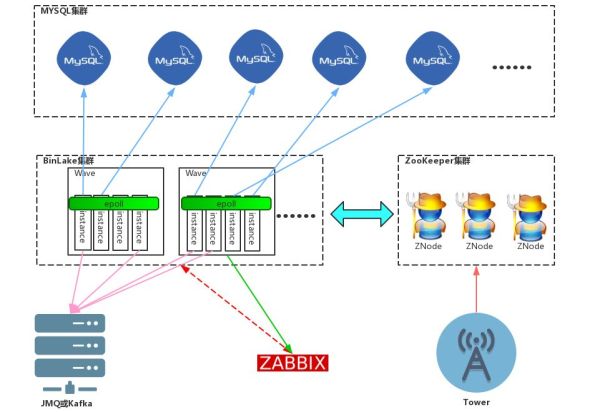
针对上图的BinLake架构图,可以看到BinLake集群中的每个工作节点叫做Wave,每个Wave节点上有多个instance,这个instance就是针对于每个MySQL实例的Binlog采集线程,在同一个Wave实例上的多个instance实例通过Epoll模型实现高效网络监听和通讯。当用户新采集一个MySQL的Binlog或者某个instance线程挂掉了,会根据当前集群中各个Wave服务的健康状况选择一个健康度最高的Wave实例,去实例化这个新的instance线程。而每个Wave实例上的健康度是根据Zabbix的监控数据进行动态计算的。
从图中可以看到,Tower服务其实没有跟Wave服务做任何直接的通讯或者联系,Tower只会跟ZK或ETCD集群直接做交互,它对ZK或者ETCD集群任何元数据的更改都被Wave服务及时发现,发现之后,Wave服务会采取一系列相应的措施,来对元数据的更改进行响应。
3、DBS
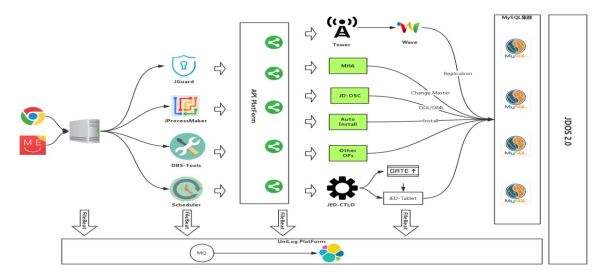
DBS依赖于两个基础的服务进行构建,第一个是API Platform,第二个是JDOS, 通过API Platform实现DBS整个系统所有功能模块的完全解耦,因为所有的底层操作都是单独开发的符合Restful标准的HTTP服务,并通过API Platform暴露出来。不管是研发人员还是DBA,无论使用什么样的开发语言,只要能够开发出符合Restful的HTTP服务,就可以将其注册到API Platform上,并实现DBS系统中特定的功能。
其实无论是JGuard、JProcessMaker、DBS-Tools还是Scheduler,它们做的所有工作都只有一样:调用API Platform上所暴露的接口。API Platform会根据你的注册信息,去调用Tower暴露的API接口,或者是调用MHA的一些脚本或者其它接口。
另外,不管是DBS的应用服务器、MySQL服务器、API Platform,后端写的所有接口,我们都会采集这些服务上的所有日志,采集了之后接入到Unilog Platform,用于后续的日志的审计和检查。
四、实现细节
由于京东弹性数据库包含的功能和组件很多,下面我选出几个特定的功能,在实现细节上详细说明。
1、动态在线扩容
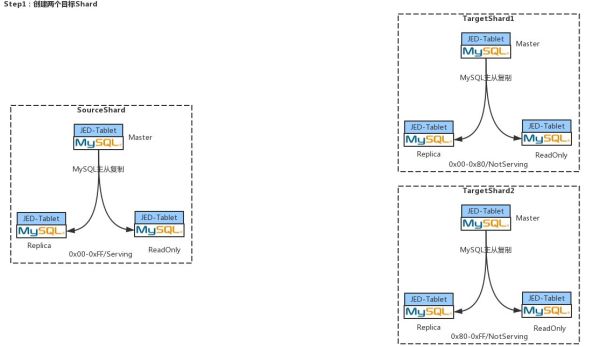
Step1:创建两个目标Shard
假设某个业务方在JED中起初申请了一个Shard,这个Shard大家可以把它简单地想象成是一套MySQL集群,这时我要将它扩容成两个Shard。
假设现在有一万条记录,要扩成两个Shard,那么每个目标Shard里面就有5000条。在JED里,在触发扩容这个动作时,首先会通过 JDOS接口,将目标Shard的所有POD都创建并启动起来,如果每个目标Shard都是1主2从,总共会启动6个POD,12个Container(一个POD中有2两个Container,1个Container中是Tablet服务,1个Container是MySQL服务),然后每个POD都是 Not Sevring状态,其中每三个POD实例组成一个Target shard。可以看到,Source Shard中的sharding key对应的key range是:0x00-OxFF,这里的 KeyRange也就是你的sharding key经过哈希之后能够落到多大的范围,现在要将一个Source Shard分为两个Target Shard,所以Source Target对应的Key Range也要就要一分为二,可以看到两个Target Shard 对应的KeyRange是0x00-Ox80,Ox80-Oxff,并且是Not Serving状态。
Step2:全量数据过滤克隆
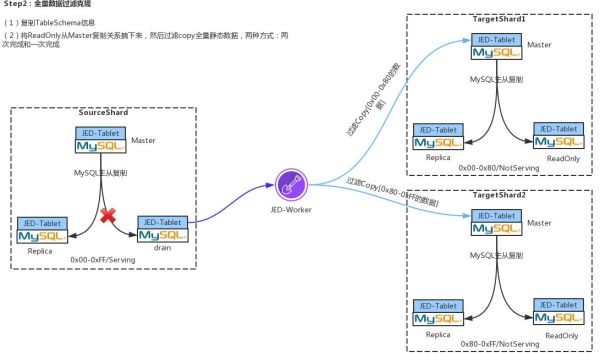
两个Target Shard建立之后,会根据ETCD里的默认配置针对每个Target Shard建立MySQL的复制关系,比如一主两从:一个Master,一个Replication,一个ReadOnly;一主三从,一个Master,两个Replication,一个Readonly;一主四从,一个Master,两个Replication和两个ReadOnly。
建立完复制关系之后,首先会通过JED-Worker将Source Shard中的Schema信息复制到两个TargetShard中,然后将Source Shard中的ReadOnly Pod从MySQL复制关系中摘除下来,最后通过JED-Worker将ReadOnly中的数据过滤拷贝到两个TargetShard中。
Step3:增量数据过滤到两个目标Shard
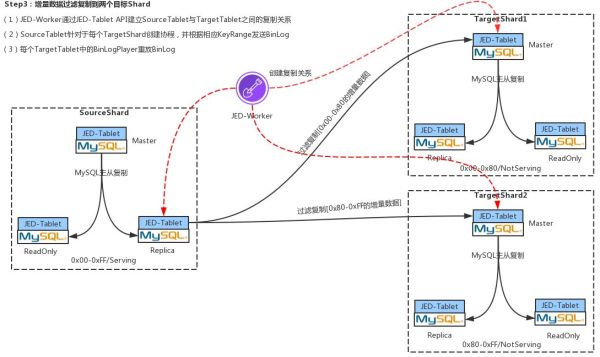
现在我们以最简单的一拖二的方式来讲述。当你的两个TargetShard建立完成后,你要做的就是先把你的这一万行记录拷到两个shard上,拷完之后去建立过滤复制。
完成了Step2的过滤拷贝之后,将ReadOnly重新挂到Source Shard上,然后JED-Worker通过Replication中的接口创建binlog的过滤复制,会在Replication上启动两个协程,并根据Target Shard的Key Range分别将binlog复制到对应的TargetShard上。
Step4:数据一致性校验
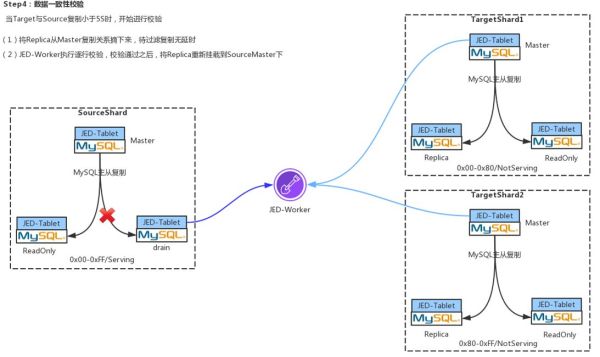
当TargetShard中的binglog与SourceShard中的binlog的lag小于5秒的时候,会启动数据的一致性校验,该过程是在JED-Worker上完成的。过程很简单,就是通过大量的后台协程Target和Source上去取出数据一条一条对比,如果数据的一致性校验通过,就开始进行Shard切换。
Step5:切Shard
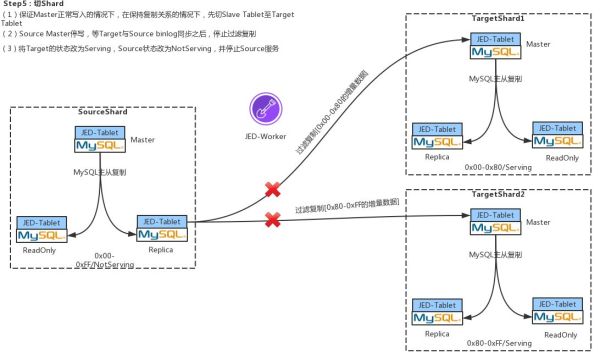
首先将SourceShard中Slave的Serving状态切换成Not Serving,同事将TargetShard中Slave的Not Serving状态更改为Serving,最后将Source中的Master停写,等Target中的Master与Source中的Master无复制延时后,将Source Master停写,通过JED-Worker将过滤复制断掉,然后将Target的Master置为Serving状态,并接受写入。
上述的所有Serving与NotServing状态的改变均是通过改变etcd中的元数据来完成的。当前端性业务再发送新的查询过来时,Gate就会根据最新的元数据信息,将你的这条SQL发送到最新的Target Shard。
2、自动FailOver
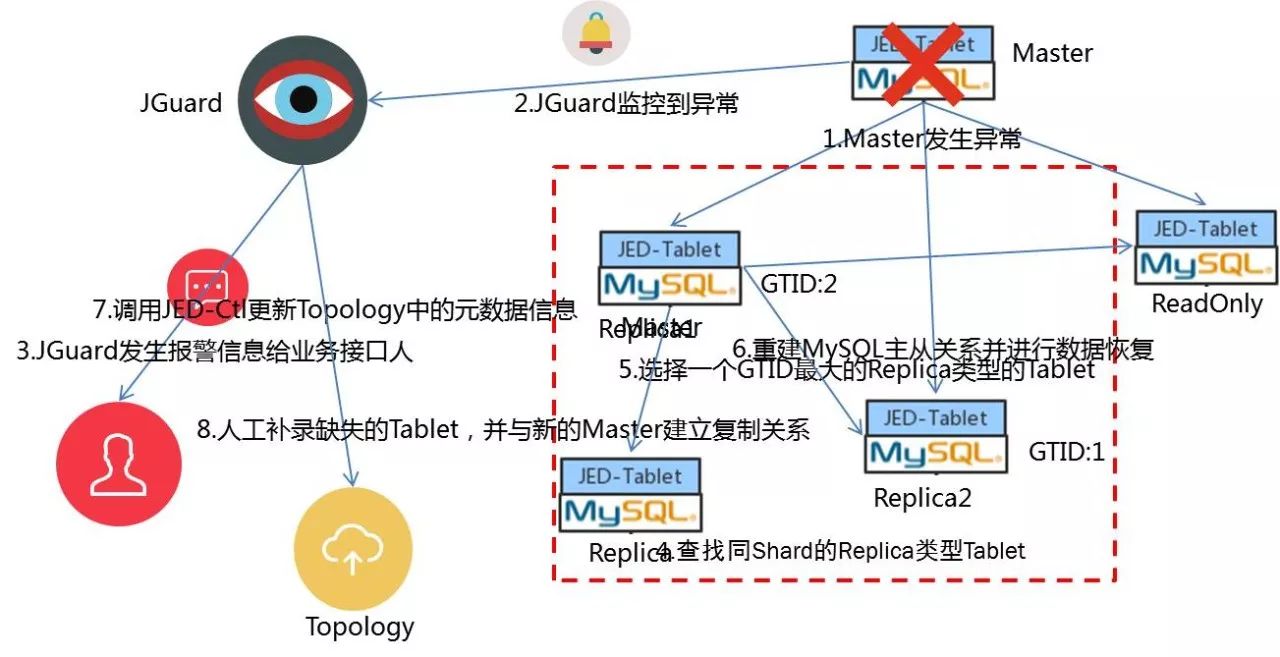
以1主3从的MySQL主从架构对JED的自动FailOver机制进行说明。
如果Master发生异常,JGuard会通过分布式检测(JGuard是通过ORC改造之后形成了一个分支检测服务)检测异常,检测到异常之后会通过邮件和短信通知业务接口人,通知完之后,不会等业务接口人进行处理,直接从当前整个MySQL集群当中选择一个GTID最大的一个MySQL实例,将这个MySQL实例切成Master,并根据新的Master重建新MySQL主从复制关系,将剩余的Replication和ReadOnly重新挂载到新的Master上,再调用JED-Ctrld服务的接口更新ETCD中的元数据,这样后续的DDL/DML就会发到最新的Master之上。最后缺失的一个Tablet需要人工补入。
3、Streaming Process
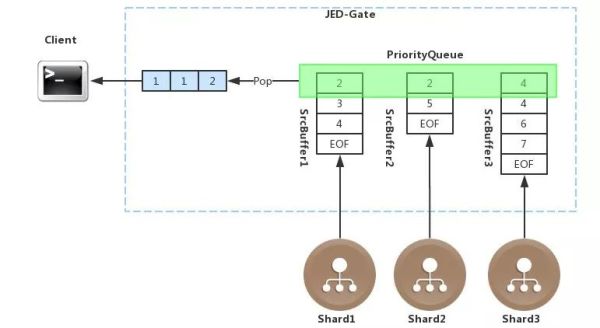
JED实现了查询的流式处理,以查询语句select table_a.age from table_a order by table_a.age为例说明流式处理的过程。JED-Gate接收到该查询语句之后,会根据ETCD中的分片元数据,将该语句分发到三个Shard中,各个Shard返回给JED-Gate数据本身就是有序的,在JED-Gate中针对每个Shard都会有一个buffer与之对应,每个buffer用来流式的接收每个Shard返回的排序完毕的数据,因此该buffer中的数据也是有序的。然后将每个buffer的首地址存储到一个PriorityQueue里面, PriorityQueue是一个堆排序的优先级队列,会根据每个buffer中的首元素不断的进行排序。每从PriorityQueue中取出一个元素,PriorityQueue都会调整Buffer的先后顺序,JED-Gate会将元数一个一个地取出来,以流式的方式发给前端,从而实现整体流式排序。
4、Join处理
现在我们看下如何在JED上执行Join查询的,在下面所有的说明中,我们都有一个假设条件,就是所有的表的sharding key都是ID。
对Join查询的处理,要分情况:
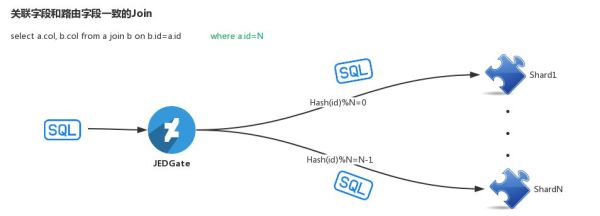
第一种情况:Join Key与Sharding Key相同。这种情况下由于Join Key 和 Sharding Key是完全相同的,因此是可以将Join查询语句直接发送到下面的每个shard,在JED-Gate汇聚各个shard的部分查询结果,并返回给前端应用。
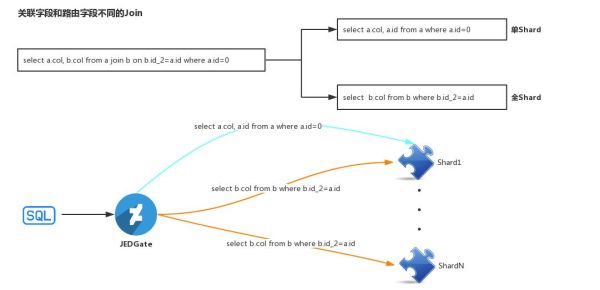
第二种情况:Join Key与Sharding Key相同。如上图所示,比如Select a.col,b.col.from a join b on b.id_2=a.id where a.id=0。针对该查询语句,JED-Gate首先对其进行SQL语句改写,改写为两条语句:select a.col,a.id from a where a.id=0和select b.col from b where b.id_2=a.id。在第二个查询语句中的a.id是绑定变量。JED-Gate会首先根据select a.col,a.id from a where a.id=0,定位到该SQL需要定位到哪个shard,然后将SQL发送到相应的Shard执行,并流式的获取其结果,然后将结果中的a.id字段的值取出,并将值赋给select b.col from b where b.id_2=a.id语句中的绑定变量a.id,然后将复制后的第二条SQL语句依次发送给所有的shard,并将结果与第一条SQL语句中的结果组合,流式地返回给前端。
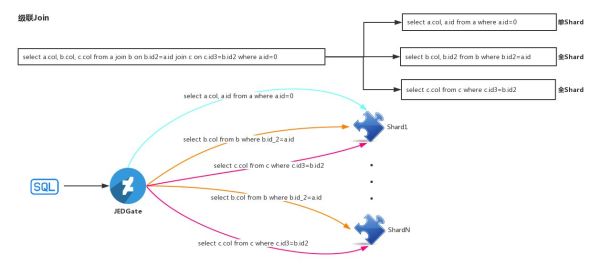
当多级Join的时候,也是相同的思路,这里不再赘述。
5、BinLake元数据架构图
前面已经提到BinLake有一个很大的特点:一个完全无状态的集群,没有Master管理节点。而要实现这个特性最重要的就是要有合理的元数据设计。之所以没有Master节点,是因为把Master节点的功能委托给了ZooKeeper或ETCD。通过借助ZooKeeper中的ephemeral znode实现了Wave服务乃至instance的自动发现和HA,并最终实现了无Master,无状态的完全对等集群。
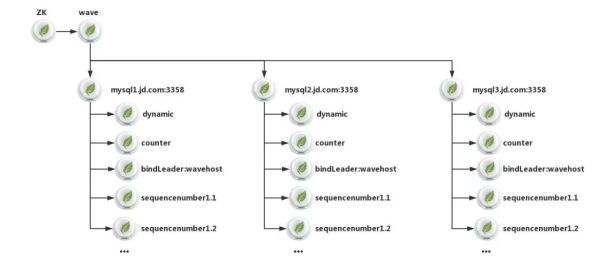
根据上面的元数据架构我们对BinLake的所有元数据进行详细说明。
一个BinLake集群的root znode是一个名为wave的znode,在wave之下是一系列的形式为:“MySQL域名命名:port”的znode。这样的每个znode都对应了一个MySQL实例。而在每个MySQL实例对应的znode下面是该MySQL实例的管理、信息保存和选举znode。其中counter节点中记录了当前MySQL实例对应的instanc重启了几次,若连续重启超过7次,就会发出报警信息。而dynamic节点则记录了每个MySQL实例对应的Binlog采集线程对应的快照信息,包括:当前采集到的Binlog文件、Offset、Timestamp、GTID、最近的10个时间点Binglog位置和Filter Rules等,从而保证instance重启后,可以利用这些信息继续进行Binlog采集。后面的sequencenumber对应的一系列znode是由Curator自动创建的znode,来保证选举的正确性和防止羊群效应。而“Bingdleader:wavehost”对应的znode,主要用于人工介入binlake,从而指定让下次instance leader选举的时候,固定在wavehost对应的Wave节点上。
如果我某个MySQL采集的Instance挂了,Curator就会在后面的第一个znode对应的wave服务上首先进行leader选举,若成功选举,就接入,否则依次对后面对应的每个Wave实例进行选举,直到成功选举出leader。选举出新的leader之后,就会在对应的Wave服务上重启Binlog采集的instance线程,该instance就会根据dynamic znode中存储的快照信息重建MySQL的复制关系,继续进行Binlog采集。
6、集群化Binlog订阅
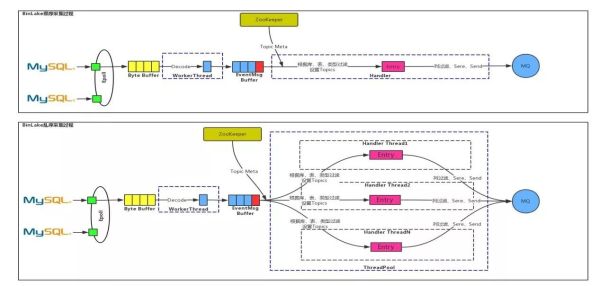
BinLake中的Binlog采集方式有两种:时序和乱序。
时序:通过NIO实现的类似Epoll的网络模型监听所有与MySQL之间的链接的网络事件等检测到与某个MySQL之间的连接有byte流到达时,就会尽量多的读取所有的byte流,将其全部放到一个Byte Buffer里,然后通过Worker Thread对ByteBuffer中的Byte进行Decode,并解析成一个个的EventMsg,进而将EventMsg也放到一个MessageBuffer中,在MessageBuffer后面有一个Handler线程,这个Handler线程会根据ZooKeeper里的一些元数据信息(比如:Topics、FilterRules、MQ类型和地址等)对EventMessage进行处理,然后使用protobuff进行序列化后发送到正确MQ中的特定的Topic里。这里的处理包括:根据库表类型过滤、列过滤、事务头Event和尾Event过滤等。
乱序:同从上图中可以看出乱序处理与时序处理的前半部分是相同的,只是在EventMessage Buffer后面是通过线程池进行并发处理的,测试结果表明乱序处理的性能是时序处理性能的10倍。
五、落地使用
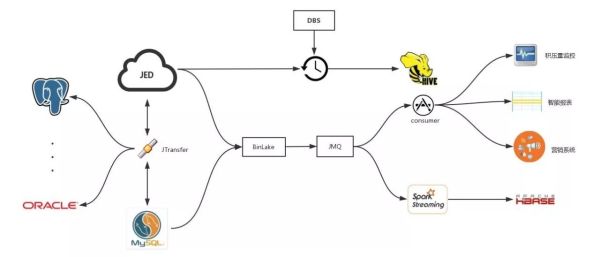
从上图可以看出,JED数据库中间件服务通过JTransfer来实现MySQL和JED之间的数据正反向同步和传输。现在JED可以实现MySQL向Oracle、Postgres等多种数据库的实时数据同步和传输。BinLake可以对MySQL和JED中的Binlog进行采集,并发送到JMQ或者Kafka,在MQ后端有两种使用方式:
通过Spark Streaming把它同步到HBase里,目前京东内部实际上是有一个项目叫做实时数据快照,就是通过这种方式,实现了HBase中的数据与线上MySQL实例中的数据的完全实时同步更新。
下游各个业务部门各自通过Consumer消费,进而进行订单积压监控、智能报表以及营销实时推荐等。当然JED以及BinLake、Jtransfer都是通过DBS进行自动化运维、调度和管理的。
京东弹性数据库落地状况

这些是在9月份从DBS系统里面拿到的,服务线上业务是指上线项目的个数,目前京东弹性数据库服务了线上3122个项目,管理的MySQL实例个数有将近两万个,管理的Table就比较多了,有660多万个,并且完成了自动在线切换2700余次,自动化上线有27000余次。现在京东有一般的业务都迁到了JED上,当然还有一半的业务正在容器化的MySQL服务上并逐步地进行迁移。
分片数与OPS、延时的关系情况
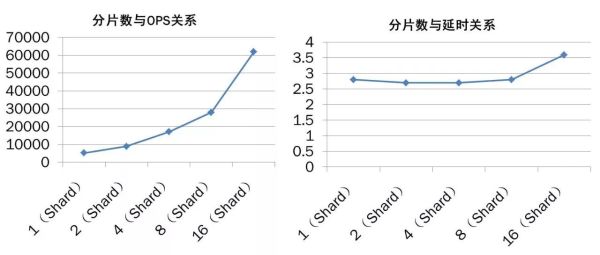
上图是JED的分片数与OPS以及分片数延时的一些关系。从图中可以看出,随着分片数的增加JED的服务能力也出现线性增长的趋势。而随着分片数的增加延时几乎没有变化(延时的单位是毫秒)。
Gate数与OPS、延时的关系情况
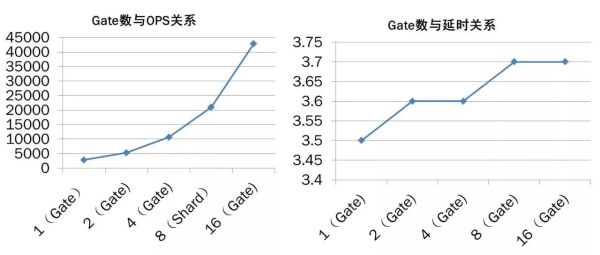
上图是Gate数目与OPS以及Gate数目与延时的关系。从图中可以看出,通过简单的增加Gate的数目而实现JED数据库服务能力的横向扩展,不会导致明显的延时增加。
问答环节
【问题1】想咨询一下咱们的JED做故障切换之后,如果存在数据的复制延迟,这时直接把它切为Read Write状态,有部分的Binlog数据还没追上来,脏数据怎么办?这部分脏数据是人工介入进行处理,还是有什么其它方案来把它自动处理?
答:JED在做Master FailOver时,实际就是你在后端做分片的时候,看MySQL的复制模式是半同步还是异步,如果是半同步,一旦发现你的Master Fail Over,不会出现所有Slave都lag Master的Binlog。
追问:就是说在Binlog追上之前还是ReadOnly状态,binlog完全追上之后,才切换为ReadWrite吗?
答:举个例子,比如说你后端Master下挂了两个Slave或者是多个Slave,因为你启用的是半同步,那么只要你里面没有任何一个追上Master(相当于是你的Master都是 ReadOnly状态),这个并不是说在Failover里存在这个问题,而是即使单纯的MySQL服务启用的若是半同步,当没有任何一个Slave追上Mater的时候,Master肯定是ReadOnly。
【问题2】老师好,因为刚才我听了JED,想问一下JED里有没有异构数据库?比如说,如果我要像你说到的有互相转这种情况,那么我要同时转几个表,在不同的异构数据库里面,我要如何保证它的查询速率?比如说各个表,我同事要加一个索引,我有没有统一配置的情况,还是集群里的每个库都要重新再各配一次?
答:说实话,没听太清楚你说什么,就说一个实际的例子吧,你的意思就是说JED里面有一个库,实际上就叫KeySpace,下面有四个分库或者四个分表你现在要统一对KeySpace中的所有分库或者分表加索引,它怎么去做,是吗?
追问:是每个分库都要加吗?这样的话是不是每个分表都要加一条索引,有没有可以统一一次性配置的功能?
答:在JED里面实际上是有一个控制台的,目前不支持直接通过Gate执行DDL,就是说DDL在Client或是通过JBDC Driver是不允许执行的,直接就会报错,你如果要执行DDL,是通过DBS自动化上线流程通过JED Ctld服务去执行的,Ctld服务会找到你KeySpace下的所有Shard,然后在每个Shard里面去执行这些DDL。
【问题3】有两个问题想请教一下,一是刚才演讲中听您说这个弹性数据库有好和坏的东西,那我能不能单独用一个组件一样的东西直接移植到JED上,其它东西不用行不行?我这边的这个数据库是主要是可以扩容的,但我们业务简单一点,可能没那么多。
答:京东弹性数据库现在包括三大模块,你可以单独地去用JED或者BinLake,但你不能够单独去用DBS,因为你如果单独用JED或者BinLake,你是可以脱离京东的自动化运维管理系统的控制,后续的审批当然是没有了的,可你对于BinLake这个集群以及JED的管理,是完全依赖于它的API是做控制的,就是说,后续假如说你公司有自己的一套运维管理系统,你可以基于BinLake或者JED的API,跟你的自动化运维管理系统集成,这个没问题,但你如果只用DBS就不行了,因为DBS是完全地跟京东的JDOS耦合的,这就是为什么我们可以实现数据库服务资源的一个自动化交付和自动化运维,实际上是建立在这个JDOS之上的,因为京东所有的数据库都已经上Docker了,所有的数据库服务均运行在Docker里,不管是JED还是传统的MySQL服务,都是运行在Docker之上的,所以说你只能够单独地用其中两个组件,一个是BinLake,一个是JED。
追问:另外一个问题就是说,因为你说的三个模板块,那么现在这个弹性数据库有没有可能做成一个像包一样的形式或一个统一的安装软件之类的东西,有没有这样的计划呢?
答:先回答第一个问题,三个模块是不会合到一块的,因为我们之所以把它分开就是为了实现解耦,我们现在正在启动内部的一些私有云的数据库服务,就是说后续对于我们京东内部的用户来说,你只需要申请就行了,有点像你用阿里的RDS一样,但我们不会对外提供服务,同时我们的JED和BinLake马上就会开源了,你马上就可以使用到了。
来自:http://database.51cto.com/art/201801/563260.htm

- 本文固定链接: https://zxbcw.cn/post/5902/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)