
本文将通过地图寻宝问题为例,向你简要介绍多智能体系统实施时的困难程度及其原因。
「研究人工智能三十五年来的主要经验是:困难的问题是易解的,简单的问题是难解的。」Pinker (1994),《The Language Instinct》
我之前觉得编写一个软件智能体来收集图上的宝藏是件简单的小事。但是我完全错了。编写出不愚蠢行动的智能体实际上非常困难。
明确定义的多智能体设置
「智能体是指任何通过传感器感知环境、通过效应器作用于环境的事物。」Stuart Russell&Peter Norvig,《Artificial Intelligence: A Modern Approach》
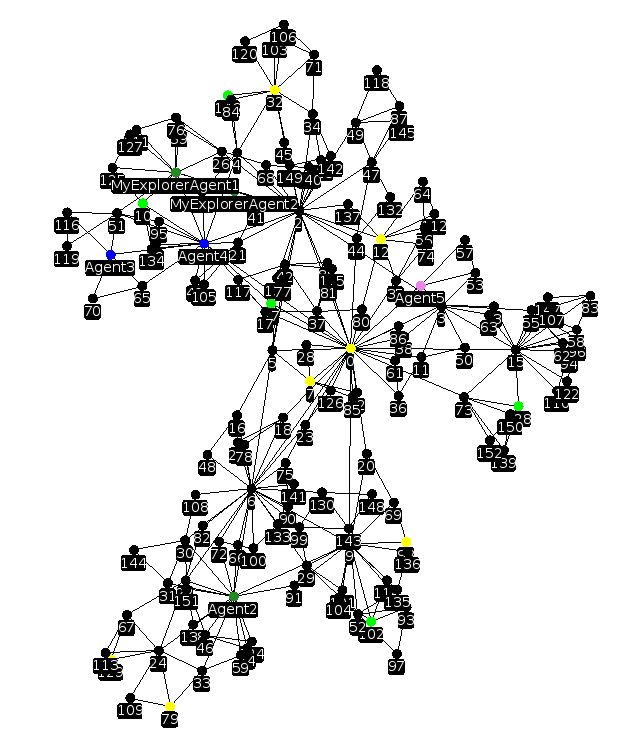
使用 GraphStream 库模拟多智能体系统收集宝藏。
这是一个简单的多智能体问题。让 n 个智能体在完全连接的图上移动并收集宝藏。智能体的行动、感知和沟通受到限制,它们只能观察并移动到与它们直接相连的节点,只能与足够接近的智能体进行通信。
有三种智能体:探险者、收集者和无限背包(Infinite-backpack)智能体。探险者注定要探索地图,因为它们不允许收集宝藏。收集者才可以收集,但它们不能携带太多,并且必须将它们收集的宝藏分发给无限背包智能体。
智能体的感知有限,但可以记住过去的观察结果。每个智能体都有自己的世界表征形式、自己的图(真实图的子图)。智能体的子图是它们访问过的所有节点的记忆,以及它们曾经见过或走过的边。它们必须将此图传达给其他智能体,以便它们都可以共享来自所有子图的修复。
JADE(Java Agent DEvelopement Framework)将用于实现所谓的「行为」(教程地址:http://jade.tilab.com/doc/tutorials/JADEProgramming-Tutorial-for-beginners.pdf、https://gitlab.com/herpsonc/startJade)。在这个多智能体系统框架中,行为是智能体将要执行的一组指令。在每一轮中,每个智能体都按顺序执行每个行为。
你的目标:实现智能体的行为,使之在一定时间内收集尽可能多的宝藏。
看起来很简单,是吧?
(注意:该项目是《多智能体系统简介》(ANDROIDE 的一门课程)的一部分。灵感来自于生存恐怖游戏 Hunt The Wumpus,在该项目的完整版本中,智能体需要处理四处游荡的、可怕的 Wumpus)。
重要的行为
想象两个智能体在长廊中朝相反方向移动。图的每个节点上只能有一个智能体,所以它们必须协调行为以避免阻碍别人。考虑到这种情况,我们必须实施一个特定的协议。
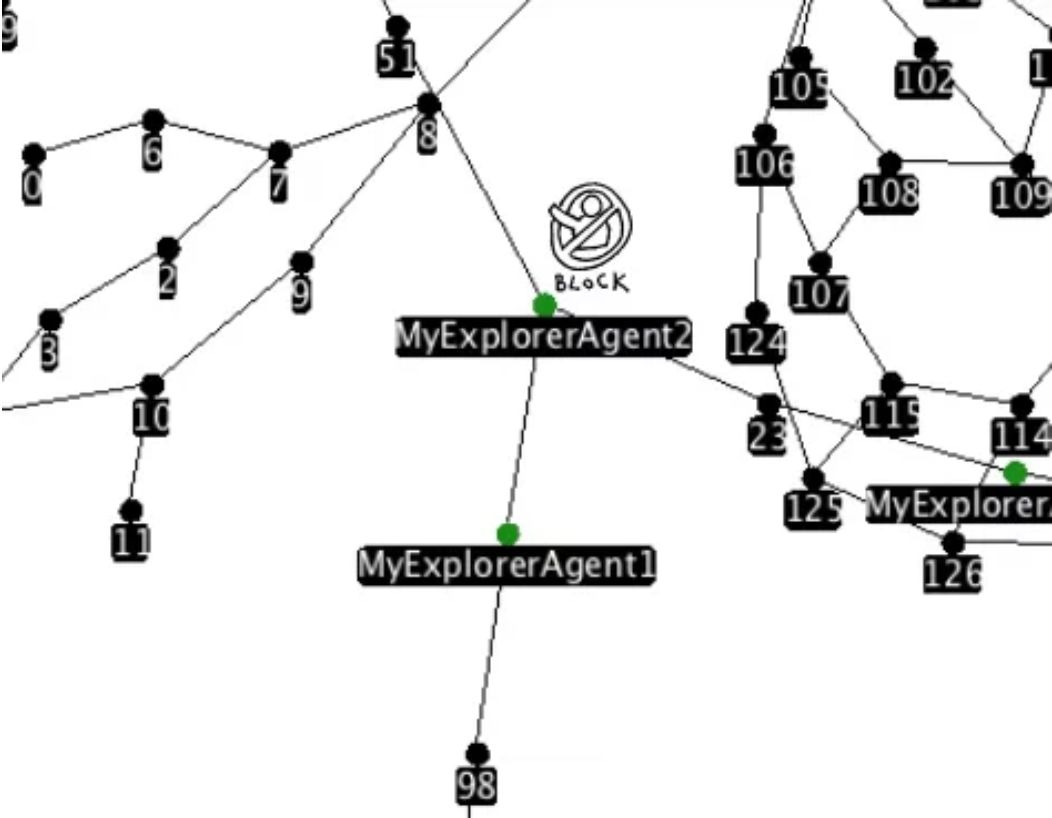
模拟中智能体的冲突:MyExplorerAgent2 挡住了其他两个智能体。
协调
智能体的感知有限,并且有不同的能力。因此,合作是必不可少的。发生冲突时,必须应用解除该情况的协议。它们必须分享自己的子图,看看谁更接近高度连接的节点,并就谁来移动达成一致。
探险者智能体必须同意谁来探索未知图形的哪个部分,以优化它们的移动并防止冲突。
信息交换
在多智能体设置中交换信息以便让每个智能体都能获取全局知识的过程被称为 gossip problem。
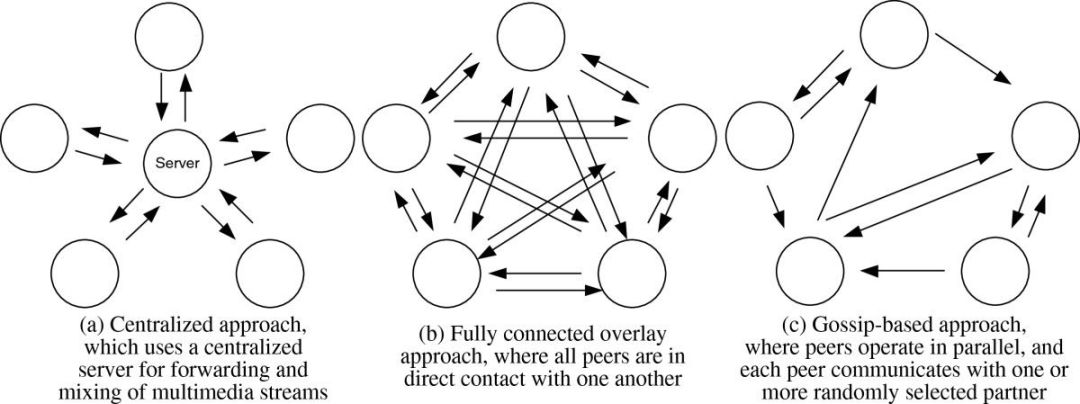
例如,假设集合 {1,2, … ,n} 中的每个智能体都知道一部分信息,称为一个秘密。然后,一个非常简单的协议是让智能体 1 呼叫 2、3、......、n,并了解它们的秘密。当 1 知道所有的秘密时,它会呼叫给 2、......、n,告诉它们这些秘密,这样每个智能体都知道所有的秘密了。总共有 n-1+n-1=2n-2 次呼叫。实际上,最佳解决方案需要 2n-4 次呼叫,这与我们的简单算法非常接近。
然而,在我们的问题中,直到所有节点都被探索时才能知晓完整信息,这使得算法稍微复杂一些,因为总的知识是动态的(智能体探索的图越多,它们的知识总量越多)。
这时就出现了优化妥协(optimization compromise)。为了让全部智能体知道所有秘密,这 n 个智能体之间必须交换消息的最佳数量是多少?更多信息意味着更好的全局知识和更好的协调。然而,由于有数千个智能体和数百万个节点,每毫秒发送数千条消息的成本远远无法忽略,成为一个计算负担。
异步通信
智能体之间的通信是异步的。由于智能体的执行是分布式的,所以没有全局时钟来同步智能体的动作。此外,在交换信息时,每个智能体都有一个邮箱,其中包含来自其他智能体的邮件,所以通信可能会延迟。在延迟期间,一个智能体可能会移动很远,并且永远不会回复原始信息。
联盟形成
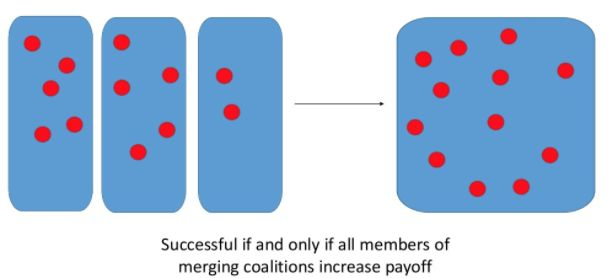
联盟形成示例(图源:https://www.slideshare.net/SurSamtani/coalition-formation-and-price-of-anarchy-in-cournot-oligopolies)
某些目标不能单独实现(比如抬起重物)。因此,智能体可能会同意组成一组智能体,称为联盟(coalition),来实现共同目标。
有了具备三种不同必要技能(探索、收集和积累)的智能体,一个至少包括三个智能体的联盟才会形成。因此,必须实施创建和更新联盟的协议。可以使用 Shapley 值(由智能体联盟创造的剩余额)来确定哪些联盟是最有价值的。
即使是在简单的问题设置中,有几个障碍出现得非常快,算法的复杂性似乎是无法克服的。当尝试构建行为类似人类的 AI 算法时,这是一个反复出现的现象。
让 AI 执行简单的行为是困难的
「要让计算机如成人般地做智力测试或下棋是相对容易的,但是要让它们有如一岁小孩般的感知和行动能力却是相当困难甚至是不可能的。」Moravec(1988),《Mind Children》
如果我们用人类替代智能体,我相信他们很快就会明白如何在这个游戏中取胜,他们会传达他们在图中所看到的信息,并形成联盟来收集最多的宝藏。然而,对智能体实施严格的行为准则却是非常困难的。
莫拉维克悖论:
对人类来说容易的事对机器来说却难以置信地困难。
说到下象棋,AI 表现出了超人类的水平。但是对于基本的人类行为,例如行走或协调行动来探索地图,人工智能算法却出奇地困难。
国际象棋大师加里·卡斯帕罗夫曾在《Deep Thinking》中写道:任何足够先进的算法都不难在同时进行的比赛中击败 20 名顶级棋手。但是没有 AI(机器人)可以在拥挤的酒吧中四处走动和自行移动棋子。

来源:https://www.youtube.com/watch?v=adFd0f7K46w
机器学习在非常特定的情况下工作
但是你可能会问为什么我们不使用最新的机器学习(ML)算法来解决我们的问题呢?......ML-only 算法只能被用于特定的任务。
是的,强化学习(RL)算法非常流行,可以解决超难的问题,例如在 Atari 游戏或围棋中展现出超人类的水平。但是这些游戏都是具备小数据输入的全可视性游戏,这与我们的寻宝问题并不相同,因为地图在开始时并不完全可见。

(图注)来源:http://deep%20reinforcement%20learning%20doesn%27t%20work%20yet/(Feb. 2018)
但是,OpenAI 不是在多智能体系统上,用机器学习算法在 Dota 2 的 5 vs 5 中战胜了人类吗?你可能会问。
是的,当在 Dota 2 1 vs 1 中战胜世界冠军时,OpenAI 展现了令人印象深刻的结果。但是这主要是因为它们强大的计算能力,并不是人工智能的突破。
它们的目标是利用一个包含 580 万场比赛的数据集在 5 vs 5 比赛中获胜。所以,它们似乎正在使用完全机器学习方法(从人类游戏中学习)研究多智能体问题,并且似乎缺少多智能体系统的自上而下方法。
智能体不会推断和概括。纯机器学习可用于单个智能体或完全可观察的系统,但是多智能体系统不是一个完全已知的世界,必须采用一个更普遍的方法。
我们不知道如何实现可扩展行为
在只有两个智能体在走廊上朝相反方向走的时候,我们遇到了一个问题。实施协议来处理这一特定问题是可能的
但是如果是 100 个智能体在具备 400 个节点的地图上呢?

少数智能体的硬编码功能与多智能体系统的可扩展和可泛化实现之间存在差距。
需要做什么
经过研究,必须开发特定的多智能体协议来解决这类问题。没有先验知识的学习不会教授智能体如何沟通,因为搜索空间太大。纯数据驱动的方法不会带来任何结果。
结论
实现一个解决寻宝问题的算法比看起来要困难得多。构思能够解决简单问题的多智能体系统绝非易事。机器学习算法在过去十年中取得了巨大成果,但仅凭机器学习无法解决所有的人工智能问题。
来自:https://www.jiqizhixin.com/articles/why-coding-multi-agent-systems-is-hard

- 本文固定链接: https://zxbcw.cn/post/5973/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)