
时序数据库从抽象语义上来说总体可以概括为两个方面的基本需求,一个方面是存储层面的基本需求:包括LSM写入模型保证写入性能、数据分级存储(最近2小时的数据存储在内存中,最近一天的数据存储在SSD中,一天以后的数据存储在HDD中)保证查询性能以及存储成本、数据按时间分区保证时间线查询性能。另一方面是查询层面的基本需求:包括基本的按时间线进行多个维度的原始数据查询、按时间线在多个维度进行聚合后的数据统计查询需求以及TopN需求等。
可见,多维条件查询通常是时序数据库的一个硬需求,其性能好坏也是评价一个时序数据库是否优秀的一个重要指标。调研了市场上大多时序数据库(InfluxDB、Druid、OpenTSDB、HiTSDB等),基本上都支持多维查询,只有极个别的暂时支持的并不完美。通常来说,支持多维查询的手段无非两种:Bitmap Index以及Inverted Index,也称为位图索引和倒排索引。
接下来笔者会重点介绍使用Bitmap索引来加快多维条件查询的基本原理以及工程实践,最后也会对倒排索引进行一个简单的介绍。其实这两种索引无论在原理上还是在工程实践上都极其相似,只是在几个小的细节问题上有所不同,在文章最后笔者也会进行详细的说明。
Bitmap索引到底是个神马
Bitmap称为位图,对此不了解的童鞋可以自行Google。在此我们举个简单的例子来演示如何使用Bitmap Index来加速数据库的多维查询性能。下图是一张典型的时序数据表:
| Timestamp |
Page |
Username |
Gender |
City |
Added |
Removed |
| 2011-01-01T01:00:00Z |
Justin Bieber |
Boxer |
Male |
San Francisco |
1800 |
25 |
| 2011-01-01T01:00:00Z |
Justin Bieber |
Reach |
Female |
Taiyuan |
2912 |
42 |
| 2011-01-01T02:00:00Z |
Ke$ha |
Helz |
Female |
Calgary |
1953 |
17 |
| 2011-01-01T02:00:00Z |
Ke$ha |
Xeno |
Male |
Taiyuan |
3194 |
170 |
图中Timestamp列是时序列,Page、Username、Gender和City这几个列是维度列,Added以及Removed两列是数值列。基于这样的原始表,可以构造一个典型的多维查询如下:
select Added from datasource where Gender = ‘Female’ and City = ‘Taiyuan’
查询中使用两个维度条件进行过滤,分别是Gender以及City列。很显然,如果不使用任何技术手段的话,在原始表上根据如上两个维度的过滤条件进行查询需要遍历整个原始表,并对相应维度列进行过滤,这个代价很显然是非常可观的。那能不能有一种方法可以直接根据维度的过滤条件得到待查找目标行,比如上述示例中能不能根据Gender = ‘Female’ and City = ‘Taiyuan’这两个过滤条件直接定位到待查找目标行就是第二行,其他行都不满足条件,这样的话只需要查找第二行的Added列返回给用户即可,不再需要野蛮的全表扫描并一条一条数据进行对比。这就是Bitmap索引(倒排索引)的使命!
使用Bitmap索引的基本原理是将这两列上的数值映射到bitmap上,再采用intersection表示来实现and、or等这种查询谓词。在上述示例中,将Gender以及City两列映射成bitmap如下图所示:
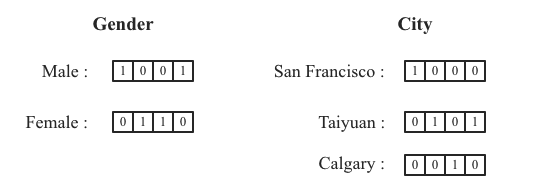
原始表中,Gender列中有两个值:Male和Female,因此需要设置两个对应的bitmap,Male分配一个,Female分配一个,两个bitmap的大小对应原始表的数据行数,原始数据有4行,bitmap的大小就是4。再看原始表的Gender列,行1和行4是Male,行2和行3是Female。因此将Male对应的bitmap中坐标为1和4的值置为1,其他两位置为0。Female对应的bitmap中坐标为2和3的值置为1,其他两位置为0。
这样的bitmap表示什么意思呢?以Male对应的bitmap来说,下标是1和4的值为1就表示原始表中这一列的第一行和第4行的值为Male。同理,Female对应的bitmap中下标是2和3对应的值为1表示原始表中这一列的第2行和第3行的值为Female。同样的道理,City列可以表示为上图右侧3个bitmap。
可见,每个维度列有多少种取值(Cardinality),这个维度列就会有多少个Bitmap。每个Bitmap表示对应取值在原始表中哪些行出现过。
这样表示完成之后,再来看看查询语句:where Gender = ‘Female’ and City = ‘Taiyuan’,就可以使用对应bitmap表示为如下形式:

分别拿出 Gender = ‘Female’ and City = ‘Taiyuan’ 对应的bitmap,执行and操作实际上对应位图的与运算,最终得到一个结果位图,结果位图中只有下标2的值置为1,说明原始表中满足查询条件的行只有第二行。接下来的工作就是怎么查询第二行的Added数值,这里就不再赘述。
很多讲解位图索引的博客对位图索引的介绍大多到此为止,仅仅介绍位图索引的工作原理。本文在介绍位图索引工作原理的基础上还会进一步深入介绍在真实的工程实践中整个位图索引工作体系。本文以Druid系统的目标,对Druid中位图索引的工作原理深入分析。主要包括如下几个部分:
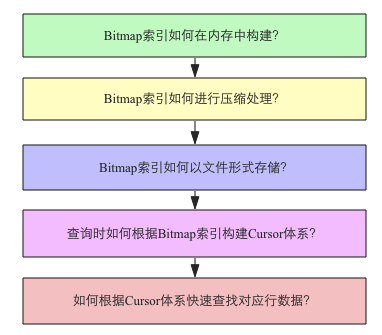
之前在一个开源项目中实现过一个倒排索引功能,其实与Bitmap索引实现原理基本一致。因为在之前并没有接触过倒排索引相关的实践知识,因此头脑中也没有非常完整的勾勒出这个功能的核心体系,在实现的时候才发现这样那样的问题,虽说最后也实现了功能,现在想来整个系统的模块化设计并不是非常考究。经过倒排索引项目的洗礼,再结合这段时间对Druid中Bitmap索引实现的研究,才将Bitmap索引这样一个大功能分解成上图中的五个小功能,每个小功能都是一个独立模块,笔者认为任何对Bitmap索引的工程实现都可以参考这五个模块进行设计思考。接下来就以Druid中Bitmap索引的实现分别就这五个小功能的细节问题进行深入分析。
Bitmap索引如何在内存中构建?
Druid数据实时写入节点采用LSM结构保证数据的写入性能。数据先写入内存,每隔10min(可配)会将内存中的数据persist到本地硬盘形成文件,然后会有一个线程再每隔1h(可配)将本地硬盘的多个文件合并成一个segment。
Bitmap索引构建时机
这里实际上会碰到第一个需要权衡的问题:Bitmap索引是应该在数据写入的同时实时构建呢,还是应该在数据从内存persist到硬盘的时候批量构建。很显然,实时构建会对数据写入吞吐量造成一定影响,实际测试下来发现写入性能会下降5%到15%,而且表维度越多,性能下降越明显。而另一方面,如果是批量构建,那么内存中的数据实际上是没有索引的,这部分数据的检索方式必然与已经持久化到硬盘文件数据的检索方式完全不同:内存中的数据检索不走索引直接查数据,文件中的数据检索需要先走索引再查数据,在实际查询实现中需要分别处理。
Druid中Bitmap的构建时机采用的后者,即在数据从内存persist到硬盘的时候批量构建。本人实现倒排索引时采用的是前者,主要考虑的问题是希望无论数据是在内存还是在硬盘,都能够采用统一的检索方式,即都先根据索引查询行号,再根据行号查具体数据。这样将内存检索和硬盘检索统一处理的好处是在代码实现上更加方便,更加简洁。当然,会牺牲一部分写入性能。
维度列构建维度字典
为维度列构建维度字典是Druid中非常重要的一个步骤。维度列中的值通常都可枚举,比如上文示例中维度列Gender只有两个可选值:Mela和Female,City列同样取值可枚举。因此有必要为每个维度列构建字典,将维度值(大多数为String)映射为Int值,大规模减少数据量。维度字典最核心的是两个Map映射:valueToId和idToValue,以City列为例,该列有三个值,构建出的字典就是 valueToId : <SanFrancisco, 0>, <Taiyuan,1>, <Calgary, 2>,idToValue是map反过来。可以看出来,构建字典就是为维度列的取值赋一个自增的Int值。
同理,可以分别为Page列、UserName列和Gender列构建相应的维度字典,构建完成之后,原始表中第三行的所有维度列就不再是Page:Ke$ha, UserName:Helz, Gender:Female, City:Calgary,而是[1, 2, 1, 2]。
构建Bitmap索引
上文说到Druid中Bitmap索引是在内存数据异步persist到硬盘文件的时候构建的,那接下来就需要看看表中一行记录过来之后如何分别为每个维度列构建Bitmap索引。
在介绍具体的构建流程之前,需要先说明一个关键的点:每个维度列实际上都会维护一个Bitmap数组:MutableBitmap[],数组大小为每个维度列的可取值多少(Cardinality),比如Gender列只有Male和Female两个取值,Bitmap数组大小就为2。数组的第一个值为Male对应的位图数据,数组的第二个值为Female对应的位图数据。这里就有一个问题,为什么说数组的第一个值是Male对应的位图数据,而不是第二个值呢?这就是用到了上文中提到的维度字典,Male对应的维度字典值为0,就对应数组下标为0;Female对应的维度字典值为1,对应数据下标就为1。
下面以其中一行数据为例介绍构建Bitmap索引的过程:
1. 首先会为每一行生成一个自增的rowNum
2. 遍历所有维度列,分别为每个维度列构建相应的Bitmap数组
- 针对某个纬度列的value值,首先在维度字典中根据value找到对应的id,这个id即是Bitmap数组的下标,根据这个下标找到该value对应的位图数据,即MutableBitmap[id]
- 定位到位图数据之后,再将该位图下标为rowNum的bit位置为1
为了更加具体地理解整个Bitmap索引构建的过程,我们以上文中Gender维度列为例模拟构建的过程:
1. Gender维度列会维护了一个位图数组MutableBitmap[] bitmaps,里面有两个位图元素,下标为0的是Male对应的bitmap,下标为1的是Female对应的bitmap。初始时这两个bitmap中都没有任何数字。
2. 遍历第一行(rowNum = 0),值为Male,根据维度字典找到对应的id位0,即Male对应的位图数据为bitmaps[0],将bitmaps[0]下标0(rowNum为0)的bit位置为1,得到:

3. 遍历第二行(rowNum = 1),值为Female,根据维度字典找到对应的id位1,即Male对应的位图数据为bitmaps[1],将bitmaps[1]下标1(rowNum为1)的bit位置为1,得到:

4. 遍历第三行(rowNum = 2),值为Female,根据维度字典找到对应的id位1,即Male对应的位图数据为bitmaps[1],将bitmaps[1]下标2(rowNum为2)的bit位置为1,得到:

5. 遍历第一行(rowNum = 3),值为Male,根据维度字典找到对应的id位0,即Male对应的位图数据为bitmaps[0],将bitmaps[0]下标3(rowNum为3)的bit位置为1,得到:
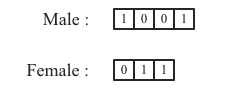
这样,就可以得到Gender维度列的Bitmap索引。当然,遍历一行数据时,同时会为所有其他维度列构建Bitmap索引,上述过程仅以Gender维度列作为示例,其他维度列同理可得。
Bitmap索引如何进行压缩处理?
Bitmap索引为什么需要压缩?
还是以Gender列为例,上文我们知道这个维度列只有两个取值:Male和Female,因此无论对于Male对应的位图数据,还是Female对应的位图数据,都会存在大量的连续的0或者连续的1,非常适合压缩编码,减小存储空间。
Bitmap索引如何进行压缩?
针对Bitmap的压缩有非常多的算法,大家可以自行Google。根据压缩效率、解码效率以及intersection等计算效率等指标的权衡,特别推荐使用RoaringBitmap压缩算法。有兴趣的同学可以自行Google。
Bitmap索引如何持久化存储?
Druid中原始数据每隔一段时间就会落盘一次,随着原始数据的落盘,原始数据中维度列对应的Bitmap索引也需要执行持久化存储。在实际实现中,Druid首先将维度字典持久化到文件,再将原始数据(维度列都使用维度字典编码处理)持久化到文件,最后再将维度列对应的Bitmap索引持久化到文件。
对于Druid系统来说,这里需要关注两点:
1. Druid系统是列式存储系统,同一个segment中所有列的数据都会分别独立存储在一起形成多个列文件,比如City列的数据会存储在一起形成文件,Added列的数据会存储在一起形成文件。其他列同理。
2. Druid系统中的文件分为两种,一种是定长文件格式,一种是非定长文件格式。定长文件针对于列数值是定长的,比如某些数值列是Double的,有些数据列是Long类型,再比如维度列经过编码之后所有维度列都是Int类型,时间列是Long类型。这些定长文件格式很简单,直接存储数值即可。而非定长文件通常主要针对列数值不是定长的,比如维度字典文件中需要存储维度值,这些维度值通常是字符串,并不定长;比如Bitmap索引的存储文件中需要存储Bitmap位图数据,这些值也不是定长的。下文主要介绍Bitmap索引的存储,所以重点介绍非定长文件格式。
Druid中非定长数值存储的文件格式如下图所示:
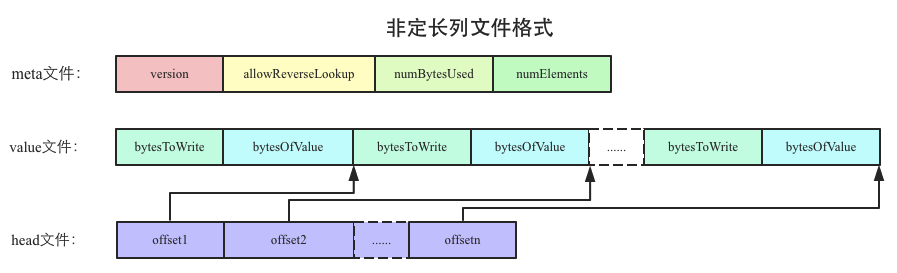
可以看出,Druid系统中使用了3个文件来存储非定长数据:meta文件,header文件以及value文件,其中meta文件主要存储一些元数据信息,比如存储数值个数、存储数值总大小等;value文件存储实际的数值,一个数值一个数值写进去,在实际数据之前有一个int值表示该数值的大小;header文件实际上是value文件中每个数值在value文件的偏移量,文件中每个值都是一个int。
维度字典文件存储
纬度列数据字典在数据写入的时候就会构建,并一直保存在内存。Druid会在persist的时候将其持久化形成维度字典文件,每个维度列的字典会单独形成一个文件,比如Gender维度列的数据字典会形成一个文件,City维度列的数据字典会形成另一个文件。下图是City维度列形成的维度列字典文件格式(没有列出meta文件):
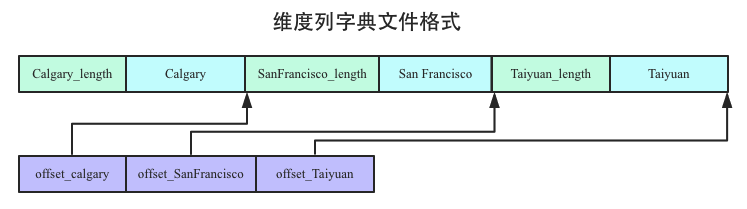
City维度列的数据字典一共有3个值:Calgary、San Francisco和Taiyuan,持久化到文件后就是上图格式,需要特别注意的是:数据字典的值是按照字典序由小到大排列之后存入文件的。比如上图中Calgary、San Francisco和Taiyuan就是按照由小到大排序后存储的。
这个点是工程实践中非常重要的一个技术点。上文中我们说数据字典在构建的时候其实并没有强调排序,而是按照维度列进来系统的顺序构建字典的,比如San Francisco先进入系统,在第一行,所以San Francisco对应的编码值就为0,Taiyuan是第二行,所以Taiyuan对应的编码值为1,同理,Calgary编码值为2。而且,Bitmap索引构建也是依赖于非排序的维度字典。如果此时在持久化的时候要将维度字典进行排序,那意味着Bitmap位图数据在Bitmap数组MutableBitmap[]中的位置也需要相应的变化,保持一致。
为什么需要排序?如果不排序直接存储行不行?
解答这个问题之前先看看维度字典文件,可以得到文件中只存储了维度列的值,并没有存储对应的编码值,那编码值哪去了?实际上编码值隐含在维度列值的下标,比如Calgary是第一个值,那对应的编码值就是0,Taiyuan是第三个值,对应的编码值就是2。基于这样的事实,如果不排序,你来告诉我如果说我想查Taiyuan对应的编码值,如何查?那就蒙圈了,需要一个一个遍历的查,如果某个维度Cardinality很大的话,不就跪了。而反过来,如果排序的话,就可以通过二分查找来查,下文会举例介绍。
Bitmap索引文件存储
Bitmap索引文件和维度字典文件是一一对应的,每个维度列的Bitmap索引会单独形成一个文件,比如Gender维度列的Bitmap索引会形成一个文件,City维度列的Bitmap索引会形成一个文件。下图是City维度列形成的Bitmap索引文件:
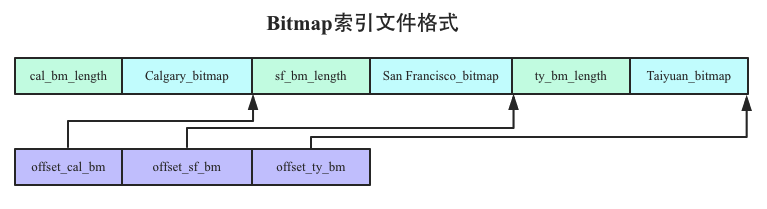
注意,Bitmap索引文件中Bitmap位图数据的存储顺序必须和维度字典中对应值的存储顺序一致。比如维度字典中Calgary存储在文件中第一的位置,对应的Bitmap位图就必须存储在相应第一的位置。
查询时如何根据Bitmap索引构建Cursor体系?
以查询语句select Added from datasource where Gender = ‘Female’ and City = ‘Taiyuan’为例,看看如何实现将where Gender = ‘Female’ and City = ’Taiyuan’这么一个多维度过滤条件转化成如下Bitmap与运算的结果:
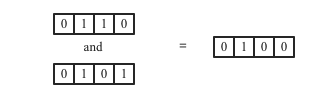
这样一个过程实际上可以分为两步:
1. 如何根据Gender = ‘Female’找到对应的位图数据?同理,如何根据City = ’Taiyuan’找到对应的位图数据?
2. 如何根据and操作符实现位图与操作?
根据and操作符实现位图与操作是比较简单的,现在很多Bitmap实现包中都有类似的功能,在此不再赘述。因此构建Cursor体系实际上就简化为根据维度过滤条件查找对应的位图数据这样一个问题。为了更加具体,我们以City = ’Taiyuan’为例定位对应的位图数据。整个过程分为如下几个部分:
1. 在City列对应的维度字典文件中查找’Taiyuan’值在文件中的下标
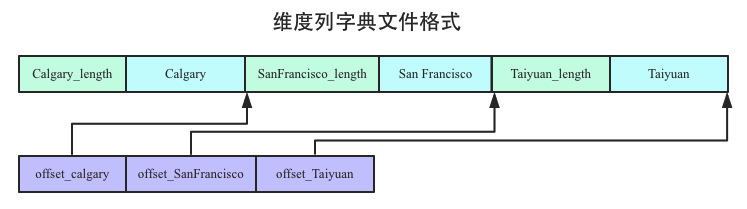
因为文件中维度值是由小到大排序的,所以查找的战术思想是二分查找。首先将查找指针移动到header文件的中心,中心下标curIndex = (minIndex,maxIndex)>>>1,header文件的中心值为offset_SanFrancisco,这个offset实际上指向了value文件中的San Francisco(这里忽略了一些细节),这个值与我们要找的值Taiyuan相比较,很显然前者小于后者,因此继续往后找。经过多次的查找,最终定位到Taiyuan对应的下标是2(从0开始哦)。
2. 在City列对应的Bitmap索引文件中查找下标为2的Bitmap位图数据,如下图所示,首先在header文件中找到下标为2的offset为offset_ty_bm,再根据偏移值在value文件中定位出Taiyuan对应的bitmap位图数据。(忽略具体的查找细节)
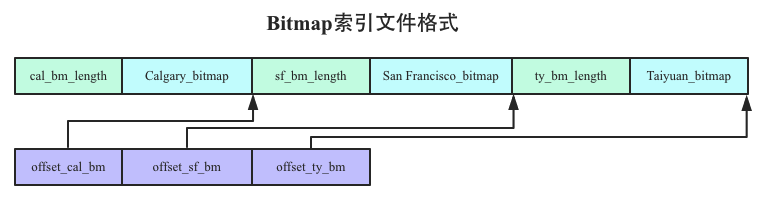
经过这两步的执行就可以根据City = ’Taiyuan’得到对应的bitmap位图数据,同理,根据Gender = ‘Female’可以得到对应的bitmap位图数据,两者使用与运算就可以得到一个最终的Bitmap位图索引,这个位图索引我们称为Cursor。
如何根据Cursor体系快速查找对应行数据?
Cursor结构体构建出来之后,如果根据这个结构快速的查找对应的行数据呢?这个过程也可以分为两步:
1. 根据上文介绍知道Cursor结构体实际上就是一个bitmap,bitmap中置为1的下标表示该行数据符合过滤条件。因此需要顺序遍历这个bitmap的所有位,如果目标位为1,表示该目标位下标对应的行满足过滤条件,需要将该行的对应数据找出来返回给用户。否则不满足过滤条件,直接跳过。
2. 假如bitmap中下标为的位置值为1,表示第二行满足过滤条件,因此需要查找第二行Added列的值。实现起来很简单,因为该列的所有值都存储在一个文件中,而且每个值都定长(都是Int),因此可以很快的在文件中加载出startOffset为Ints.Bytes,endOffset为2*Ints.Bytes的值,即为Added的值。
其他需要考虑的问题
讲到这里,笔者基本上已经将Bitmap索引的工程实践需要考量的技术点都做了介绍,但还有几个点需要考虑:
1. Bitmap索引目前仅支持写入,不支持更新。如果需要支持更新,需要做另外的考虑。
2. Bitmap索引文件需要在segment合并的时候也执行合并,合并的过程实际上也是一行一行的读出来,然后再根据上述过程生成一个新的Bitmap索引文件。
Inverted Index(倒排索引)工程实践
笔者之前在一个开源项目中实现了倒排索引功能,现在看来,基本实现思路和上述过程基本一致,核心不同点在于:倒排索引中每个维度列取值不再对应bitmap,而是对应一个列表。举个栗子,Bitmap索引体系中,Gender维度列中Male对应一个bitmap是[1,0,0,1]。换成倒排索引,Gender维度列中Male对应的不再是bitmap,而是一个List : [0,2],分别表示第1行和第三行。
除此之外,还有一些实现细节有些许不同:
1. Bitmap压缩性能通常没有倒排索引中List压缩效果好,前者会存在较大的存储空间开销。
2. Bitmap使用intersection实现and、or等操作的性能要好于倒排索引的List结构,后者需要从小到大遍历查找
3. 使用Bitmap构建的Cursor加速原始数据查找,需要遍历bitmap来找哪一行满足条件,只有bit位是1的才满足条件;而倒排索引构建的Cursor不需要查找,List中的数值就直接对应行号。
在常见的时序数据库中,InfluxDB和HiTSDB都使用了倒排索引来加速多维度查询,倒排索引会首先在内存中构建并持久化到文件(或HBase),在使用时再将索引加载到内存。
文章总结
这是很早之前花时间将之前研究的Bitmap索引知识整理了出来,拿出来和大家分享。本文从理论和工程实践两个方面对Bitmap索引的工作原理进行了深入的介绍,笔者认为文章的核心在于如何在工程实践中将Bitmap索引这么一个大命题分解成五个子命题,每个子命题中我们又应该重点关注哪些技术点。不得不说,要讲清楚Bitmap索引的工程实践确实有一定难度,文中或多或少会有一些难于理解的地方甚至纰漏。还忘各位看官担待指正!
来自:http://hbasefly.com/2018/06/19/timeseries-database-8/

- 本文固定链接: https://zxbcw.cn/post/6026/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)