
本文就所有 JavaScript 引擎中常见的一些关键基础内容进行了介绍——这不仅仅局限于 V8 引擎。作为一名 JavaScript 开发者,深入了解 JavaScript 引擎是如何工作的将有助于你了解自己所写代码的性能特征。
在前一篇文章中,我们讨论了 JavaScript 引擎是如何通过 Shapes 和 Inline Caches 来优化对象与数组的访问的。本文将介绍优化流程中的权衡与取舍,并对引擎在优化原型属性访问方面的工作进行介绍。
原文 JavaScript engine fundamentals: optimizing prototypes ,作者 @Benedikt 和 @Mathias ,译者 hijiangtao 。以下开始正文。
如果你倾向看视频演讲,请移步 YouTube 查看更多。
1. 优化层级与执行效率的取舍
前一篇文章介绍了现代 JavaScript 引擎通用的处理流程:
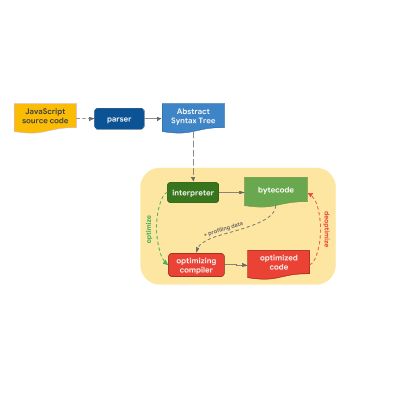
我们也指出,尽管从高级抽象层面来看,引擎之间的处理流程都很相似,但他们在优化流程上通常都存在差异。为什么呢? 为什么有些引擎的优化层级会比其他引擎更多? 事实证明,在快速获取可运行的代码与花费更多时间获得最优运行性能的代码之间存在取舍与平衡。
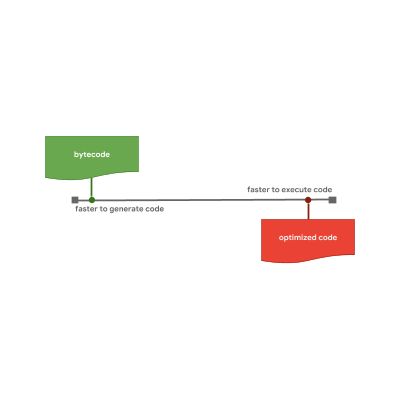
解释器可以快速生成字节码,但字节码通常效率不高。 相比之下,优化编译器虽然需要更长的时间,但最终会产生更高效的机器码。
这正是 V8 在使用的模型。V8 的解释器叫 Ignition,(就原始字节码执行速度而言)它是所有引擎中最快的解释器。V8 的优化编译器名为 TurboFan,它最终会生成高度优化的机器码。
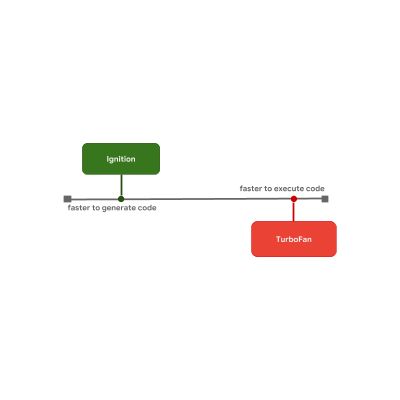
启动延迟与执行速度之间的这些权衡便是一些 JavaScript 引擎决定是否在流程中加入优化层的原因。例如,SpiderMonkey 在解释器和完整的 IonMonkey 优化编译器之间添加了一个 Baseline 层:
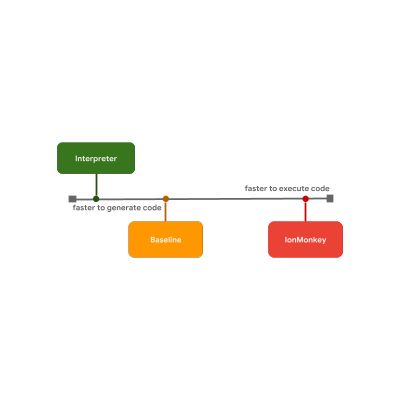
解释器可以快速生成字节码,但字节码执行起来相对较慢。Baseline 生成代码需要花费更长的时间,但能提供更好的运行时性能。最后,IonMonkey 优化编译器花费最长时间来生成机器码,但该代码运行起来非常高效。
让我们通过一个具体的例子,看看不同引擎中的优化流程都有哪些差异。这是一些在循环中会经常重复的代码。
let result = 0;
for (let i = 0; i < 4242424242; ++i) {
result += i;
}
console.log(result);
V8开始在 Ignition 解释器中运行字节码。从某些方面来看,代码是否足够 hot 由引擎决定,引擎话负责调度 TurboFan 前端,它是 TurboFan 中负责处理集成分析数据和构建代码在机器层面表示的一部分。这部分结果之后会被发送到另一个线程上的 TurboFan 优化器被进一步优化。
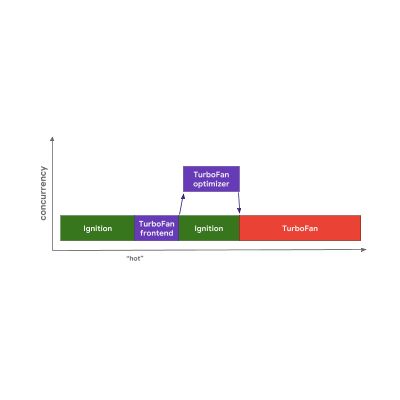
当优化器运行时,V8 会继续在 Ignition 中执行字节码。 当优化器处理完成后,我们获得可执行的机器码,执行流程便会继续下去。
SpiderMonkey 引擎也开始在解释器中运行字节码。但它有一个额外的 Baseline 层,这意味着比较 hot 的代码会首先被发送到 Baseline。 Baseline 编译器在主线程上生成 Baseline 代码,并在完成后继续后面的执行。
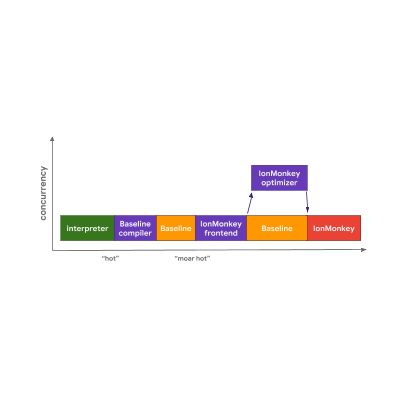
如果 Baseline 代码运行了一段时间,SpiderMonkey 最终会激活 IonMonkey 前端,并启动优化器 - 这与 V8 非常相似。当 IonMonkey 进行优化时,代码在 Baseline 中会一直运行。当优化器处理完成后,被执行的是优化后的代码而不是 Baseline 代码。
Chakra 的架构与 SpiderMonkey 非常相似,但 Chakra 尝试并行处理更多内容以避免阻塞主线程。Chakra 不在主线程上运行编译器,而是将不同编译器可能需要的字节码和分析数据复制出来,并将其发送到一个专用的编译器进程。
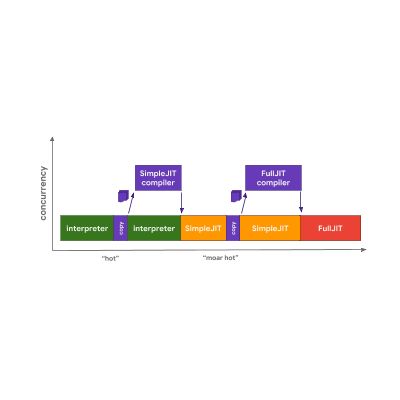
当代码准备就绪,引擎便开始运行 SimpleJIT 代码而不是字节码。 对于 FullJIT 来说流程也是同样如此。这种方法的好处是,与运行完整的编译器(前端)相比,复制所产生的暂停时间通常要短得多。但这种方法的缺点是这种 启发式复制 可能会遗漏某些优化所需的某些信息,因此它在一定程度上是用代码质量来换时间的消耗。
在 JavaScriptCore 中,所有优化编译器都与主 JavaScript 执行 完全并发运行 ;根本没有复制阶段!相反,主线程仅仅是触发了另一个线程上的编译作业。然后,编译器使用复杂的加锁方式从主线程中获取到要访问的分析数据。
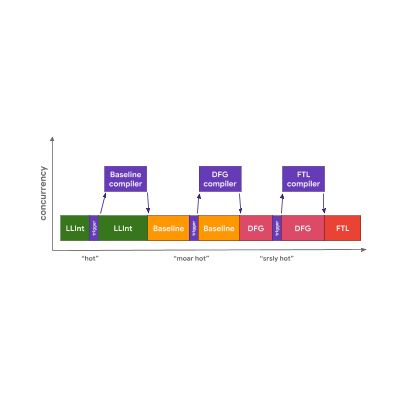
这种方法的优点在于它减少了主线程上由 JavaScript 优化引起的抖动。 缺点是它需要处理复杂的多线程问题并为各种操作付出一些加锁的成本。
我们已经讨论过在使用解释器快速生成代码或使用优化编译器生成可高效执行代码之间的一些权衡。但还有另一个权衡: 内存使用 !为了说明这一点,来看一个两个数字相加的简单 JvaScript 程序。
function add(x, y) {
return x + y;
}
add(1, 2);
这是我们使用 V8 中的 Ignition 解释器为 add 函数生成的字节码:
StackCheck
Ldar a1
Add a0, [0]
Return
不要在意这些字节码 - 你真的不需要阅读它。关键是它只是 四条指令!
当代码变得 hot,TurboFan 便会生成以下高度优化的机器码:
leaq rcx,[rip+0x0]
movq rcx,[rcx-0x37]
testb [rcx+0xf],0x1
jnz CompileLazyDeoptimizedCode
push rbp
movq rbp,rsp
push rsi
push rdi
cmpq rsp,[r13+0xe88]
jna StackOverflow
movq rax,[rbp+0x18]
test al,0x1
jnz Deoptimize
movq rbx,[rbp+0x10]
testb rbx,0x1
jnz Deoptimize
movq rdx,rbx
shrq rdx, 32
movq rcx,rax
shrq rcx, 32
addl rdx,rcx
jo Deoptimize
shlq rdx, 32
movq rax,rdx
movq rsp,rbp
pop rbp
ret 0x18
这么 一大堆 代码,尤其是与四条字节码相比!通常,字节码比机器码更紧凑,特别是优化过的机器码。但另一方面,字节码需要解释器才能执行,而优化过机器码可以由处理器直接执行。
这就是为什么 JavaScript 引擎不简单粗暴”优化一切”的主要原因之一。正如我们之前所见,生成优化的机器码也需要很长时间,而最重要的是,我们刚刚了解到优化的机器码也需要更多的内存。
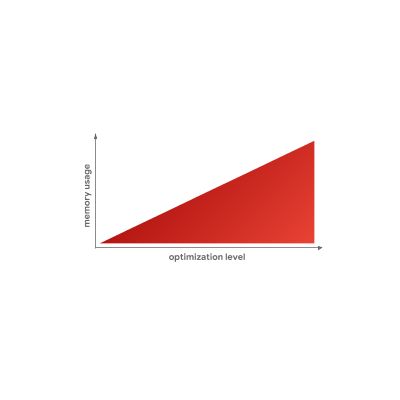
小结:JavaScript 引擎之所以具有不同优化层,就在于使用解释器快速生成代码或使用优化编译器生成高效代码之间存在一个基本权衡。通过添加更多优化层可以让你做出更细粒度的决策,但是以额外的复杂性和开销为代价。此外,在优化级别和生成代码所占用的内存之间也存在折衷。这就是为什么 JavaScript 引擎仅尝试优化比较 hot 功能的原因所在。
2. 原型属性访问优化
之前的文章解释了 JavaScript 引擎如何使用 Shapes 和 Inline Caches 优化对象属性加载。回顾一下,引擎将对象的 Shape 与对象值分开存储。
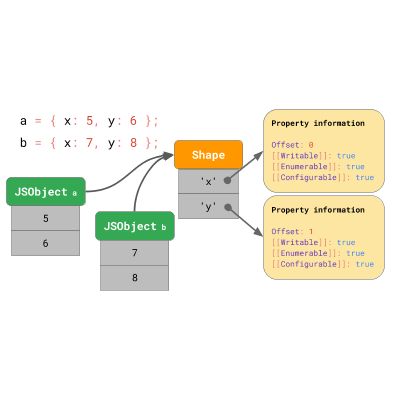
Shapes 可以实现称为 Inline Caches 或简称 ICs 的优化。通过组合,Shapes 和 ICs 可以加快代码中相同位置的重复属性访问速度。
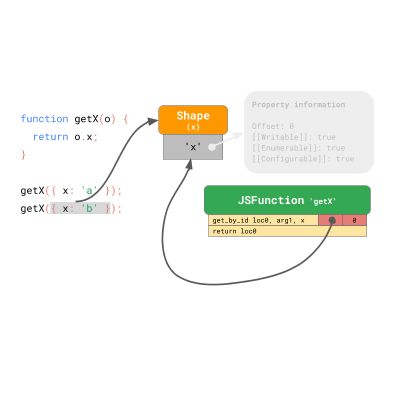
2.1 Class 和基于原型的编程
既然我们知道如何在 JavaScript 对象上快速进行属性访问,那么让我们看一下最近添加到 JavaScript 中的特性:class。JavaScript 中 class 的语法如下所示:
class Bar {
constructor(x) {
this.x = x;
}
getX() {
return this.x;
}
}
尽管这看上去是 JavaScript 中的一个全新概念,但它仅仅是基于原型编程的语法糖:
function Bar(x) {
this.x = x;
}
Bar.prototype.getX = function getX() {
return this.x;
};
在这里,我们在 Bar.prototype 对象上分配一个 getX 属性。这与其他任何对象的工作方式完全相同,因为原型只是 JavaScript 中的对象!在基于原型的编程语言(如 JavaScript)中,方法通过原型共享,而字段则存储在实际的实例上。
让我们来实际看看,当我们创建一个名为 foo 的 Bar 新实例时,幕后所发生的事情。
const foo = new Bar(true);
通过运行此代码创建的实例具有一个带有属性 “x” 的 shape。 foo 的原型是属于 class Bar 的 Bar.prototype 。
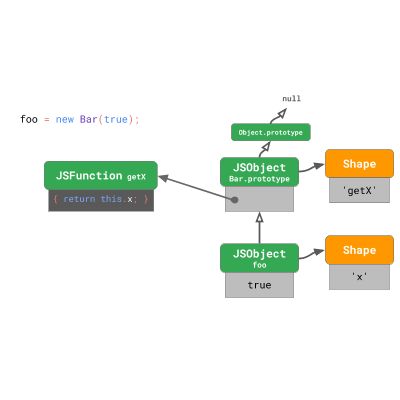
Bar.prototype 有自己的 shape,其中包含一个属性 'getX' ,取值则是函数 getX ,它在调用时只返回 this.x 。 Bar.prototype 的原型是 Object.prototype ,它是 JavaScript 语言的一部分。由于 Object.prototype 是原型树的根节点,因此它的原型是 null 。
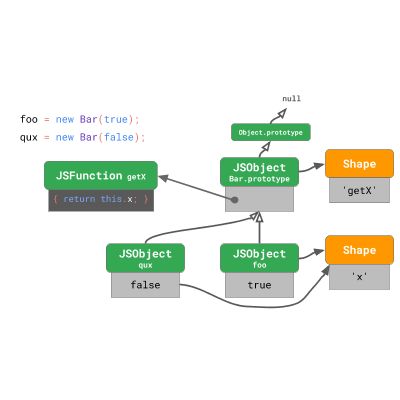
如果你在这个类上创建另一个实例,那么两个实例将共享对象 shape。两个实例都指向相同的 Bar.prototype 对象。
2.2 原型属性访问
好的,现在我们知道当我们定义一个类并创建一个新实例时会发生什么。但是如果我们在一个实例上调用一个方法会发生什么,比如我们在这里做了什么?
class Bar {
constructor(x) { this.x = x; }
getX() { return this.x; }
}
const foo = new Bar(true);
const x = foo.getX();
// ^^^^^^^^^^
你可以将任何方法调用视为两个单独的步骤:
const x = foo.getX();
// is actually two steps:
const $getX = foo.getX;
const x = $getX.call(foo);
第1步是加载这个方法,它只是原型上的一个属性(其值恰好是一个函数)。第2步是使用实例作为 this 值来调用该函数。让我们来看看第一步,即从实例 foo 中加载方法 getX 。
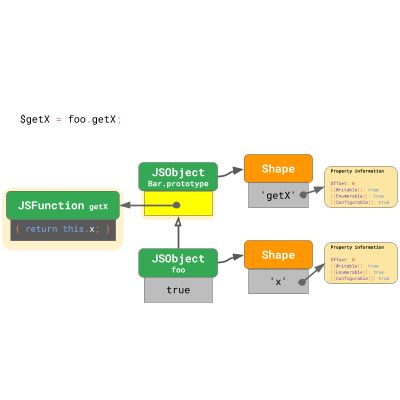
引擎从 foo 实例开始,并且意识到 foo 的 shape 上没有 'getX' 属性,所以它必须向原型链追溯。我们到了 Bar.prototype ,查看它的原型 shape,发现它在偏移0处有 'getX' 属性。我们在 Bar.prototype 的这个偏移处查找该值,并找到我们想要的 JSFunction getX 。就是这样!
但 JavaScript 的灵活性使得我们可以改变原型链链接,例如:
const foo = new Bar(true);
foo.getX();
// → true
Object.setPrototypeOf(foo, null);
foo.getX();
// → Uncaught TypeError: foo.getX is not a function
在这个例子中,我们调用 foo.getX() 两次,但每次它都具有完全不同的含义和结果。 这就是为什么尽管原型只是 JavaScript 中的对象,但优化原型属性访问对于 JavaScript 引擎而言比优化常规对象的属性访问更具挑战性的原因了。
粗略的来看,加载原型属性是一个非常频繁的操作:每次调用一个方法时都会发生这种情况!
class Bar {
constructor(x) { this.x = x; }
getX() { return this.x; }
}
const foo = new Bar(true);
const x = foo.getX();
// ^^^^^^^^^^
之前,我们讨论了引擎如何通过使用 Shapes 和 Inline Caches 来优化访问常规属性的。 我们如何在具有相似 shape 的对象上优化原型属性的重复访问呢? 我们在上面已经看过是如何访问属性的。
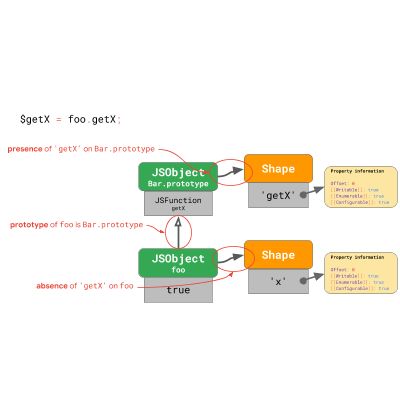
为了在这种特殊情况下实现快速重复访问,我们需要知道这三件事:
- foo 的 shape 不包含 'getX' 并且没有改变过。这意味着没有人通过添加或删除属性或通过更改其中一个属性来更改对象 foo 。
- foo 的原型仍然是最初的 Bar.prototype 。这意味着没有人通过使用 Object.setPrototypeOf() 或通过赋予特殊的 _proto_ 属性来更改 foo 的原型。
- Bar.prototype 的形状包含 'getX' 并且没有改变。这意味着没有人通过添加或删除属性或更改其中一个属性来更改 Bar.prototype 。
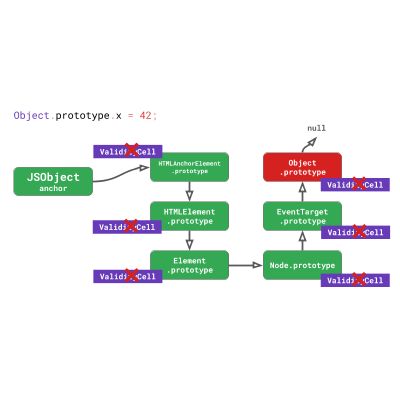
一般情况下,这意味着我们必须对实例本身执行1次检查,并对每个原型进行2次检查,直到找到我们正在寻找的属性所在原型。 1 + 2N 次检查(其中 N 是所涉及的原型的数量)对于这种情况听起来可能不太糟糕,因为这里原型链相对较浅 - 但是引擎通常必须处理更长的原型链,就像常见的 DOM 类一样。这是一个例子:
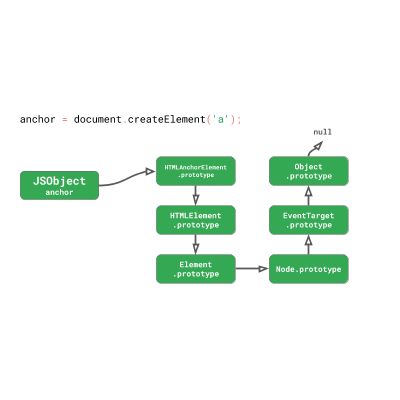
const anchor = document.createElement('a');
// → HTMLAnchorElement
const title = anchor.getAttribute('title');
我们有一个 HTMLAnchorElement ,在其上调用 getAttribute() 方法。这个简单的锚元素原型链就已经涉及6个原型!大多数有趣的 DOM 方法并不是直接存在于 HTMLAnchorElement 原型中,而是在原型链的更高层。
我们可以在 Element.prototype 上找到 getAttribute() 方法。这意味着我们每次调用 anchor.getAttribute() 时,JavaScript引擎都需要……
'getAttribute'
HTMLAnchorElement.prototype
HTMLElement.prototype
'getAttribute'
Element.prototype
'getAttribute'
总共有7次检测!由于这是 Web 上一种非常常见的代码,因此引擎会应用技巧来减少原型上属性加载所需的检查次数。
回到前面的例子,我们在 foo 上访问 'getX' 时总共执行了3次检查:
class Bar {
constructor(x) { this.x = x; }
getX() { return this.x; }
}
const foo = new Bar(true);
const $getX = foo.getX;
在直到我们找到携带目标属性的原型之前,我们需要对原型链上的每个对象进行 shape 的缺失检查。如果我们可以通过将原型检查折叠到缺失检查来减少检查次数,那就太好了。而这基本上就是引擎所做的: 引擎将原型链在 Shape 上,而不是直接链在实例上。
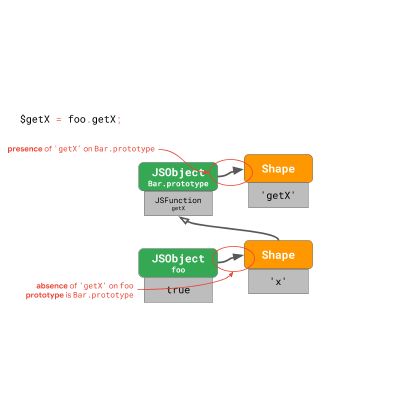
每个 shape 都指向原型。这也意味着每次 foo 原型发生变化时,引擎都会转换到一个新 shape。 现在我们只需要检查一个对象的 shape,这样既可以断言某些属性的缺失,也可以保护原型链链接。
通过这种方法,我们可以将检查次数从 1 + 2N 降到 1 + N ,以便在原型上更快地访问属性。但这仍相当昂贵,因为它在原型链的长度上仍然是线性的。 为了进一步将检查次数减少到一个常量级别,引擎采用了不同的技巧,特别是对于相同属性访问的后续执行。
2.3 Validity cells
V8专门为此目的处理原型的 shape。每个原型都具有一个不与其他对象(特别是不与其他原型共享)共享且独特的 shape,且每个原型的 shape 都具有与之关联的一个特殊 ValidityCell 。
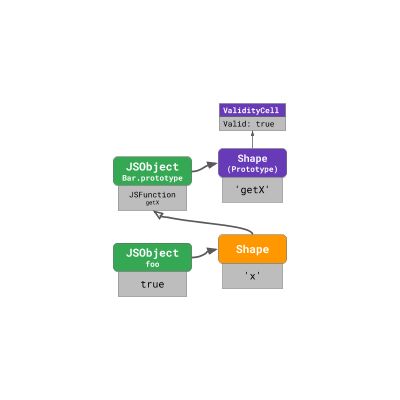
只要有人更改相关原型或其祖先的任何原型,此 ValidityCell 就会失效。让我们来看看它是如何工作的。
为了加速原型的后续访问,V8 建立了一个 Inline Cache,其中包含四个字段:
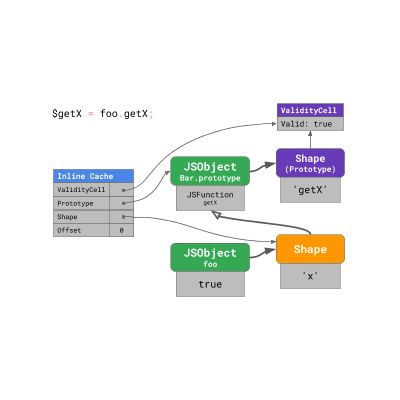
在第一次运行此代码预热 inline cache 时,V8 会记住目标属性在原型中的偏移量,找到属性的原型(本例中为 Bar.prototype ),实例的 shape(在这种情况下为 foo 的 shape),以及与实例 shape 链接的 直接原型 中 ValidityCell 的链接(在本例中也恰好是 Bar.prototype )。
下次 inline cache 命中时,引擎必须检查实例的 shape 和 ValidityCell 。如果它仍然有效,则引擎可以直接到达 Prototype 上的 Offset 位置,跳过其他查找。
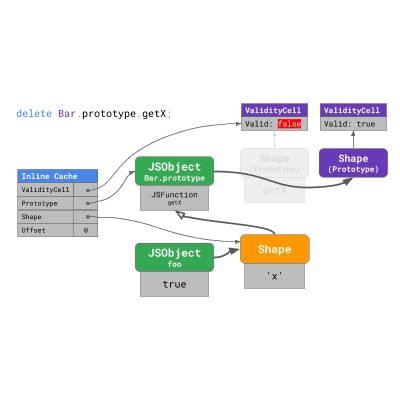
当原型改变时,shape 将重新分配,且先前的 ValidityCell 失效。因此,Inline Cache 在下次执行时会失效,从而导致性能下降。
回到之前的 DOM 示例,这意味着对 Object.prototype 的任何更改不仅会使 Object.prototype 本身的 inline cache 失效,而且还会使其下游的所有原型失效,包括 EventTarget.prototype , Node.prototype , Element.prototype 等,直到 HTMLAnchorElement.prototype 为止。
实际上,在运行代码时修改 Object.prototype 意味着完全抛弃性能上的考虑。不要这样做!
让我们用一个具体的例子来探讨这个问题。 假设我们有一个类叫做 Bar ,并且我们有一个函数 loadX ,它调用 Bar 对象上的方法。 我们用同一个类的实例多调用这个 loadX 函数几次。
class Bar { /* … */ }
function loadX(bar) {
return bar.getX(); // IC for 'getX' on `Bar` instances.
}
loadX(new Bar(true));
loadX(new Bar(false));
// IC in `loadX` now links the `ValidityCell` for
// `Bar.prototype`.
Object.prototype.newMethod = y => y;
// The `ValidityCell` in the `loadX` IC is invalid
// now, because `Object.prototype` changed.
loadX 中的 inline cache 现在指向 Bar.prototype 的 ValidityCell 。 如果你之后执行了类似于改变 Object.prototype (这是 JavaScript 中所有原型的根节点)的操作,则 ValidityCell 将失效,且现有的 inline cache 会在下次命中时丢失,从而导致性能下降。
修改 Object.prototype 被认为是一个不好的操作,因为它使引擎在此之前为原型访问准备的所有 inline cache 都失效。 这是另一个 不推荐 的例子:
Object.prototype.foo = function() { /* … */ };
// Run critical code:
someObject.foo();
// End of critical code.
delete Object.prototype.foo;
我们扩展了 Object.prototype ,它使引擎在此之前存储的所有原型 inline cache 均无效了。然后我们运行一些用到新原型方法的代码。引擎此时则需要从头开始,并为所有原型属性的访问设置新的 inline cache。最后,我们删除了之前添加的原型方法。
清理,这听起来像个好主意,对吧?然而在这种情况下,它只会让情况变得更糟!删除属性会修改 Object.prototype ,因此所有 inline cache 会再次失效,而引擎又必须从头开始。
总结:虽然原型只是对象,但它们由 JavaScript 引擎专门处理,以优化在原型上查找方法的性能表现。把你的原型放在一旁!或者,如果你确实需要修改原型,请在其他代码运行之前执行此操作,这样至少不会让引擎所做的优化付诸东流。
5. Take-aways
我们已经了解了 JavaScript 引擎是如何存储对象与类的, Shapes 、 Inline Caches 和 ValidityCells 是如何帮助优化原型的。基于这些知识,我们认为存在一个实用的 JavaScript 编码技巧,可以帮助提高性能:不要随意修改原型对象(即便你真的需要,那么请在其他代码运行之前做这件事)。
(完)
来自:https://hijiangtao.github.io/2018/08/21/Prototypes/

- 本文固定链接: https://zxbcw.cn/post/6076/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)