
2021
07-26
07-26
pytorch中的优化器optimizer.param_groups用法
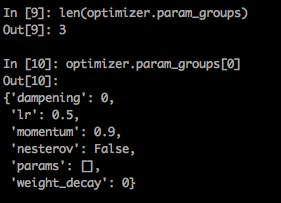
optimizer.param_groups:是长度为2的list,其中的元素是2个字典;optimizer.param_groups[0]:长度为6的字典,包括[‘amsgrad',‘params',‘lr',‘betas',‘weight_decay',‘eps']这6个参数;optimizer.param_groups[1]:好像是表示优化器的状态的一个字典;importtorchimporttorch.optimasoptimh2w1=torch.randn(3,3)w1.requires_grad=Truew2=torch.randn(3,3)w2.requires_grad=Trueo=optim.Adam([w1])p...
继续阅读 >
 optim的基本使用fordo:1.计算loss2.清空梯度3.反传梯度4.更新参数optim的完整流程cifiron=nn.MSELoss()optimiter=torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9)foriinrange(iters):out=net(inputs)loss=cifiron(out,label)optimiter.zero_grad()#清空之前保留的梯度信息loss.backward()#将mini_batch的loss信息反传回去optimiter.step()#根据optim参数和梯度更新参...
optim的基本使用fordo:1.计算loss2.清空梯度3.反传梯度4.更新参数optim的完整流程cifiron=nn.MSELoss()optimiter=torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9)foriinrange(iters):out=net(inputs)loss=cifiron(out,label)optimiter.zero_grad()#清空之前保留的梯度信息loss.backward()#将mini_batch的loss信息反传回去optimiter.step()#根据optim参数和梯度更新参...
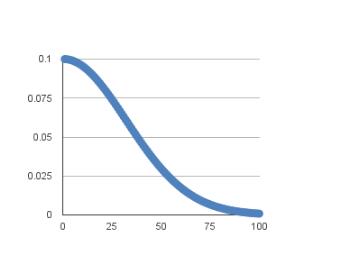 SGD随机梯度下降Keras中包含了各式优化器供我们使用,但通常我会倾向于使用SGD验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器。Keras中文文档中对SGD的描述如下:keras.optimizers.SGD(lr=0.01,momentum=0.0,decay=0.0,nesterov=False)随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量参数:lr:大或等于0的浮点数,学习率momentum:大或等于0的浮点数,动...
SGD随机梯度下降Keras中包含了各式优化器供我们使用,但通常我会倾向于使用SGD验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器。Keras中文文档中对SGD的描述如下:keras.optimizers.SGD(lr=0.01,momentum=0.0,decay=0.0,nesterov=False)随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量参数:lr:大或等于0的浮点数,学习率momentum:大或等于0的浮点数,动...