
2021
01-27
01-27
springboot反爬虫组件kk-anti-reptile的使用方法
大家好,我是为广大程序员兄弟操碎了心的小编,每天推荐一个小工具/源码,装满你的收藏夹,每天分享一个小技巧,让你轻松节省开发效率,实现不加班不熬夜不掉头发,是我的目标! 今天小编推荐一款反爬虫组件叫kk-anti-reptile,一款可快速接入的反爬虫、接口防盗刷springbootstater组件。1.系统要求基于spring-boot开发(spring-boot1.x,spring-boot2.x均可)需要使用redis2.工作流程 &...
继续阅读 >
 在找寻材料的时候,会看到一些暂时用不到但是内容不错的网页,就这样关闭未免浪费掉了,下次也不一定能再次搜索到。有些小伙伴会提出可以保存网页链接,但这种基本的做法并不能在网页打不开后还能看到内容。我们完全可以用爬虫获取这方面的数据,不过操作过程中会遇到一些阻拦,今天小编就教大家用sleep间隔进行python反爬虫,这样就可以得到我们想到的数据啦。步骤要利用headers拉动请求,模拟成浏览器去访问网站,跳过最简单的反...
在找寻材料的时候,会看到一些暂时用不到但是内容不错的网页,就这样关闭未免浪费掉了,下次也不一定能再次搜索到。有些小伙伴会提出可以保存网页链接,但这种基本的做法并不能在网页打不开后还能看到内容。我们完全可以用爬虫获取这方面的数据,不过操作过程中会遇到一些阻拦,今天小编就教大家用sleep间隔进行python反爬虫,这样就可以得到我们想到的数据啦。步骤要利用headers拉动请求,模拟成浏览器去访问网站,跳过最简单的反...
 我们在登山的途中,有不同的路线可以到达终点。因为选择的路线不同,上山的难度也有区别。就像最近几天教大家获取数据的时候,断断续续的讲过header、地址ip等一些的方法。具体的爬取方法相信大家已经掌握住,本篇小编主要是给大家进行应对反爬虫方法的一个梳理,在进行方法回顾的同时查漏补缺,建立系统的爬虫知识框架。首先分析要爬的网站,本质是一个信息查询系统,提供了搜索页面。例如我想获取某个case,需要利用这个case的id...
我们在登山的途中,有不同的路线可以到达终点。因为选择的路线不同,上山的难度也有区别。就像最近几天教大家获取数据的时候,断断续续的讲过header、地址ip等一些的方法。具体的爬取方法相信大家已经掌握住,本篇小编主要是给大家进行应对反爬虫方法的一个梳理,在进行方法回顾的同时查漏补缺,建立系统的爬虫知识框架。首先分析要爬的网站,本质是一个信息查询系统,提供了搜索页面。例如我想获取某个case,需要利用这个case的id...
 在保持合理的数据采集上,使用python爬虫也并不是一件坏事情,因为在信息的交流上加快了流通的频率。今天小编为大家带来了一个稍微复杂一点的应对反爬虫的方法,那就是我们自己构造cookies。在开始正式的构造之前,我们先进行简单的分析如果不构造cookies爬虫时会出现的一些情况,相信这样更能体会出cookies的作用。网站需要cookies才能正常返回,但是该网站的cookies过期很快,我总不能用浏览器开发者工具获取cookies,然后让程序...
在保持合理的数据采集上,使用python爬虫也并不是一件坏事情,因为在信息的交流上加快了流通的频率。今天小编为大家带来了一个稍微复杂一点的应对反爬虫的方法,那就是我们自己构造cookies。在开始正式的构造之前,我们先进行简单的分析如果不构造cookies爬虫时会出现的一些情况,相信这样更能体会出cookies的作用。网站需要cookies才能正常返回,但是该网站的cookies过期很快,我总不能用浏览器开发者工具获取cookies,然后让程序...
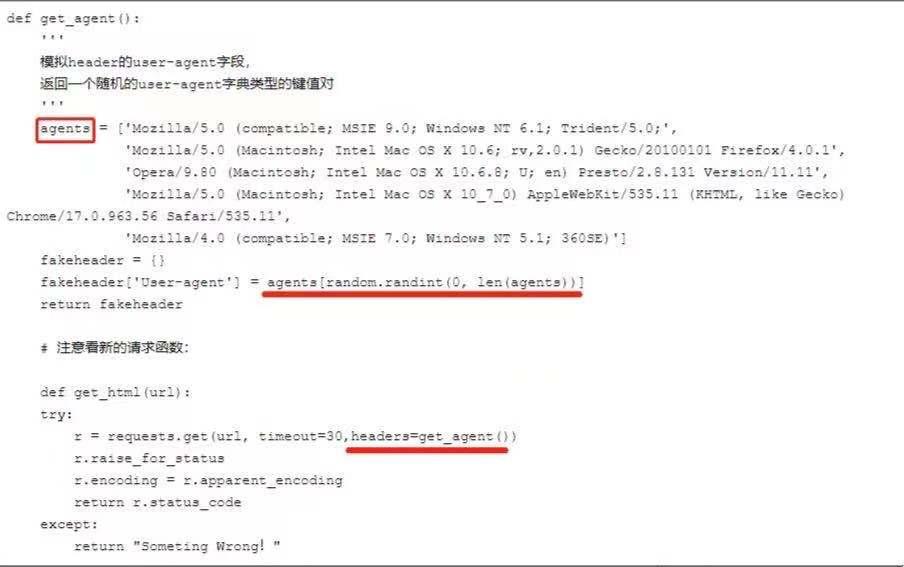 我们选择一种问题的解决办法,通常需要考虑到想要达到的效果,还有最重要的是这个办法本身的优缺点有哪些,与其他的方法对比哪一个更好。之前小编之前也教过大家在python应对反爬虫的方法,那么小伙伴们知道具体情况下选择哪一种办法更适合吗?今天就其中的user-agent和ip代码两个办法进行优缺点分析比较,让大家可以明确不同办法的区别从而进行选择。方法一:可以自己设置一下user-agent,或者更好的是,可以从一系列的user-agent...
我们选择一种问题的解决办法,通常需要考虑到想要达到的效果,还有最重要的是这个办法本身的优缺点有哪些,与其他的方法对比哪一个更好。之前小编之前也教过大家在python应对反爬虫的方法,那么小伙伴们知道具体情况下选择哪一种办法更适合吗?今天就其中的user-agent和ip代码两个办法进行优缺点分析比较,让大家可以明确不同办法的区别从而进行选择。方法一:可以自己设置一下user-agent,或者更好的是,可以从一系列的user-agent...
 在处理问题的之前,给大家个第一个锦囊!你需要将chorme更新到最新版版本84,下载对应的chorme驱动链接:http://chromedriver.storage.googleapis.com/index.html注意划重点!!一定要做这一步,因为我用的83的chorme他是不行滴,~~~~~~~问题1.一周前我的滑块验证代码还是可以OK的,完全没问题!附代码low一眼url="https://login.taobao.com/member/login.jhtml"browser.get(url)browser.maximize_window()#最大化#填写用...
在处理问题的之前,给大家个第一个锦囊!你需要将chorme更新到最新版版本84,下载对应的chorme驱动链接:http://chromedriver.storage.googleapis.com/index.html注意划重点!!一定要做这一步,因为我用的83的chorme他是不行滴,~~~~~~~问题1.一周前我的滑块验证代码还是可以OK的,完全没问题!附代码low一眼url="https://login.taobao.com/member/login.jhtml"browser.get(url)browser.maximize_window()#最大化#填写用...
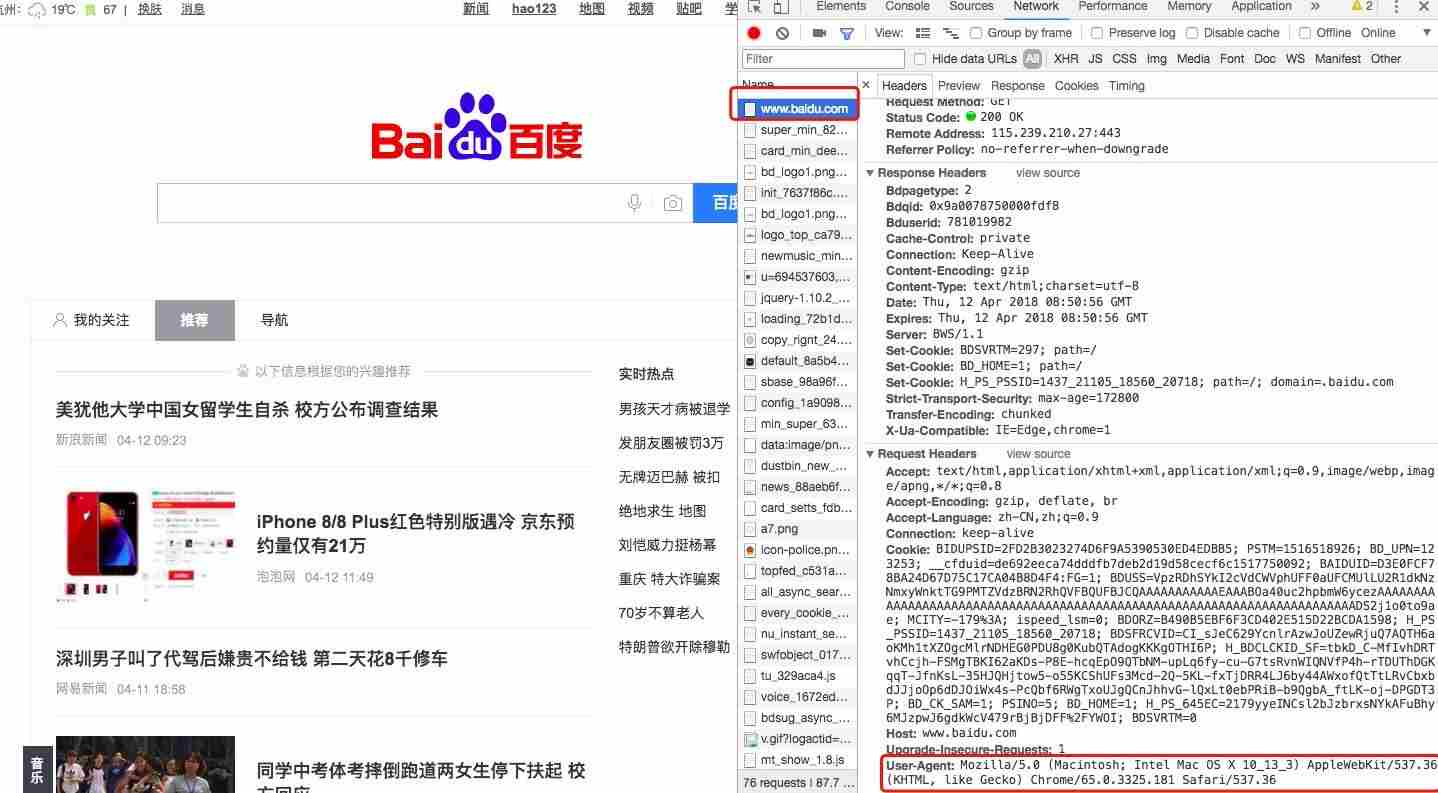 对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作简单的直接添加请求头,将浏览器的信息在请求数据时传入:打开浏览器--打开开发者模式--请求任意网站如下图:找到请求的的名字,打开后查看headers栏,找到User-Agent,复制。然后添加到请求头中代码如下:importrequestsurl='https://www.baidu.com'headers={'User-Agent':'Mozilla...
对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作简单的直接添加请求头,将浏览器的信息在请求数据时传入:打开浏览器--打开开发者模式--请求任意网站如下图:找到请求的的名字,打开后查看headers栏,找到User-Agent,复制。然后添加到请求头中代码如下:importrequestsurl='https://www.baidu.com'headers={'User-Agent':'Mozilla...