
2020
10-08
10-08
pytorch 多分类问题,计算百分比操作
 二分类或分类问题,网络输出为二维矩阵:批次x几分类,最大的为当前分类,标签为one-hot型的二维矩阵:批次x几分类计算百分比有numpy和pytorch两种实现方案实现,都是根据索引计算百分比,以下为具体二分类实现过程。pytorchout=torch.Tensor([[0,3],[2,3],[1,0],[3,4]])cond=torch.Tensor([[1,0],[0,1],[1,0],[1,0]])persent=torch.mean(torch.eq(torch.argmax(out,dim=1),torch.argma...
继续阅读 >
二分类或分类问题,网络输出为二维矩阵:批次x几分类,最大的为当前分类,标签为one-hot型的二维矩阵:批次x几分类计算百分比有numpy和pytorch两种实现方案实现,都是根据索引计算百分比,以下为具体二分类实现过程。pytorchout=torch.Tensor([[0,3],[2,3],[1,0],[3,4]])cond=torch.Tensor([[1,0],[0,1],[1,0],[1,0]])persent=torch.mean(torch.eq(torch.argmax(out,dim=1),torch.argma...
继续阅读 >
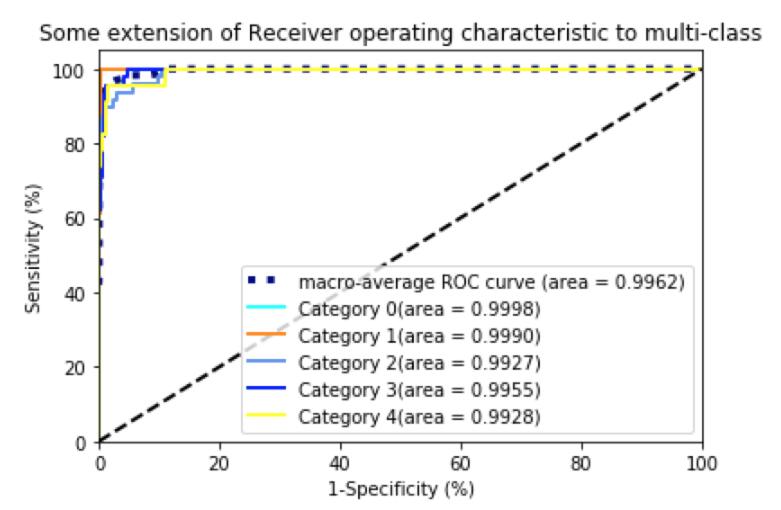
 多分类一种比较常用的做法是在最后一层加softmax归一化,值最大的维度所对应的位置则作为该样本对应的类。本文采用PyTorch框架,选用经典图像数据集mnist学习一波多分类。MNIST数据集MNIST数据集(手写数字数据集)来自美国国家标准与技术研究所,NationalInstituteofStandardsandTechnology(NIST).训练集(trainingset)由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局(theCensusBureau)...
多分类一种比较常用的做法是在最后一层加softmax归一化,值最大的维度所对应的位置则作为该样本对应的类。本文采用PyTorch框架,选用经典图像数据集mnist学习一波多分类。MNIST数据集MNIST数据集(手写数字数据集)来自美国国家标准与技术研究所,NationalInstituteofStandardsandTechnology(NIST).训练集(trainingset)由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局(theCensusBureau)...
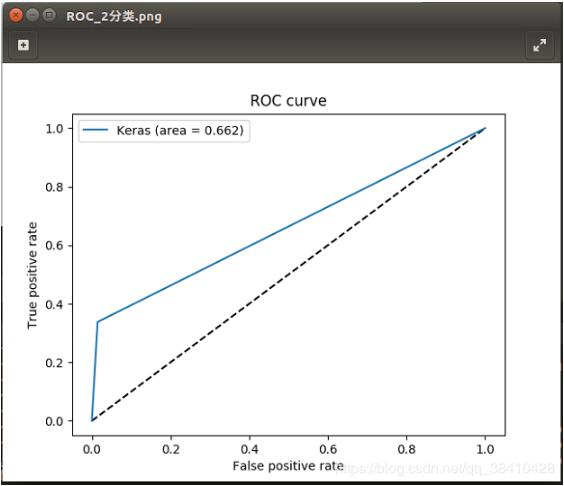 基本概念precision:预测为对的当中,原本为对的比例(越大越好,1为理想状态)recall:原本为对的当中,预测为对的比例(越大越好,1为理想状态)F-measure:F度量是对准确率和召回率做一个权衡(越大越好,1为理想状态,此时precision为1,recall为1)accuracy:预测对的(包括原本是对预测为对,原本是错的预测为错两种情形)占整个的比例(越大越好,1为理想状态)fprate:原本是错的预测为对的比例(越小越好,0为理想状态)...
基本概念precision:预测为对的当中,原本为对的比例(越大越好,1为理想状态)recall:原本为对的当中,预测为对的比例(越大越好,1为理想状态)F-measure:F度量是对准确率和召回率做一个权衡(越大越好,1为理想状态,此时precision为1,recall为1)accuracy:预测对的(包括原本是对预测为对,原本是错的预测为错两种情形)占整个的比例(越大越好,1为理想状态)fprate:原本是错的预测为对的比例(越小越好,0为理想状态)...
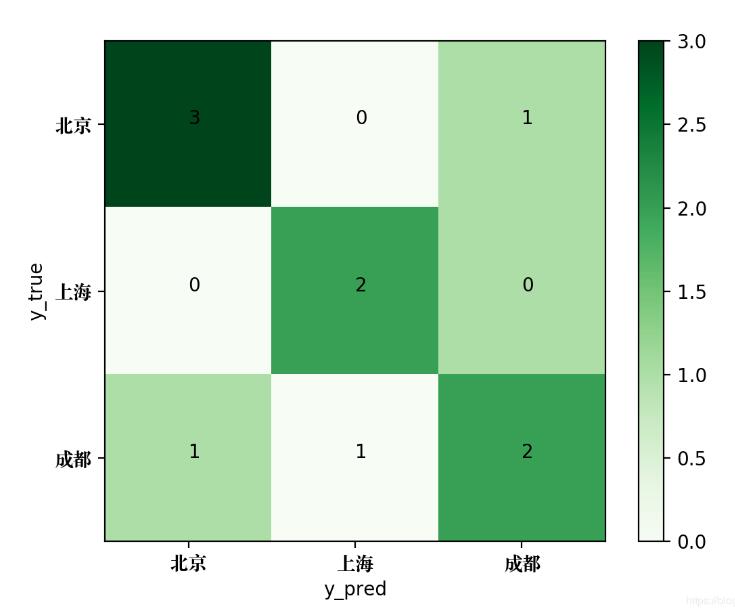 今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score)。对于这个需求,我们可以用sklearn来解决,方法并没有难,笔者在此仅做记录,供自己以后以及读者参考。我们模拟的数据如下:y_true=['北京','上海','成都','成都','上海','北京','上海','成都','北京','上海']y_pred=['北京','上海','成都','...
今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score)。对于这个需求,我们可以用sklearn来解决,方法并没有难,笔者在此仅做记录,供自己以后以及读者参考。我们模拟的数据如下:y_true=['北京','上海','成都','成都','上海','北京','上海','成都','北京','上海']y_pred=['北京','上海','成都','...
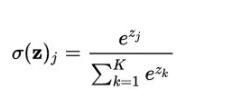 fromkeras.utils.np_utilsimportto_categorical注意:当使用categorical_crossentropy损失函数时,你的标签应为多类模式,例如如果你有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0。可以使用这个方法进行转换:fromkeras.utils.np_utilsimportto_categoricalcategorical_labels=to_categorical(int_labels,num_classes=None)以mnist数据集为例:fromkeras.datasetsimportm...
fromkeras.utils.np_utilsimportto_categorical注意:当使用categorical_crossentropy损失函数时,你的标签应为多类模式,例如如果你有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0。可以使用这个方法进行转换:fromkeras.utils.np_utilsimportto_categoricalcategorical_labels=to_categorical(int_labels,num_classes=None)以mnist数据集为例:fromkeras.datasetsimportm...