
2020
09-24
09-24
Python基于requests库爬取网站信息
 requests库是一个简介且简单的处理HTTP请求的第三方库get()是获取网页最常用的方式,其基本使用方式如下使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML下面这段代码便是爬取百度的信息并简单输出百度的界面信息importrequestsfrombs4importBeautifulSoupr=requests.get('http://www.baidu.com')r.encoding=Noneresult=r.textbs=B...
继续阅读 >
requests库是一个简介且简单的处理HTTP请求的第三方库get()是获取网页最常用的方式,其基本使用方式如下使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML下面这段代码便是爬取百度的信息并简单输出百度的界面信息importrequestsfrombs4importBeautifulSoupr=requests.get('http://www.baidu.com')r.encoding=Noneresult=r.textbs=B...
继续阅读 >
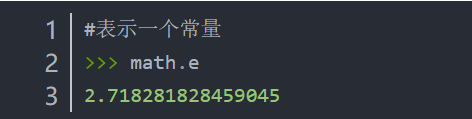 首先我们应当了解什么是math库:math库是python提供的内置数学类函数库,math库不支持复数类型,仅支持整数和浮点数运算。math库一共提供了4个数字常数和44个函数。44个函数共分为4类,包括16个数值表示函数,8个幂对数函数,16个三角对数函数和4个高等特殊函数。#有一点需要注意:math库中的函数不能直接使用,需要先使用保留字import引用该库。如下:(1)importmath(2)frommathimport<函数名>math.<b>(...)<函数名>(...)...
首先我们应当了解什么是math库:math库是python提供的内置数学类函数库,math库不支持复数类型,仅支持整数和浮点数运算。math库一共提供了4个数字常数和44个函数。44个函数共分为4类,包括16个数值表示函数,8个幂对数函数,16个三角对数函数和4个高等特殊函数。#有一点需要注意:math库中的函数不能直接使用,需要先使用保留字import引用该库。如下:(1)importmath(2)frommathimport<函数名>math.<b>(...)<函数名>(...)...
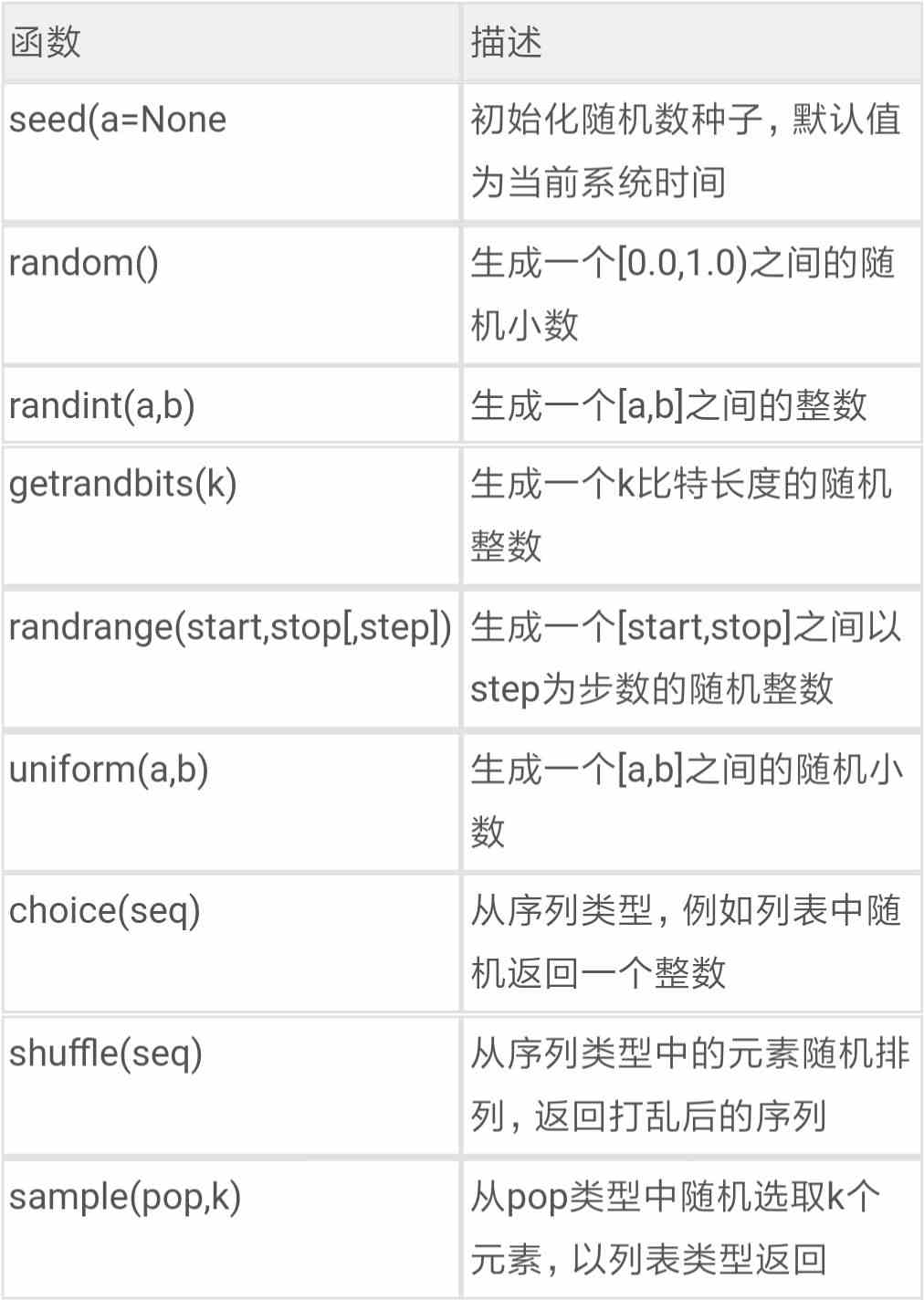 1.random库的使用:random库是使用随机数的Python标准库从概率论角度来说,随机数是随机产生的数据(比如抛硬币),但时计算机是不可能产生随机值,真正的随机数也是在特定条件下产生的确定值,只不过这些条件我们没有理解,或者超出了我们的理解范围。计算机不能产生真正的随机数,那么伪随机数也就被称为随机数--伪随机数:计算机中通过采用梅森旋转算法生成的(伪)随机序列元素python中用于生成伪随机数的函数库是random因为是...
1.random库的使用:random库是使用随机数的Python标准库从概率论角度来说,随机数是随机产生的数据(比如抛硬币),但时计算机是不可能产生随机值,真正的随机数也是在特定条件下产生的确定值,只不过这些条件我们没有理解,或者超出了我们的理解范围。计算机不能产生真正的随机数,那么伪随机数也就被称为随机数--伪随机数:计算机中通过采用梅森旋转算法生成的(伪)随机序列元素python中用于生成伪随机数的函数库是random因为是...