
2021
07-04
07-04
如何用python抓取B站数据
目录概述我是对比快速开始1)安装过程2)获取弹幕数据3)绘制词云4)最终效果小结概述可以获取的数据包括:video-视频模块user-用户模块dynamic-动态模块这次用“RunningMan”十周年特辑的视频,来做个获取弹幕的Demo。我是对比没有对比,就没有伤害,就像最近的“哈工大”某学生和“浙大”某学生一样。这是之前获取弹幕的过程:1、弹幕数据接口https://comment.bilibili.com/123072475.xml(一个固定的url地址+视频的cid+.xm...
继续阅读 >
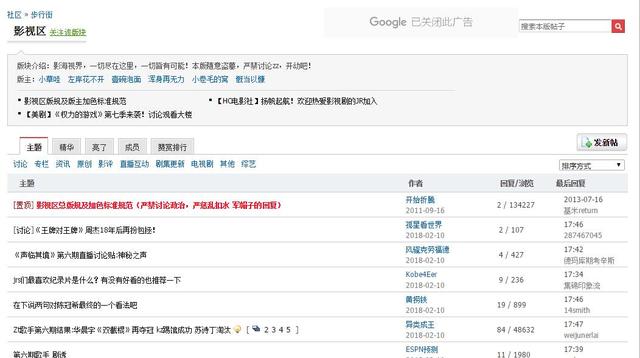 前言:之前学习了用python爬虫的基本知识,现在计划用爬虫去做一些实际的数据统计功能。由于前段时间演员的诞生带火了几个年轻的实力派演员,想用爬虫程序搜索某论坛中对于某些演员的讨论热度,并按照日期统计每天的讨论量。这个项目总共分为两步:1.获取所有帖子的链接:将最近一个月内的帖子链接保存到数组中2.从回帖中搜索演员名字:从数组中打开链接,翻出该链接的所有回帖,在回帖中查找演员的名字获取所有帖子的链接:搜索的...
前言:之前学习了用python爬虫的基本知识,现在计划用爬虫去做一些实际的数据统计功能。由于前段时间演员的诞生带火了几个年轻的实力派演员,想用爬虫程序搜索某论坛中对于某些演员的讨论热度,并按照日期统计每天的讨论量。这个项目总共分为两步:1.获取所有帖子的链接:将最近一个月内的帖子链接保存到数组中2.从回帖中搜索演员名字:从数组中打开链接,翻出该链接的所有回帖,在回帖中查找演员的名字获取所有帖子的链接:搜索的...
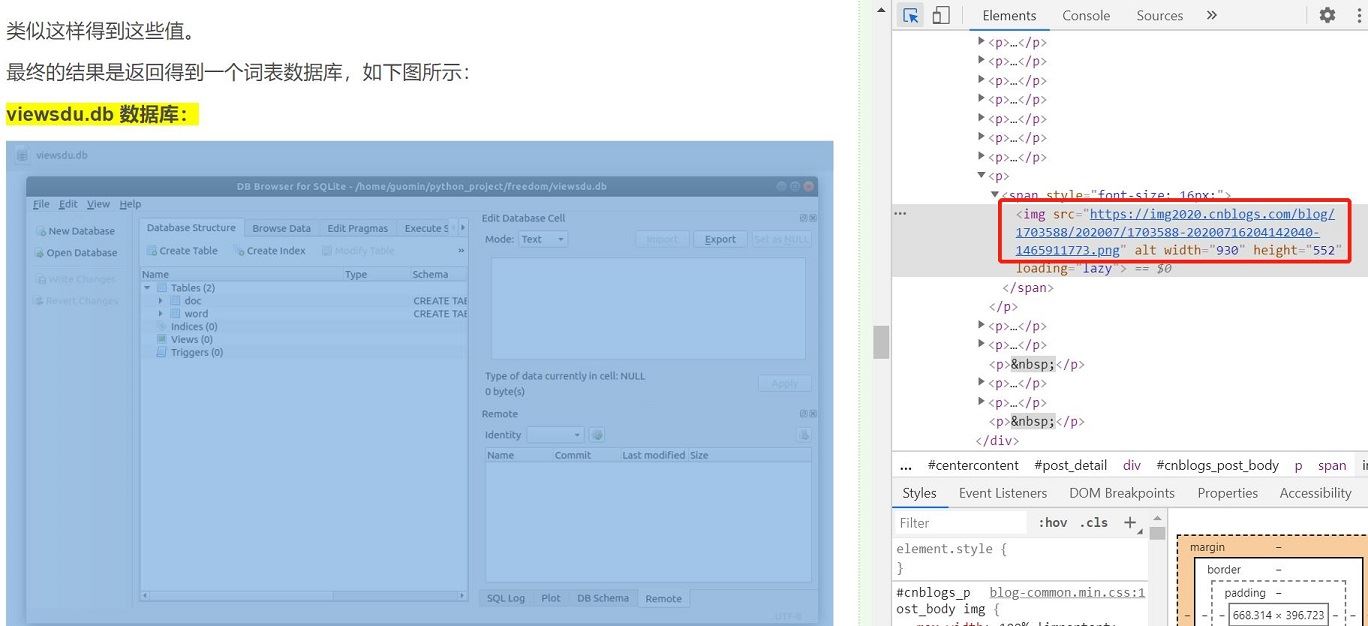 想要爬取指定网页中的图片主要需要以下三个步骤:(1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键->Inspect->Elements中的html内容)(2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容(3)设置循环列表,重复抓取和保存内容以下介绍了两种方法实现抓取指定网页中图片(1)方法一:使用正则表达式过滤抓到的html内容字符串#第一个简单的爬取图片的程序importurllib.request#pyt...
想要爬取指定网页中的图片主要需要以下三个步骤:(1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键->Inspect->Elements中的html内容)(2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容(3)设置循环列表,重复抓取和保存内容以下介绍了两种方法实现抓取指定网页中图片(1)方法一:使用正则表达式过滤抓到的html内容字符串#第一个简单的爬取图片的程序importurllib.request#pyt...
 今天闲着没事,用selenium抓取视频保存到本地,只爬取了第一页,只要小于等于5分钟的视频。。。为什么不用requests,没有为什么,就因为有些网站正则和xpath都提取不出来想要的东西,要么就是接口出来的数据加密,要么就因为真正的视频url规律难找!selenium几行代码轻轻松松就搞定!安装selenium库,设置无界面模式代码如下:fromseleniumimportwebdriverfromselenium.webdriver.chrome.optionsimportOptionsimportrequest...
今天闲着没事,用selenium抓取视频保存到本地,只爬取了第一页,只要小于等于5分钟的视频。。。为什么不用requests,没有为什么,就因为有些网站正则和xpath都提取不出来想要的东西,要么就是接口出来的数据加密,要么就因为真正的视频url规律难找!selenium几行代码轻轻松松就搞定!安装selenium库,设置无界面模式代码如下:fromseleniumimportwebdriverfromselenium.webdriver.chrome.optionsimportOptionsimportrequest...