
2021
09-04
09-04
pandas数据处理清洗实现中文地址拆分案例
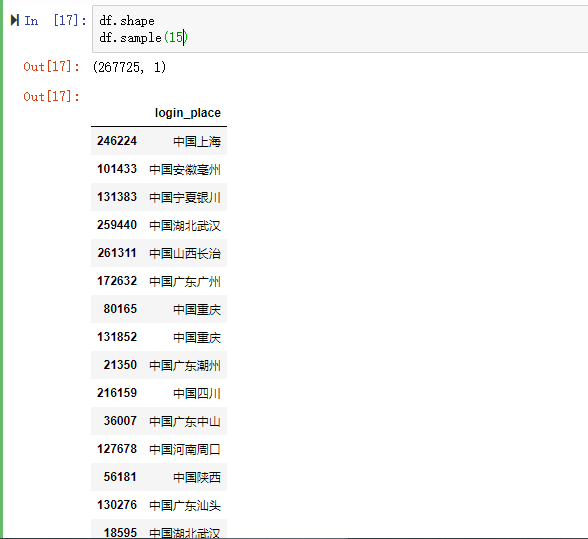 目录一、案例场景二、初步方案三、优化方案一、案例场景字段login_place,一共267725行记录,随机15条记录如下: 后续数据分析工作需要用到地理维度进行分析,所以需要把login_place字段进行拆分成:国家、省份、地区。二、初步方案 第三方中文分词库:jieba,可以对文本进行拆分。使用参考资料:jieba库的使用。初步方案:用jieba.cut()将文本拆分为单词列表list_word;分支判断list_word长度,...
继续阅读 >
目录一、案例场景二、初步方案三、优化方案一、案例场景字段login_place,一共267725行记录,随机15条记录如下: 后续数据分析工作需要用到地理维度进行分析,所以需要把login_place字段进行拆分成:国家、省份、地区。二、初步方案 第三方中文分词库:jieba,可以对文本进行拆分。使用参考资料:jieba库的使用。初步方案:用jieba.cut()将文本拆分为单词列表list_word;分支判断list_word长度,...
继续阅读 >
 背景业务场景中经常会有各种大key多key的情况,比如:1:单个简单的key存储的value很大2:hash,set,zset,list中存储过多的元素(以万为单位)3:一个集群存储了上亿的key,Key本身过多也带来了更多的空间占用(如无意外,文章中所提及的hash,set等数据结构均指redis中的数据结构)由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案...
背景业务场景中经常会有各种大key多key的情况,比如:1:单个简单的key存储的value很大2:hash,set,zset,list中存储过多的元素(以万为单位)3:一个集群存储了上亿的key,Key本身过多也带来了更多的空间占用(如无意外,文章中所提及的hash,set等数据结构均指redis中的数据结构)由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案...
 对于一些特殊的情况,split拆分后并没有保留全的元素如下例子:Stringx="a,,,,,,";String[]y=x.split(",");for(inti=0;i<y.length;i++){System.out.println(y[i]);}输出结果:只拆分得到了第一个字母,后面默认的空字符串并没有保留。后来想到了使用StringUtils函数,查了一下,修改为如下:Stringx="a,,,,,,";Stringy[]=StringUtils.splitPreserveAllTokens(x,",");for(inti=0;i<y.length;i++){System.out.printl...
对于一些特殊的情况,split拆分后并没有保留全的元素如下例子:Stringx="a,,,,,,";String[]y=x.split(",");for(inti=0;i<y.length;i++){System.out.println(y[i]);}输出结果:只拆分得到了第一个字母,后面默认的空字符串并没有保留。后来想到了使用StringUtils函数,查了一下,修改为如下:Stringx="a,,,,,,";Stringy[]=StringUtils.splitPreserveAllTokens(x,",");for(inti=0;i<y.length;i++){System.out.printl...
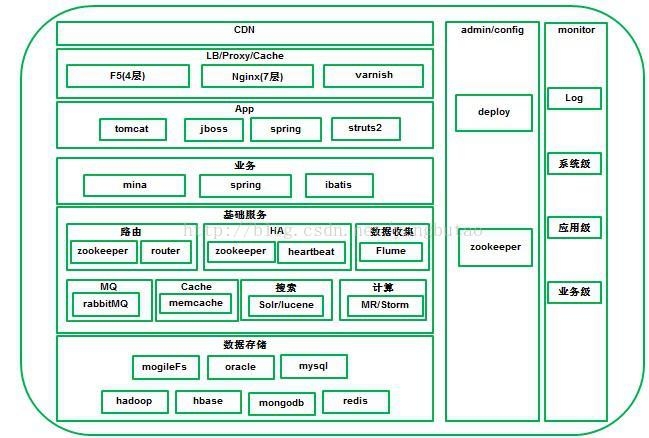 空间换时间多级缓存,静态化客户端页面缓存(httpheader中包含Expires/CacheofControl,lastmodified(304,server不返回body,客户端可以继续用cache,减少流量),ETag)反向代理缓存应用端的缓存(memcache)内存数据库Buffer、cache机制(数据库,中间件等)索引哈希、B树、倒排、bitmap哈希索引适合综合数组的寻址和链表的插入特性,可以实现数据的快速存取。B树索引适合于查询为主导的场景,避免多次的IO,提高查...
空间换时间多级缓存,静态化客户端页面缓存(httpheader中包含Expires/CacheofControl,lastmodified(304,server不返回body,客户端可以继续用cache,减少流量),ETag)反向代理缓存应用端的缓存(memcache)内存数据库Buffer、cache机制(数据库,中间件等)索引哈希、B树、倒排、bitmap哈希索引适合综合数组的寻址和链表的插入特性,可以实现数据的快速存取。B树索引适合于查询为主导的场景,避免多次的IO,提高查...