
2020
09-28
09-28
Pytorch数据拼接与拆分操作实现图解
 1、cat:拼接直接合并数据2、stack拼接:与cat不同的是,stack创建了一个新的维度,在拼接的同时,给数据增加了类别。并且stack的所有数据维度必须一致。3、split拆分:通过数据长度进行拆分4、chunk拆分:与split不同的是:chunk是指定拆分的个数,将数据拆分为指定个数。以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。...
继续阅读 >
1、cat:拼接直接合并数据2、stack拼接:与cat不同的是,stack创建了一个新的维度,在拼接的同时,给数据增加了类别。并且stack的所有数据维度必须一致。3、split拆分:通过数据长度进行拆分4、chunk拆分:与split不同的是:chunk是指定拆分的个数,将数据拆分为指定个数。以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。...
继续阅读 >
 在做数据分析或者统计的时候,经常需要进行数据正态性的检验,因为很多假设都是基于正态分布的基础之上的,例如:T检验。在Python中,主要有以下检验正态性的方法:1.scipy.stats.shapiro——Shapiro-Wilktest,属于专门用来做正态性检验的模块,其原假设:样本数据符合正态分布。注:适用于小样本。其函数定位为:defshapiro(x):"""PerformtheShapiro-Wilktestfornormality.TheShapiro-Wilktestteststhenullh...
在做数据分析或者统计的时候,经常需要进行数据正态性的检验,因为很多假设都是基于正态分布的基础之上的,例如:T检验。在Python中,主要有以下检验正态性的方法:1.scipy.stats.shapiro——Shapiro-Wilktest,属于专门用来做正态性检验的模块,其原假设:样本数据符合正态分布。注:适用于小样本。其函数定位为:defshapiro(x):"""PerformtheShapiro-Wilktestfornormality.TheShapiro-Wilktestteststhenullh...
 python部分defmallTemplateConfig(request):gameRole_edit=request.session.get('gameRole_edit',[])#获取json串returnrender(request,"operationGL/mallTemplateConfig.html",{'gameRole_edit':json.dumps(gameRole_edit)})html部分这样写显示正常,没有问题<label>{{gameRole_edit}}</label>js部分这样写json串中的双引号,会被转义成"console.log("{{gameRole_edit}}")用下面...
python部分defmallTemplateConfig(request):gameRole_edit=request.session.get('gameRole_edit',[])#获取json串returnrender(request,"operationGL/mallTemplateConfig.html",{'gameRole_edit':json.dumps(gameRole_edit)})html部分这样写显示正常,没有问题<label>{{gameRole_edit}}</label>js部分这样写json串中的双引号,会被转义成"console.log("{{gameRole_edit}}")用下面...
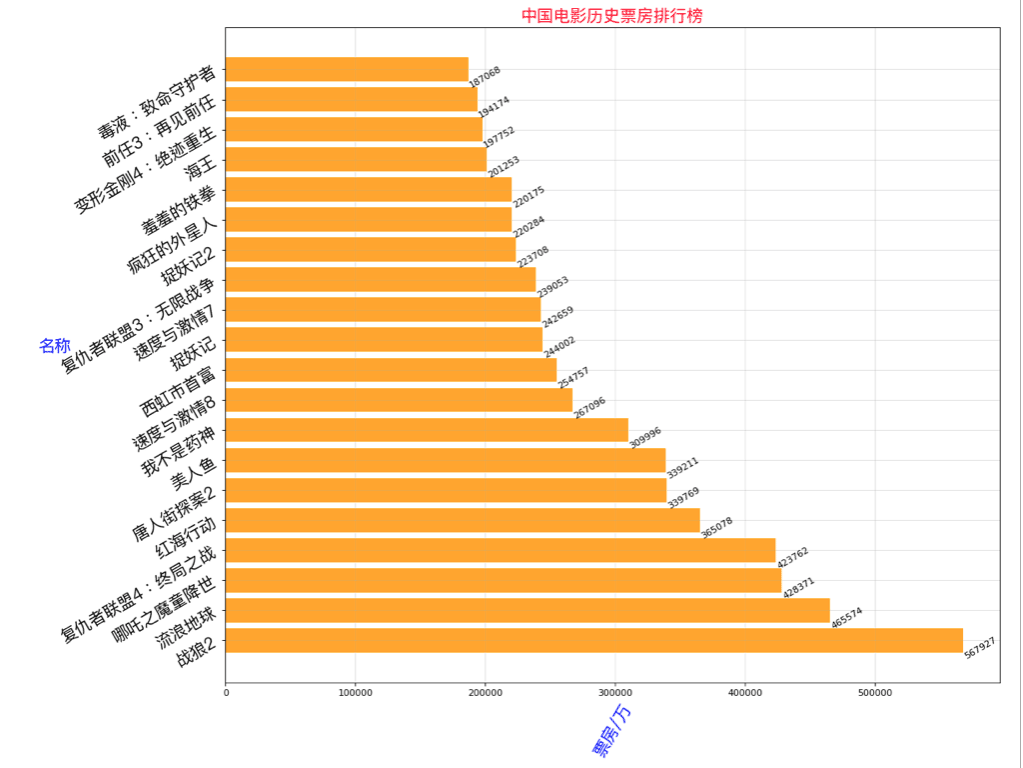 本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:爬虫电影历史票房排行榜http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0Python爬取历史电影票房纪录解析Json数据横向条形图展示面向对象思想导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportjson类代码部分classDYOrder(object):#初始化def...
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:爬虫电影历史票房排行榜http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0Python爬取历史电影票房纪录解析Json数据横向条形图展示面向对象思想导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportjson类代码部分classDYOrder(object):#初始化def...
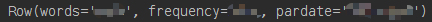 parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。首先,导入库文件和配置环境:importosfrompysparki...
parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。首先,导入库文件和配置环境:importosfrompysparki...
 1前言很多程序都要求用户输入某种信息,程序一般将信息存储在列表和字典等数据结构中。用户关闭程序时,就需要将信息进行保存,一种简单的方式是使用模块json来存储数据。模块json让你能够将简单的Python数据结构转存到文件中,并在程序再次运行时加载该文件中的数据。还可以使用json在Python程序之间分享数据,更重要的是,JSON(JavaScriptObjectNotation,最初由JavaScript开发)格式的数据文件能被很多编程语言兼容。2使用...
1前言很多程序都要求用户输入某种信息,程序一般将信息存储在列表和字典等数据结构中。用户关闭程序时,就需要将信息进行保存,一种简单的方式是使用模块json来存储数据。模块json让你能够将简单的Python数据结构转存到文件中,并在程序再次运行时加载该文件中的数据。还可以使用json在Python程序之间分享数据,更重要的是,JSON(JavaScriptObjectNotation,最初由JavaScript开发)格式的数据文件能被很多编程语言兼容。2使用...