
2021
08-12
08-12
python 爬取国内小说网站
目录原理先行实践篇完整代码原理先行作为一个资深的小说爱好者,国内很多小说网站如出一辙,什么🖊*阁啊等等,大都是get请求返回html内容,而且会有标志性的<dl><dd>等标签。所以大概的原理,就是先get请求这个网站,然后对获取的内容进行清洗,写进文本里面,变成一个txt,导入手机,方便看小说。实践篇之前踩过一个坑,一开始我看了几页小说,大概小说的内容网站是https://www.xxx.com/小说编号/章节编号.html,...
继续阅读 >
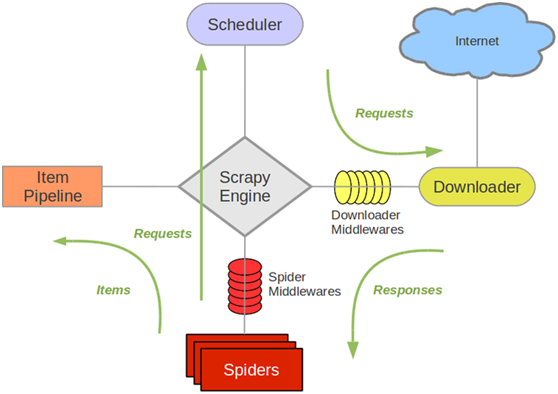 scrapy是目前python使用的最广泛的爬虫框架架构图如下解释:ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载ScrapyEngine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给ScrapyEngine(引擎)...
scrapy是目前python使用的最广泛的爬虫框架架构图如下解释:ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载ScrapyEngine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给ScrapyEngine(引擎)...