
2020
09-25
09-25
Java爬取豆瓣电影数据的方法详解
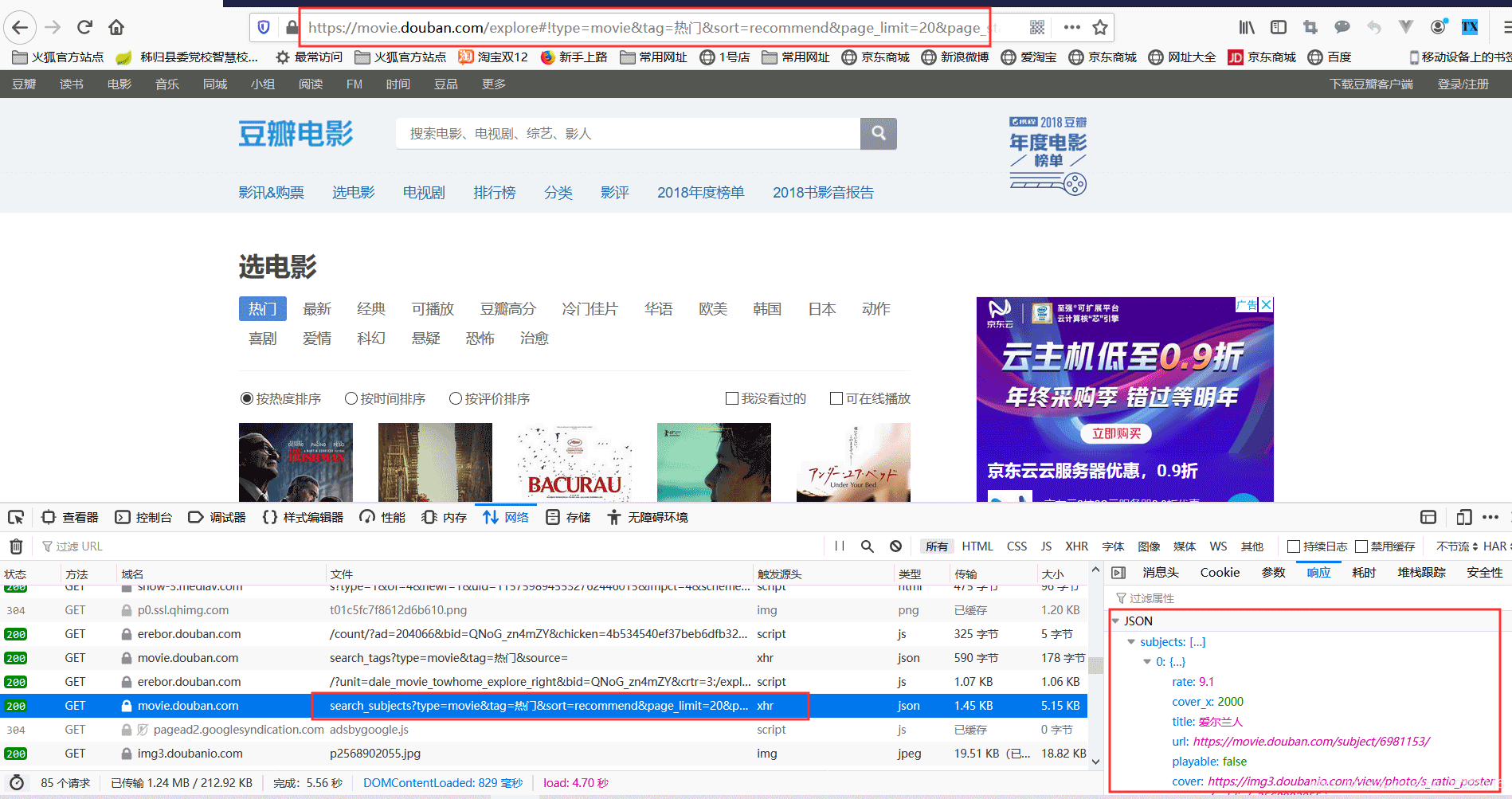 本文实例讲述了Java爬取豆瓣电影数据的方法。分享给大家供大家参考,具体如下:所用到的技术有Jsoup,HttpClient。Jsoupjsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。HttpClientHTTP协议可能是现在Internet上使用得最多、最重要的协议了,越来越多的Java应用程序需要直接通过HTTP协议来访问网络资源。虽然...
继续阅读 >
本文实例讲述了Java爬取豆瓣电影数据的方法。分享给大家供大家参考,具体如下:所用到的技术有Jsoup,HttpClient。Jsoupjsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。HttpClientHTTP协议可能是现在Internet上使用得最多、最重要的协议了,越来越多的Java应用程序需要直接通过HTTP协议来访问网络资源。虽然...
继续阅读 >
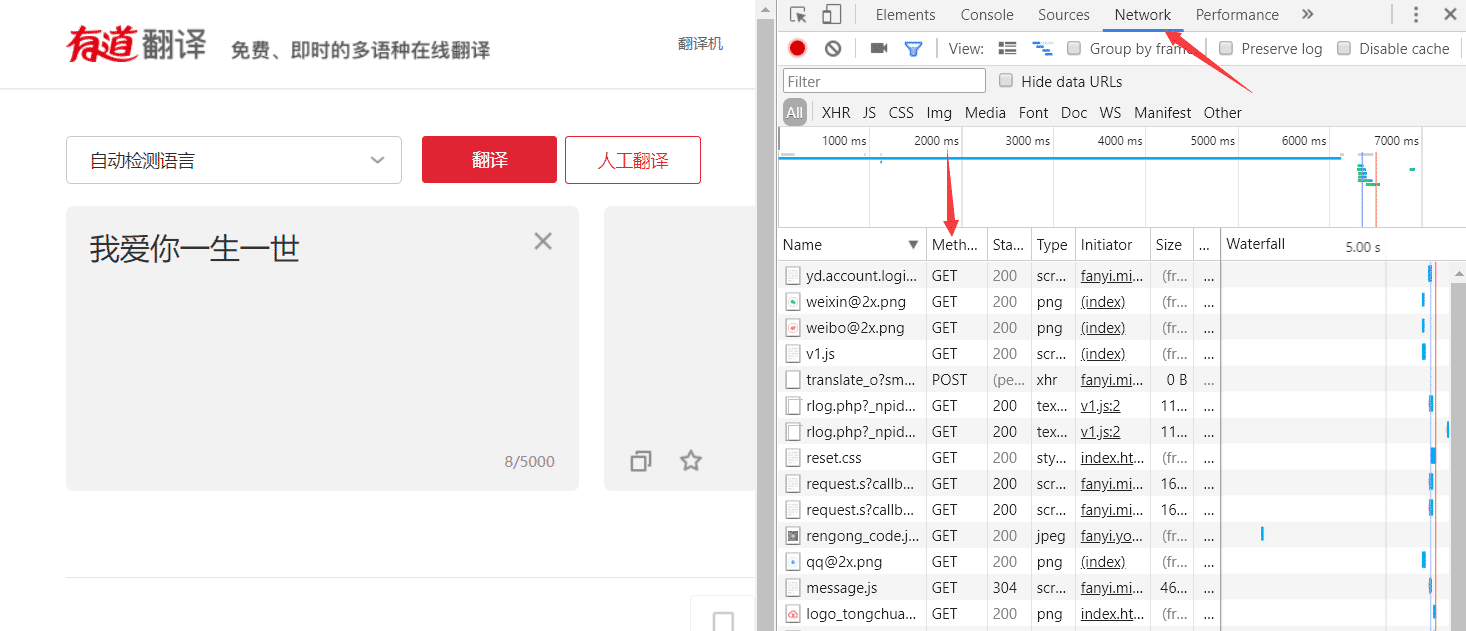 1.准备工作先来到有道在线翻译的界面http://fanyi.youdao.com/F12审查元素->选Network一栏,然后F5刷新(如果看不到Method一栏,右键Name栏,选中Method)输入文字自动翻译后发现Method一栏有GET还有POST;GET是指从服务器请求和获得数据,POST是向指定服务器提交被处理的数据、随便打开一个POST,找到preview可以看到我们输入的“我爱你一生一世”数据,可以证明post的提交数据的下面分析一下Headers各个字段的意义;User-agent...
1.准备工作先来到有道在线翻译的界面http://fanyi.youdao.com/F12审查元素->选Network一栏,然后F5刷新(如果看不到Method一栏,右键Name栏,选中Method)输入文字自动翻译后发现Method一栏有GET还有POST;GET是指从服务器请求和获得数据,POST是向指定服务器提交被处理的数据、随便打开一个POST,找到preview可以看到我们输入的“我爱你一生一世”数据,可以证明post的提交数据的下面分析一下Headers各个字段的意义;User-agent...
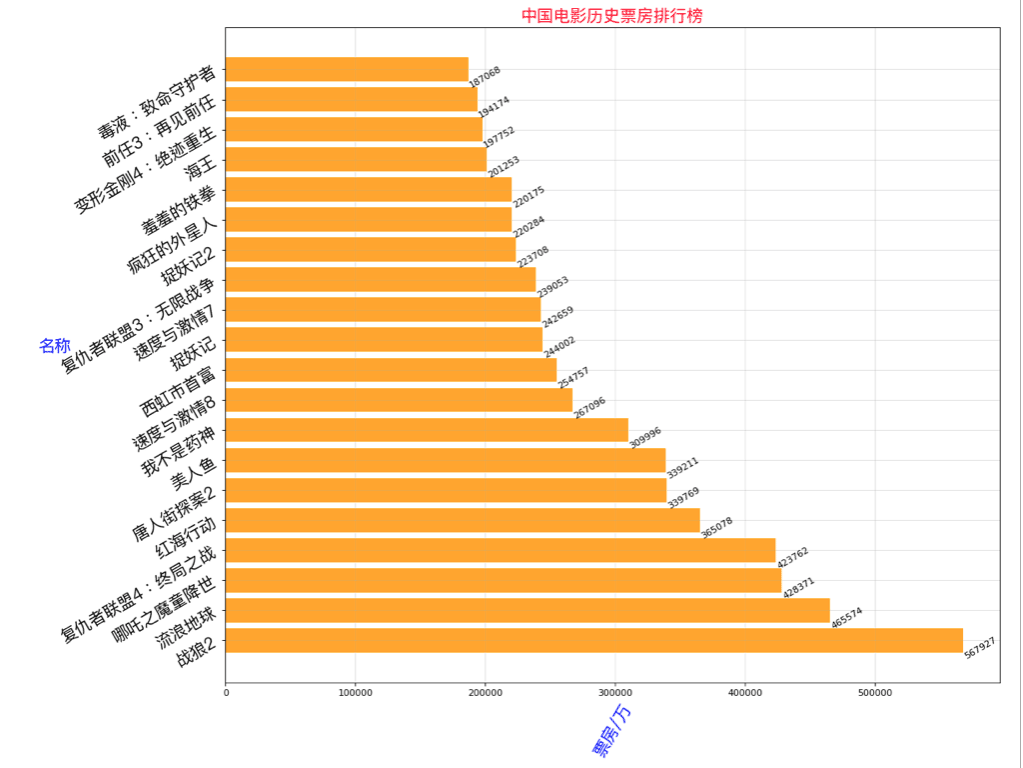 本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:爬虫电影历史票房排行榜http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0Python爬取历史电影票房纪录解析Json数据横向条形图展示面向对象思想导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportjson类代码部分classDYOrder(object):#初始化def...
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:爬虫电影历史票房排行榜http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0Python爬取历史电影票房纪录解析Json数据横向条形图展示面向对象思想导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportjson类代码部分classDYOrder(object):#初始化def...
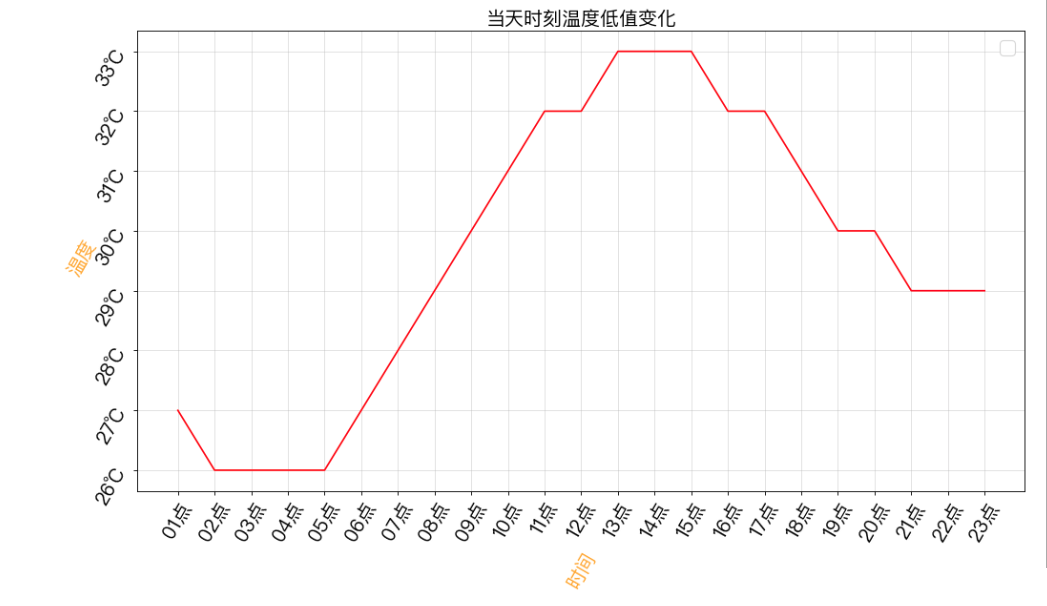 本文实例讲述了Python爬虫爬取杭州24时温度并展示操作。分享给大家供大家参考,具体如下:散点图爬虫杭州今日24时温度https://www.baidutianqi.com/today/58457.htm利用正则表达式爬取杭州温度面向对象编程图表展示(散点图/折线图)导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportmatplotlib类代码部分classWeather(object):def__init__(self):...
本文实例讲述了Python爬虫爬取杭州24时温度并展示操作。分享给大家供大家参考,具体如下:散点图爬虫杭州今日24时温度https://www.baidutianqi.com/today/58457.htm利用正则表达式爬取杭州温度面向对象编程图表展示(散点图/折线图)导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportmatplotlib类代码部分classWeather(object):def__init__(self):...
 此文仅当学习笔记用.这个实例是在Python环境下如何爬取弹出窗口的内容,有些时候我们要在页面中通过点击,然后在弹出窗口中才有我们要的信息,所以平常用的方法也许不行.这里我用到的是Selenium这个工具,不知道的朋友可以去搜索一下.但是安装也是很费事的.而且我用的浏览器是firefox,不用IE是因为好像新版的IE在Selenium下有问题,我也是百思不得其解,网上也暂时没找到好的办法.fromseleniumimportwebdriverfromselenium.webdr...
此文仅当学习笔记用.这个实例是在Python环境下如何爬取弹出窗口的内容,有些时候我们要在页面中通过点击,然后在弹出窗口中才有我们要的信息,所以平常用的方法也许不行.这里我用到的是Selenium这个工具,不知道的朋友可以去搜索一下.但是安装也是很费事的.而且我用的浏览器是firefox,不用IE是因为好像新版的IE在Selenium下有问题,我也是百思不得其解,网上也暂时没找到好的办法.fromseleniumimportwebdriverfromselenium.webdr...
 requests库是一个简介且简单的处理HTTP请求的第三方库get()是获取网页最常用的方式,其基本使用方式如下使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML下面这段代码便是爬取百度的信息并简单输出百度的界面信息importrequestsfrombs4importBeautifulSoupr=requests.get('http://www.baidu.com')r.encoding=Noneresult=r.textbs=B...
requests库是一个简介且简单的处理HTTP请求的第三方库get()是获取网页最常用的方式,其基本使用方式如下使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML下面这段代码便是爬取百度的信息并简单输出百度的界面信息importrequestsfrombs4importBeautifulSoupr=requests.get('http://www.baidu.com')r.encoding=Noneresult=r.textbs=B...
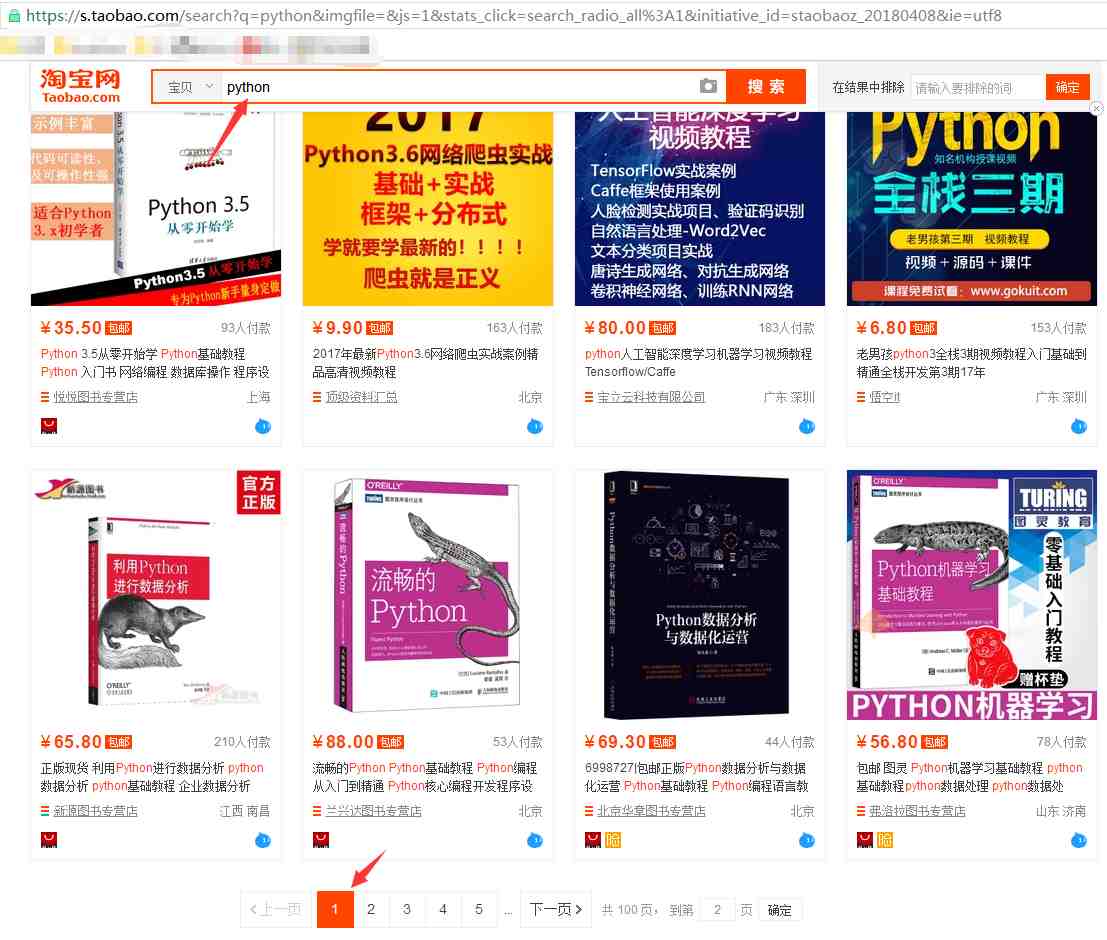 使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象我们在淘宝里搜索“python”,出来的结果从url连接中可以得到搜索商品的关键字是“q=”,所以我们要用的起始url为:https://s.taobao.com/search?q=python然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44)所以可以根据关键字“s=”,来设置爬取的深度(爬取多少页)右键查看源码,...
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象我们在淘宝里搜索“python”,出来的结果从url连接中可以得到搜索商品的关键字是“q=”,所以我们要用的起始url为:https://s.taobao.com/search?q=python然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44)所以可以根据关键字“s=”,来设置爬取的深度(爬取多少页)右键查看源码,...
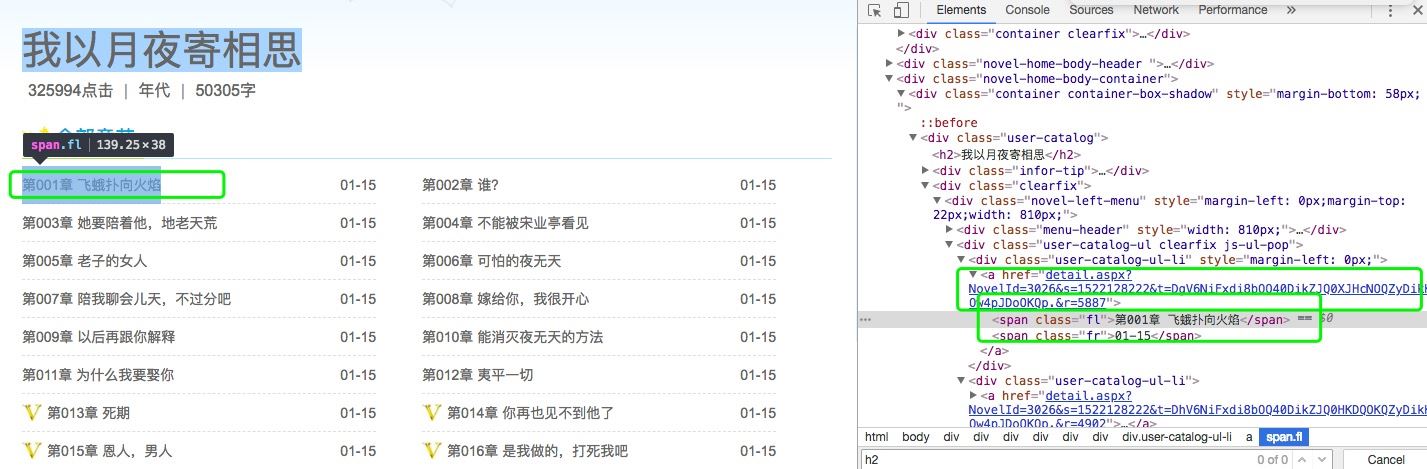 需要转载的小伙伴转载后请注明转载的地址需要用到的库frombs4importBeautifulSoupimportrequestsimporttime365好书链接:http://www.365haoshu.com/爬取《我以月夜寄相思》小说首页进入到目录:http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=3026获取小说的每个章节的名称和章节链接打开浏览器的开发者工具,查找一个章节:如下图,找到第一章的名称和href(也就是第一章节内容页面的链接),开始写代...
需要转载的小伙伴转载后请注明转载的地址需要用到的库frombs4importBeautifulSoupimportrequestsimporttime365好书链接:http://www.365haoshu.com/爬取《我以月夜寄相思》小说首页进入到目录:http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=3026获取小说的每个章节的名称和章节链接打开浏览器的开发者工具,查找一个章节:如下图,找到第一章的名称和href(也就是第一章节内容页面的链接),开始写代...