
2021
01-29
01-29
Python爬取梨视频的示例
爬取流程(美食区最热标签下的三个视频)在首页获取视频的编号和名字拼接成正确的url保存视频思路1.从网页中获取视频的url发现视频的url在id为“JprismPlayer”的div标签下的video标签src属性中,xpath解析网页video_url=tree.xpath("//div[@id='JprismPlayer']/video/@src")但得到的返回值为空,也就是说这个video标签在原网页中并不存在,很可能是动态加载出来的2.从动态请求获取视频的url果然在动态请求中发现了包含...
继续阅读 >
 之所以把selenium爬虫称之为可视化爬虫主要是相较于前面所提到的几种网页解析的爬虫方式selenium爬虫主要是模拟人的点击操作selenium驱动浏览器并进行操作的过程是可以观察到的就类似于你在看着别人在帮你操纵你的电脑,类似于别人远程使用你的电脑当然了,selenium也有无界面模式快速入门selenium基本介绍:selenium是一套完整的web应用程序测试系统,包含了测试的录制(seleniumIDE),编写及运行(SeleniumRemoteControl)和...
之所以把selenium爬虫称之为可视化爬虫主要是相较于前面所提到的几种网页解析的爬虫方式selenium爬虫主要是模拟人的点击操作selenium驱动浏览器并进行操作的过程是可以观察到的就类似于你在看着别人在帮你操纵你的电脑,类似于别人远程使用你的电脑当然了,selenium也有无界面模式快速入门selenium基本介绍:selenium是一套完整的web应用程序测试系统,包含了测试的录制(seleniumIDE),编写及运行(SeleniumRemoteControl)和...
 一、Jsoup爬虫jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。以博客园首页为例1、idea新建maven工程pom.xml导入jsoup依赖<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.12.1</version></dependency>jsoup代码packagecom.blb;importorg.jsoup.Jsoup;importorg.js...
一、Jsoup爬虫jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。以博客园首页为例1、idea新建maven工程pom.xml导入jsoup依赖<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.12.1</version></dependency>jsoup代码packagecom.blb;importorg.jsoup.Jsoup;importorg.js...
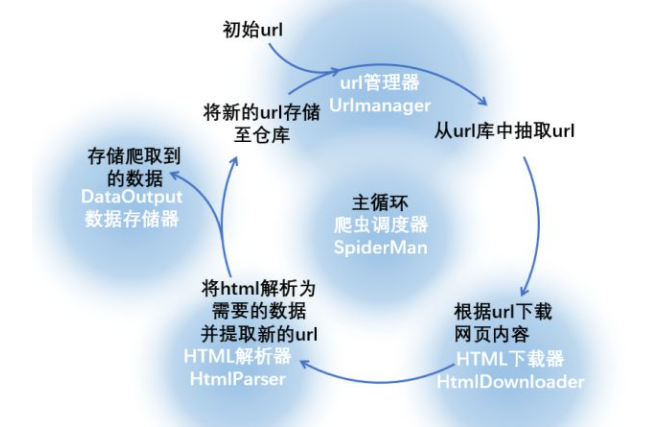 我们一般使用爬虫看到的都是最后的数据结果,对于整个的获取过程没有过多了解过。对于初学python的小伙伴们来说,不光是代码的练习,还是原理的分析都是必不可少的。小编把整个爬取的过程分为了几个部分,从一开始的下载,到数据的去重解析,再到整个爬虫循环的结束,以图片和代码的双重形式展现给大家,希望能够对爬虫调度器有一个深刻的理解。我们可以编写几个元件,每个元件完成一项功能,下图中的蓝底白字就是对这一流程的抽象...
我们一般使用爬虫看到的都是最后的数据结果,对于整个的获取过程没有过多了解过。对于初学python的小伙伴们来说,不光是代码的练习,还是原理的分析都是必不可少的。小编把整个爬取的过程分为了几个部分,从一开始的下载,到数据的去重解析,再到整个爬虫循环的结束,以图片和代码的双重形式展现给大家,希望能够对爬虫调度器有一个深刻的理解。我们可以编写几个元件,每个元件完成一项功能,下图中的蓝底白字就是对这一流程的抽象...
 一介绍Python上有一个非常著名的HTTP库——requests,相信大家都听说过,用过的人都说非常爽!现在requests库的作者又发布了一个新库,叫做requests-html,看名字也能猜出来,这是一个解析HTML的库,具备requests的功能以外,还新增了一些更加强大的功能,用起来比requests更爽!接下来我们来介绍一下它吧。#官网解释'''ThislibraryintendstomakeparsingHTML(e.g.scrapingtheweb)assimpleandintuitiveasposs...
一介绍Python上有一个非常著名的HTTP库——requests,相信大家都听说过,用过的人都说非常爽!现在requests库的作者又发布了一个新库,叫做requests-html,看名字也能猜出来,这是一个解析HTML的库,具备requests的功能以外,还新增了一些更加强大的功能,用起来比requests更爽!接下来我们来介绍一下它吧。#官网解释'''ThislibraryintendstomakeparsingHTML(e.g.scrapingtheweb)assimpleandintuitiveasposs...
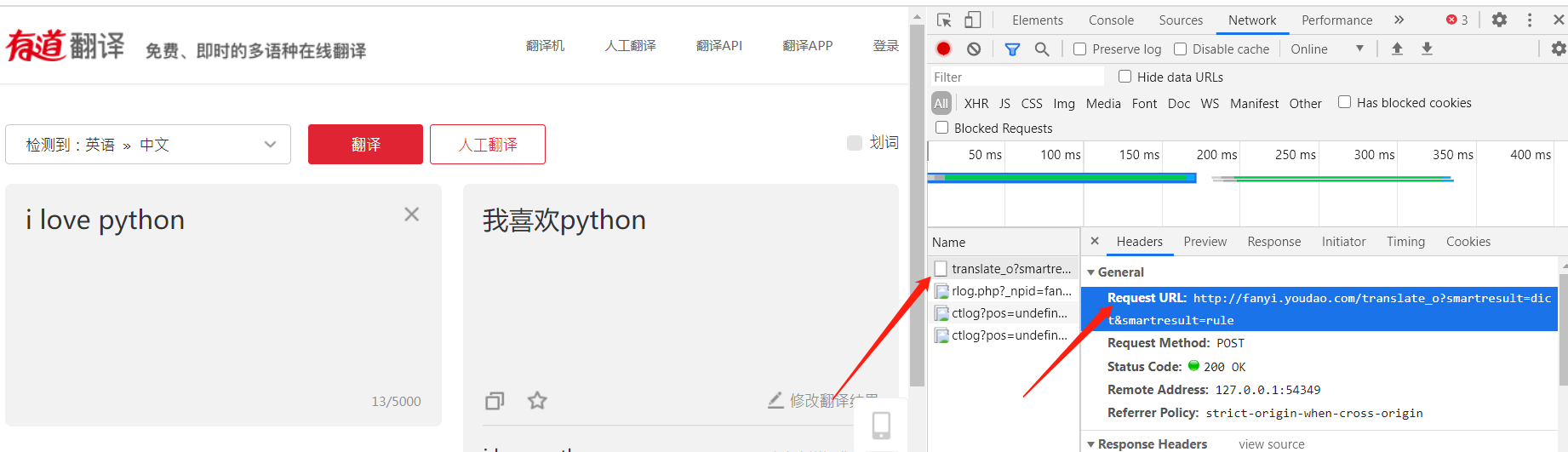 准备首先安装爬虫urllib库pipinstallurllib获取有道翻译的链接url需要发送的参数在formdata里示例importurllib.requestimporturllib.parseurl='http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'data={}data['i']='ilovepython'data['from']='AUTO'data['to']='AUTO'data['smartresult']='dict'data['client']='fanyideskweb'data['salt']='16057996372935'data['sign']='096...
准备首先安装爬虫urllib库pipinstallurllib获取有道翻译的链接url需要发送的参数在formdata里示例importurllib.requestimporturllib.parseurl='http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'data={}data['i']='ilovepython'data['from']='AUTO'data['to']='AUTO'data['smartresult']='dict'data['client']='fanyideskweb'data['salt']='16057996372935'data['sign']='096...
 生活中我们为了保障房间里物品的安全,所以给门进行上锁,在我们需要进入房间的时候又会重新打开。同样的之间我们讲过多线程中的lock,作用是为了不让多个线程运行是出错所以进行锁住的指令。但是鉴于我们实际运用中,因为线程和指令不会只有一个,如果全部都进行lock操作就会出错。所以今天小编为大家进行lock的全面讲解,同时为大家带来lock的解锁方法。由于线程之间随机调度,所以在使用共享变量时,某线程可能在执行n条后,CPU...
生活中我们为了保障房间里物品的安全,所以给门进行上锁,在我们需要进入房间的时候又会重新打开。同样的之间我们讲过多线程中的lock,作用是为了不让多个线程运行是出错所以进行锁住的指令。但是鉴于我们实际运用中,因为线程和指令不会只有一个,如果全部都进行lock操作就会出错。所以今天小编为大家进行lock的全面讲解,同时为大家带来lock的解锁方法。由于线程之间随机调度,所以在使用共享变量时,某线程可能在执行n条后,CPU...