
2020
10-10
10-10
python 爬取免费简历模板网站的示例
代码#免费的简历模板进行爬取本地保存#http://sc.chinaz.com/jianli/free.html#http://sc.chinaz.com/jianli/free_2.htmlimportrequestsfromlxmlimportetreeimportosdirName='./resumeLibs'ifnotos.path.exists(dirName):os.mkdir(dirName)headers={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/85.0.4183.83Safari/537.36'}url='http://sc.chi...
继续阅读 >
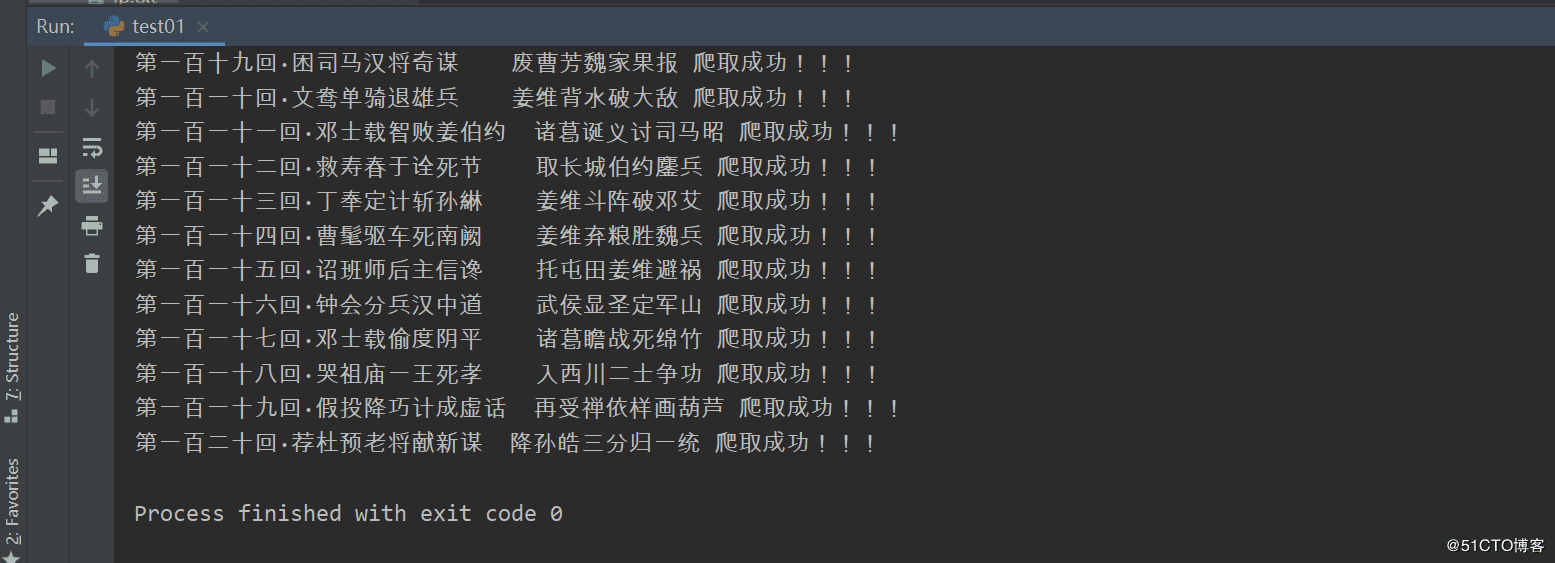 聚焦爬虫:爬取页面中指定的页面内容。编码流程:1.指定url2.发起请求3.获取响应数据4.数据解析5.持久化存储数据解析分类:1.bs42.正则3.xpath(***)数据解析原理概述:解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储1.进行指定标签的定位2.标签或者标签对应的属性中存储的数据值进行提取(解析)bs4进行数据解析数据解析的原理:1.标签定位2.提取标签、标签属性中存储的数据值bs4数据解析的原理...
聚焦爬虫:爬取页面中指定的页面内容。编码流程:1.指定url2.发起请求3.获取响应数据4.数据解析5.持久化存储数据解析分类:1.bs42.正则3.xpath(***)数据解析原理概述:解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储1.进行指定标签的定位2.标签或者标签对应的属性中存储的数据值进行提取(解析)bs4进行数据解析数据解析的原理:1.标签定位2.提取标签、标签属性中存储的数据值bs4数据解析的原理...
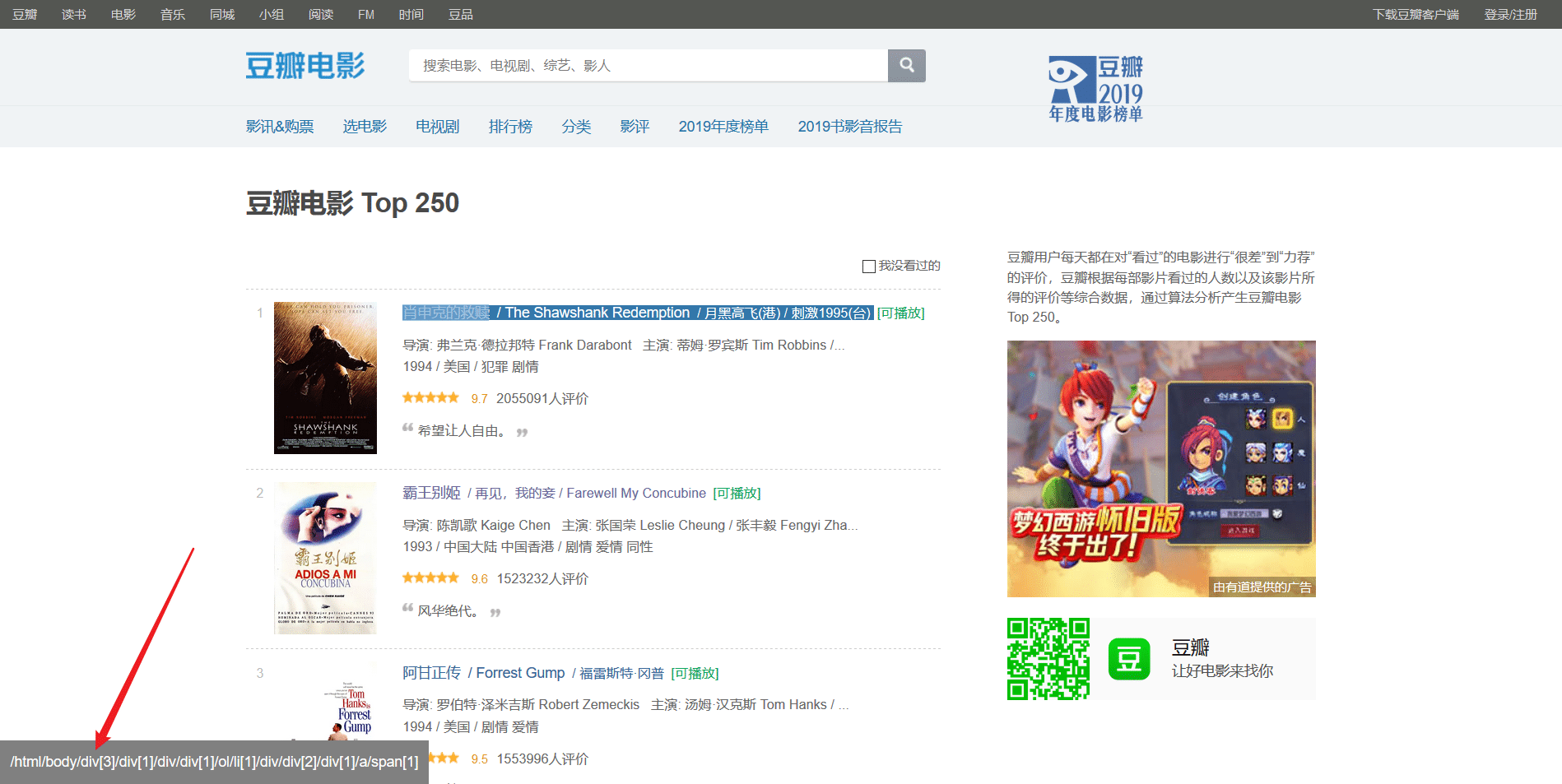 豆瓣电影排行榜前250分为10页,第一页的url为https://movie.douban.com/top250,但实际上应该是https://movie.douban.com/top250?start=0后面的参数0表示从第几个开始,如0表示从第一(肖申克的救赎)到第二十五(触不可及),https://movie.douban.com/top250?start=25表示从第二十六(蝙蝠侠:黑暗骑士)到第五十名(死亡诗社)。等等,所以可以用一个步长为25的range的for循环参数复制代码代码如下:foriinrange(0,...
豆瓣电影排行榜前250分为10页,第一页的url为https://movie.douban.com/top250,但实际上应该是https://movie.douban.com/top250?start=0后面的参数0表示从第几个开始,如0表示从第一(肖申克的救赎)到第二十五(触不可及),https://movie.douban.com/top250?start=25表示从第二十六(蝙蝠侠:黑暗骑士)到第五十名(死亡诗社)。等等,所以可以用一个步长为25的range的for循环参数复制代码代码如下:foriinrange(0,...
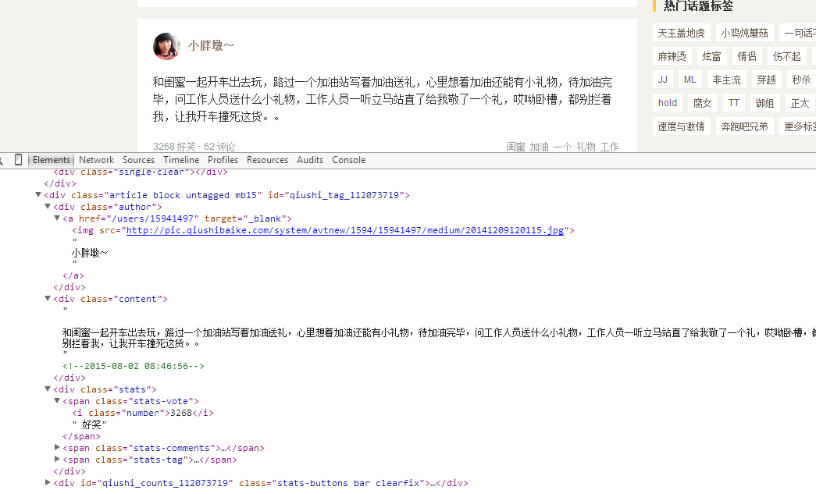 大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧。那么这次为大家带来,Python爬取糗事百科的小段子的例子。首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来。本篇目标1.抓取糗事百科热门段子;2.过滤带有图片的段子;3.实现每按一次回车显示一个段子的发布时间,发布人,段子内容,点赞数。糗事百科是不需要登录的,所以也没必要用到Cookie...
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧。那么这次为大家带来,Python爬取糗事百科的小段子的例子。首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来。本篇目标1.抓取糗事百科热门段子;2.过滤带有图片的段子;3.实现每按一次回车显示一个段子的发布时间,发布人,段子内容,点赞数。糗事百科是不需要登录的,所以也没必要用到Cookie...
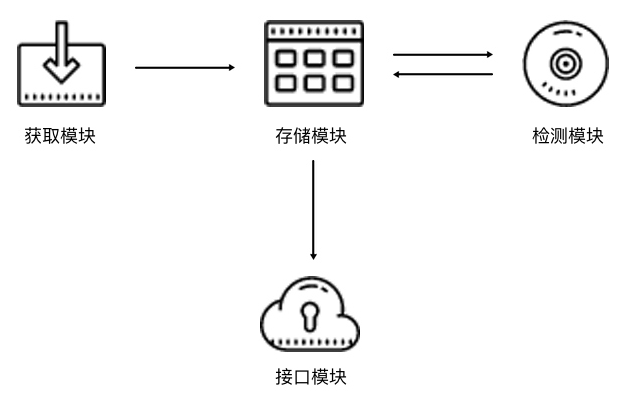 我们在上一节了解了代理的设置方法,利用代理我们可以解决目标网站封IP的问题,而在网上又有大量公开的免费代理,其中有一部分可以拿来使用,或者我们也可以购买付费的代理IP,价格也不贵。但是不论是免费的还是付费的,都不能保证它们每一个都是可用的,毕竟可能其他人也可能在用此IP爬取同样的目标站点而被封禁,或者代理服务器突然出故障或网络繁忙。一旦我们选用了一个不可用的代理,势必会影响我们爬虫的工作效率。所以...
我们在上一节了解了代理的设置方法,利用代理我们可以解决目标网站封IP的问题,而在网上又有大量公开的免费代理,其中有一部分可以拿来使用,或者我们也可以购买付费的代理IP,价格也不贵。但是不论是免费的还是付费的,都不能保证它们每一个都是可用的,毕竟可能其他人也可能在用此IP爬取同样的目标站点而被封禁,或者代理服务器突然出故障或网络繁忙。一旦我们选用了一个不可用的代理,势必会影响我们爬虫的工作效率。所以...