
2020
10-08
10-08
Python3爬虫里关于代理的设置总结
在前面我们介绍了多种请求库,如Requests、Urllib、Selenium等。我们接下来首先贴近实战,了解一下代理怎么使用,为后面了解代理池、ADSL拨号代理的使用打下基础。下面我们来梳理一下这些库的代理的设置方法。1.获取代理在做测试之前,我们需要先获取一个可用代理,搜索引擎搜索“代理”关键字,就可以看到有许多代理服务网站,在网站上会有很多免费代理,比如西刺:http://www.xicidaili.com/,这里列出了很多免费代理,但是...
继续阅读 >
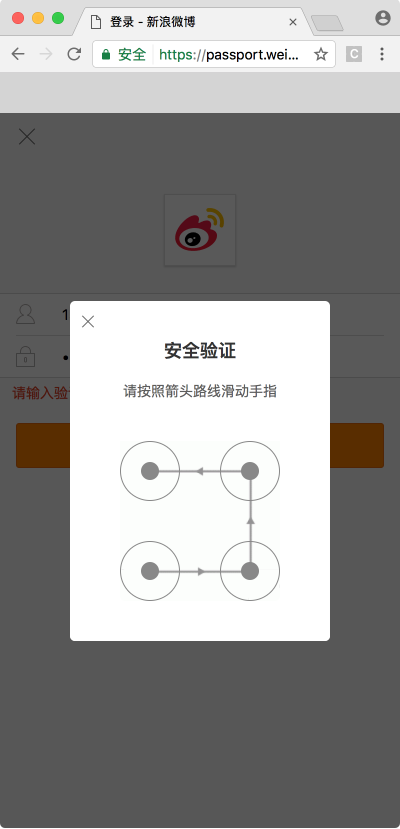 本节我们来介绍一下新浪微博宫格验证码的识别,此验证码是一种新型交互式验证码,每个宫格之间会有一条指示连线,指示了我们应该的滑动轨迹,我们需要按照滑动轨迹依次从起始宫格一直滑动到终止宫格才可以完成验证,如图所示:鼠标滑动后的轨迹会以黄色的连线来标识,如图所示:我们可以访问新浪微博移动版登录页面就可以看到如上验证码,链接为:https://passport.weibo.cn/signin/login,当然也不是每次都会出现验证码,一般当频...
本节我们来介绍一下新浪微博宫格验证码的识别,此验证码是一种新型交互式验证码,每个宫格之间会有一条指示连线,指示了我们应该的滑动轨迹,我们需要按照滑动轨迹依次从起始宫格一直滑动到终止宫格才可以完成验证,如图所示:鼠标滑动后的轨迹会以黄色的连线来标识,如图所示:我们可以访问新浪微博移动版登录页面就可以看到如上验证码,链接为:https://passport.weibo.cn/signin/login,当然也不是每次都会出现验证码,一般当频...
 上一节我们实现了极验验证码的识别,但是除了极验其实还有另一种常见的且应用广泛的验证码,比较有代表性的就是点触验证码。可能你对这个名字比较陌生,但是肯定见过类似的验证码,比如12306,这就是一种典型的点触验证码,如图所示:我们需要直接点击图中符合要求的图,如果所有答案均正确才会验证成功,如果有一个答案错误,验证就会失败,这种验证码就可以称之为点触验证码。另外还有一个专门提供点触验证码服务的站点,叫做T...
上一节我们实现了极验验证码的识别,但是除了极验其实还有另一种常见的且应用广泛的验证码,比较有代表性的就是点触验证码。可能你对这个名字比较陌生,但是肯定见过类似的验证码,比如12306,这就是一种典型的点触验证码,如图所示:我们需要直接点击图中符合要求的图,如果所有答案均正确才会验证成功,如果有一个答案错误,验证就会失败,这种验证码就可以称之为点触验证码。另外还有一个专门提供点触验证码服务的站点,叫做T...
 本节我们首先来尝试识别最简单的一种验证码,图形验证码,这种验证码出现的最早,现在也很常见,一般是四位字母或者数字组成的,例如中国知网的注册页面就有类似的验证码,链接为:http://my.cnki.net/elibregister/commonRegister.aspx,页面:表单的最后一项就是图形验证码,我们必须完全输入正确图中的字符才可以完成注册。1.本节目标本节我们就以知网的验证码为例,讲解一下利用OCR技术识别此种图形验证码的方法。2.准备工...
本节我们首先来尝试识别最简单的一种验证码,图形验证码,这种验证码出现的最早,现在也很常见,一般是四位字母或者数字组成的,例如中国知网的注册页面就有类似的验证码,链接为:http://my.cnki.net/elibregister/commonRegister.aspx,页面:表单的最后一项就是图形验证码,我们必须完全输入正确图中的字符才可以完成注册。1.本节目标本节我们就以知网的验证码为例,讲解一下利用OCR技术识别此种图形验证码的方法。2.准备工...
 使用urllib的request模块,我们可以方便地实现请求的发送并得到响应,本节就来看下它的具体用法。1.urlopen()urllib.request模块提供了最基本的构造HTTP请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理授权验证(authenticaton)、重定向(redirection)、浏览器Cookies以及其他内容。下面我们来看一下它的强大之处。这里以Python官网为例,我们来把这个网页抓下来:import urllib.requestresponse&nb...
使用urllib的request模块,我们可以方便地实现请求的发送并得到响应,本节就来看下它的具体用法。1.urlopen()urllib.request模块提供了最基本的构造HTTP请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理授权验证(authenticaton)、重定向(redirection)、浏览器Cookies以及其他内容。下面我们来看一下它的强大之处。这里以Python官网为例,我们来把这个网页抓下来:import urllib.requestresponse&nb...
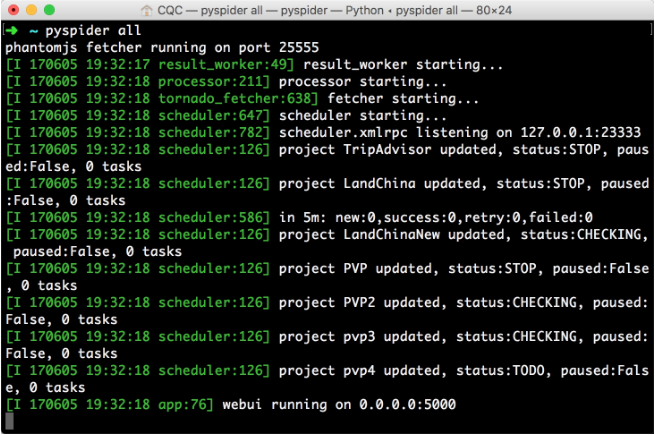 pyspider是国人binux编写的强大的网络爬虫框架,它带有强大的WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,同时支持多种数据库后端、多种消息队列,另外还支持JavaScript渲染页面的爬取,使用起来非常方便,本节介绍一下它的安装过程。1.相关链接官方文档:http://docs.pyspider.org/PyPI:https://pypi.python.org/pypi/pyspiderGitHub:https://github.com/binux/pyspider官方教程:http://docs.pyspider.org/en/...
pyspider是国人binux编写的强大的网络爬虫框架,它带有强大的WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,同时支持多种数据库后端、多种消息队列,另外还支持JavaScript渲染页面的爬取,使用起来非常方便,本节介绍一下它的安装过程。1.相关链接官方文档:http://docs.pyspider.org/PyPI:https://pypi.python.org/pypi/pyspiderGitHub:https://github.com/binux/pyspider官方教程:http://docs.pyspider.org/en/...
 Appium是移动端的自动化测试工具,类似于前面所说的Selenium,利用它可以驱动Android、iOS等设备完成自动化测试,比如模拟点击、滑动、输入等操作,其官方网站为:http://appium.io/。本节中,我们就来了解一下Appium的安装方式。1.相关链接GitHub:https://github.com/appium/appium官方网站:http://appium.io官方文档:http://appium.io/introduction.html下载链接:https://github.com/appium/appium-desktop/releasesPython...
Appium是移动端的自动化测试工具,类似于前面所说的Selenium,利用它可以驱动Android、iOS等设备完成自动化测试,比如模拟点击、滑动、输入等操作,其官方网站为:http://appium.io/。本节中,我们就来了解一下Appium的安装方式。1.相关链接GitHub:https://github.com/appium/appium官方网站:http://appium.io官方文档:http://appium.io/introduction.html下载链接:https://github.com/appium/appium-desktop/releasesPython...
 mitmproxy是一个支持HTTP和HTTPS的抓包程序,类似Fiddler、Charles的功能,只不过它通过控制台的形式操作。此外,mitmproxy还有两个关联组件,一个是mitmdump,它是mitmproxy的命令行接口,利用它可以对接Python脚本,实现监听后的处理;另一个是mitmweb,它是一个Web程序,通过它以清楚地观察到mitmproxy捕获的请求。本节中,我们就来了解一下mitmproxy、mitmdump和mitmweb的安装方式。1.相关链接GitHub:https://github.com/mit...
mitmproxy是一个支持HTTP和HTTPS的抓包程序,类似Fiddler、Charles的功能,只不过它通过控制台的形式操作。此外,mitmproxy还有两个关联组件,一个是mitmdump,它是mitmproxy的命令行接口,利用它可以对接Python脚本,实现监听后的处理;另一个是mitmweb,它是一个Web程序,通过它以清楚地观察到mitmproxy捕获的请求。本节中,我们就来了解一下mitmproxy、mitmdump和mitmweb的安装方式。1.相关链接GitHub:https://github.com/mit...
 本篇目标抓取淘宝MM的姓名,头像,年龄抓取每一个MM的资料简介以及写真图片把每一个MM的写真图片按照文件夹保存到本地熟悉文件保存的过程 1.URL的格式在这里我们用到的URL是http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址。点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面。我们需要抓取本页面的头像地址,MM...
本篇目标抓取淘宝MM的姓名,头像,年龄抓取每一个MM的资料简介以及写真图片把每一个MM的写真图片按照文件夹保存到本地熟悉文件保存的过程 1.URL的格式在这里我们用到的URL是http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址。点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面。我们需要抓取本页面的头像地址,MM...
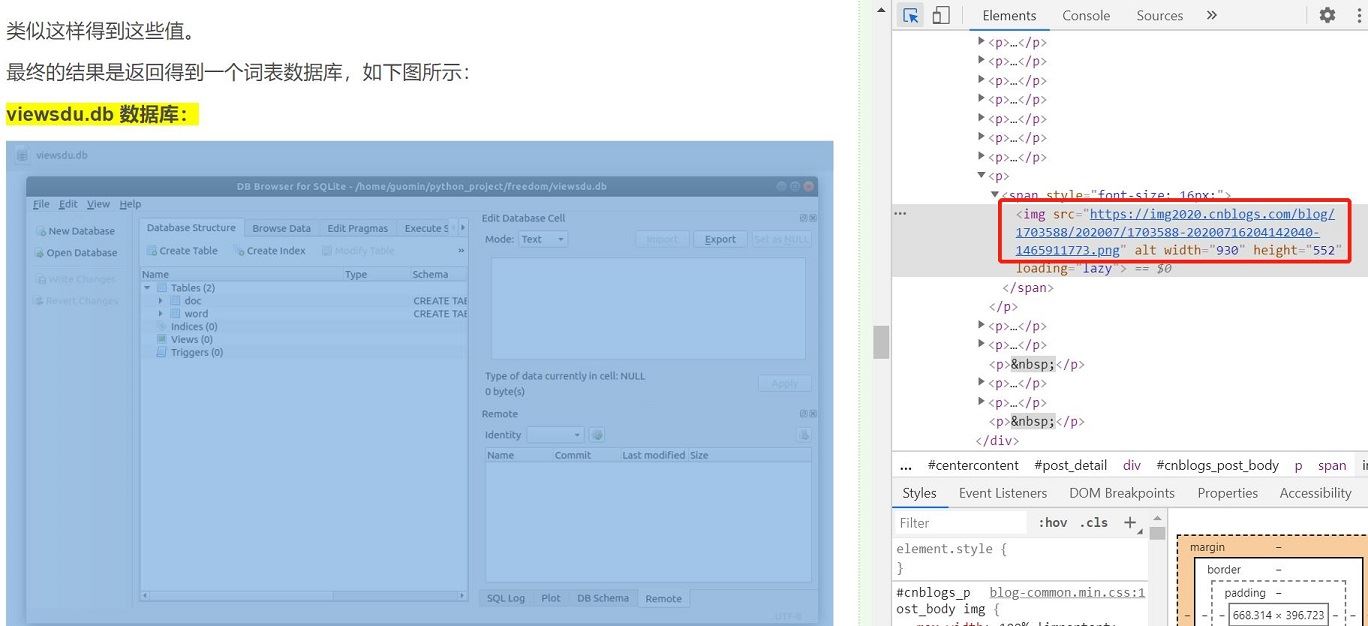 想要爬取指定网页中的图片主要需要以下三个步骤:(1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键->Inspect->Elements中的html内容)(2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容(3)设置循环列表,重复抓取和保存内容以下介绍了两种方法实现抓取指定网页中图片(1)方法一:使用正则表达式过滤抓到的html内容字符串#第一个简单的爬取图片的程序importurllib.request#pyt...
想要爬取指定网页中的图片主要需要以下三个步骤:(1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键->Inspect->Elements中的html内容)(2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容(3)设置循环列表,重复抓取和保存内容以下介绍了两种方法实现抓取指定网页中图片(1)方法一:使用正则表达式过滤抓到的html内容字符串#第一个简单的爬取图片的程序importurllib.request#pyt...