
2020
10-08
10-08
Python爬虫实例——爬取美团美食数据
1.分析美团美食网页的url参数构成1)搜索要点美团美食,地址:北京,搜索关键词:火锅2)爬取的urlhttps://bj.meituan.com/s/%E7%81%AB%E9%94%85/3)说明url会有自动编码中文功能。所以火锅二字指的就是这一串我们不认识的代码%E7%81%AB%E9%94%85。通过关键词城市的url构造,解析当前url中的bj=北京,/s/后面跟搜索关键词。这样我们就可以了解到当前url的构造。2.分析页面数据来源(F12开发者工具)开启F12开发者工具,并且刷新当前...
继续阅读 >
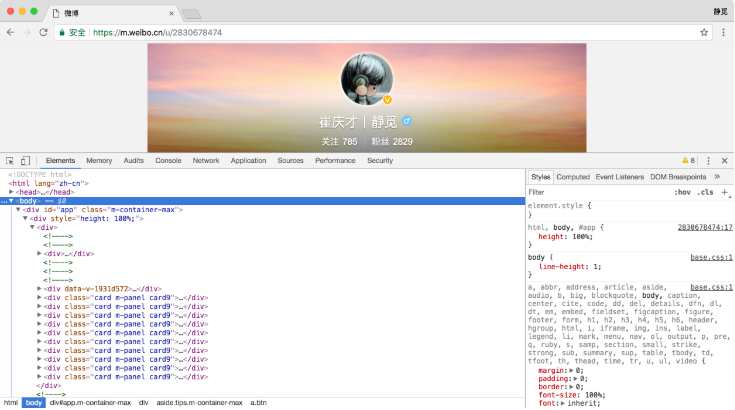 这里还以前面的微博为例,我们知道拖动刷新的内容由Ajax加载,而且页面的URL没有变化,那么应该到哪里去查看这些Ajax请求呢?1.查看请求这里还需要借助浏览器的开发者工具,下面以Chrome浏览器为例来介绍。首先,用Chrome浏览器打开微博的链接https://m.weibo.cn/u/2830678474,随后在页面中点击鼠标右键,从弹出的快捷菜单中选择“检查”选项,此时便会弹出开发者工具,如图6-2所示:此时在Elements选项卡中便会观察到网页的源代...
这里还以前面的微博为例,我们知道拖动刷新的内容由Ajax加载,而且页面的URL没有变化,那么应该到哪里去查看这些Ajax请求呢?1.查看请求这里还需要借助浏览器的开发者工具,下面以Chrome浏览器为例来介绍。首先,用Chrome浏览器打开微博的链接https://m.weibo.cn/u/2830678474,随后在页面中点击鼠标右键,从弹出的快捷菜单中选择“检查”选项,此时便会弹出开发者工具,如图6-2所示:此时在Elements选项卡中便会观察到网页的源代...
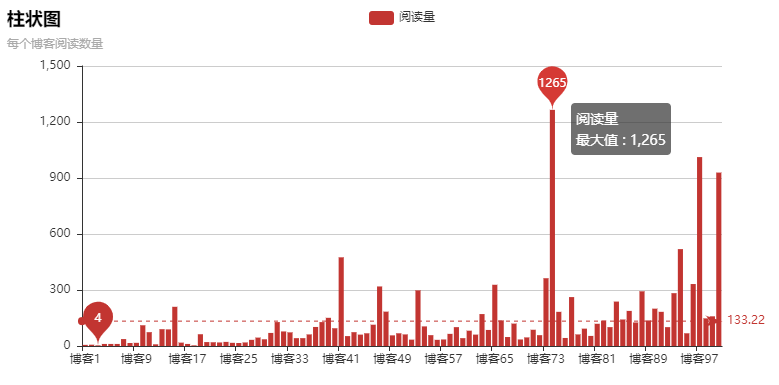 源码:frompyechartsimportBarimportreimportrequestsnum=0b=[]foriinrange(1,11):link='https://www.cnblogs.com/echoDetected/default.html?page='+str(i)headers={'user-agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/72.0.3626.109Safari/537.36'}r=requests.get(link,headers=headers)html=r.textpost=re.findall('<spanclass="post-view-count...
源码:frompyechartsimportBarimportreimportrequestsnum=0b=[]foriinrange(1,11):link='https://www.cnblogs.com/echoDetected/default.html?page='+str(i)headers={'user-agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/72.0.3626.109Safari/537.36'}r=requests.get(link,headers=headers)html=r.textpost=re.findall('<spanclass="post-view-count...
 做电商时,消费者对商品的评论是很重要的,但是不会写代码怎么办?这里有个Chrome插件可以做到简单的数据爬取,一句代码都不用写。下面给大家展示部分抓取后的数据:可以看到,抓取的地址,评论人,评论内容,时间,产品颜色都已经抓取下来了。那么,爬取这些数据需要哪些工具呢?就两个:1.Chrome浏览器;2.插件:WebScraper插件下载地址:https://chromecj.com/productivity/2018-05/942.html最后,如果你想自己动手抓取一下...
做电商时,消费者对商品的评论是很重要的,但是不会写代码怎么办?这里有个Chrome插件可以做到简单的数据爬取,一句代码都不用写。下面给大家展示部分抓取后的数据:可以看到,抓取的地址,评论人,评论内容,时间,产品颜色都已经抓取下来了。那么,爬取这些数据需要哪些工具呢?就两个:1.Chrome浏览器;2.插件:WebScraper插件下载地址:https://chromecj.com/productivity/2018-05/942.html最后,如果你想自己动手抓取一下...
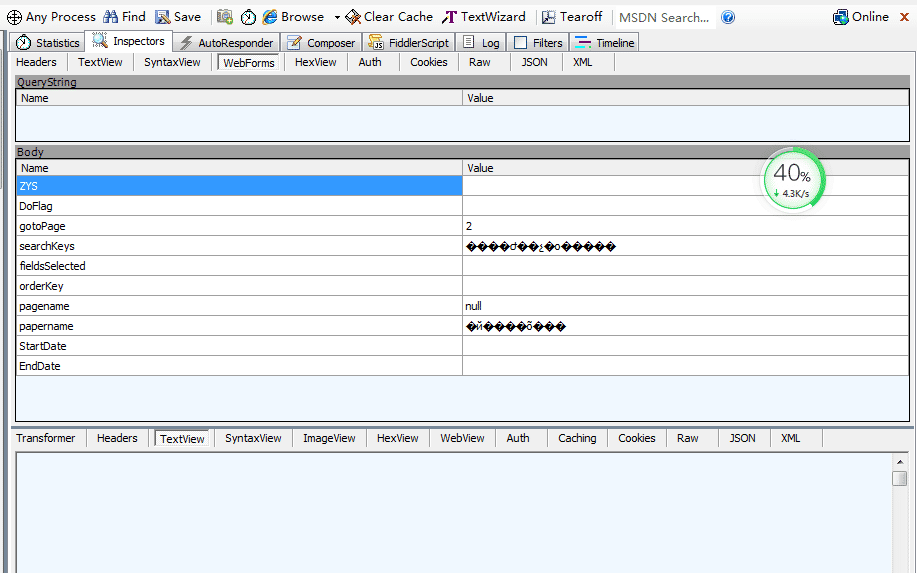 1.问题抓取某个网站,发现请求参数是乱码格式,这是点击TextView,发现请求参数如下图所示3.那么=%B9%FA%CE%F1%D4%BA%B7%A2%D5%B9%D1%D0%BE%BF%D6%D0%D0%C4是什么东西啊解码后是=国务院发展研究中心代码实现:content="我爱中国"importurllibres=urllib.quote(content.encode('gb2312'))printresprint"11111111",type(res)以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。...
1.问题抓取某个网站,发现请求参数是乱码格式,这是点击TextView,发现请求参数如下图所示3.那么=%B9%FA%CE%F1%D4%BA%B7%A2%D5%B9%D1%D0%BE%BF%D6%D0%D0%C4是什么东西啊解码后是=国务院发展研究中心代码实现:content="我爱中国"importurllibres=urllib.quote(content.encode('gb2312'))printresprint"11111111",type(res)以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。...
 相信小伙伴们都知道今冬以来范围最广、持续时间最长、影响最重的一场低温雨雪冰冻天气过程正在进行中。预计,今天安徽、江苏、浙江、湖北、湖南等地有暴雪,局地大暴雪,新增积雪深度4~8厘米,局地可达10~20厘米。此外,贵州中东部、湖南中北部、湖北东南部、江西西北部有冻雨。言归正传,天气无时无刻都在陪伴着我们,今天小编带大家利用Python网络爬虫来实现天气情况的实时采集。此次的目标网站是绿色呼吸网。绿色呼吸网站免费...
相信小伙伴们都知道今冬以来范围最广、持续时间最长、影响最重的一场低温雨雪冰冻天气过程正在进行中。预计,今天安徽、江苏、浙江、湖北、湖南等地有暴雪,局地大暴雪,新增积雪深度4~8厘米,局地可达10~20厘米。此外,贵州中东部、湖南中北部、湖北东南部、江西西北部有冻雨。言归正传,天气无时无刻都在陪伴着我们,今天小编带大家利用Python网络爬虫来实现天气情况的实时采集。此次的目标网站是绿色呼吸网。绿色呼吸网站免费...
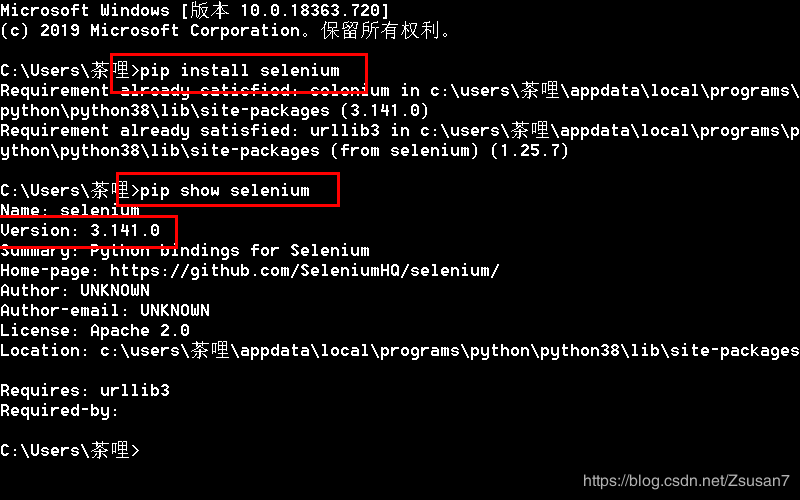 下载好所需程序1.Selenium简介Selenium是一个用于Web应用程序测试的工具,直接运行在浏览器中,就像真正的用户在操作一样。2.Selenium安装方法一:在Windows命令行(cmd)输入pipinstallselenium即可自动安装,安装完成后,输入pipshowselenium可查看当前的版本方法二:直接下载selenium包:selenium下载网址Pychome安装selenium如果出现无法安装,参考以下博客解决Pycharm无法使用已经安装Selenium的问题3.禁止谷歌浏览器自动...
下载好所需程序1.Selenium简介Selenium是一个用于Web应用程序测试的工具,直接运行在浏览器中,就像真正的用户在操作一样。2.Selenium安装方法一:在Windows命令行(cmd)输入pipinstallselenium即可自动安装,安装完成后,输入pipshowselenium可查看当前的版本方法二:直接下载selenium包:selenium下载网址Pychome安装selenium如果出现无法安装,参考以下博客解决Pycharm无法使用已经安装Selenium的问题3.禁止谷歌浏览器自动...