
2020
09-27
09-27
python爬虫学习笔记之Beautifulsoup模块用法详解
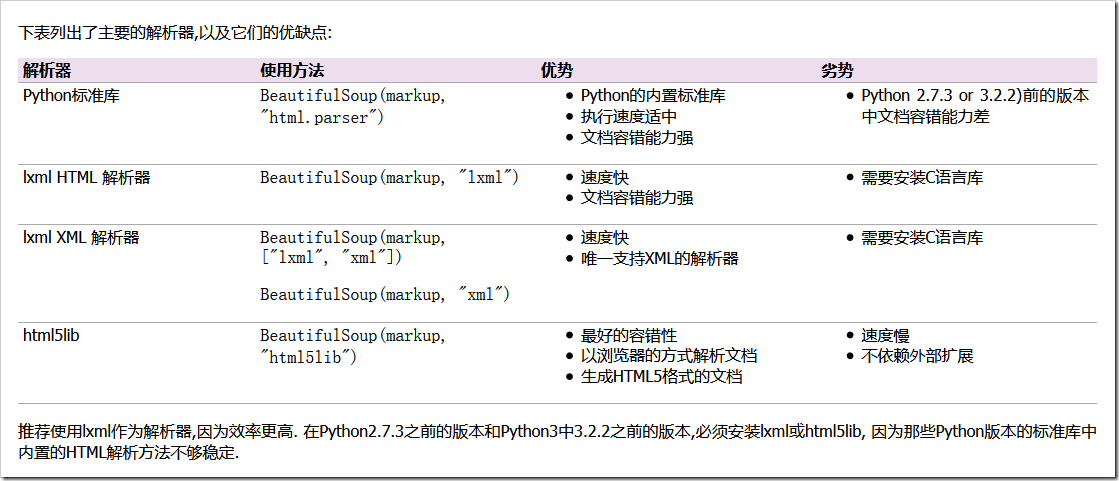 本文实例讲述了python爬虫学习笔记之Beautifulsoup模块用法。分享给大家供大家参考,具体如下:相关内容:什么是beautifulsoupbs4的使用导入模块选择使用解析器使用标签名查找使用find\find_all查找使用select查找首发时间:2018-03-0200:10什么是beautifulsoup:是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(官方)beaut...
继续阅读 >
本文实例讲述了python爬虫学习笔记之Beautifulsoup模块用法。分享给大家供大家参考,具体如下:相关内容:什么是beautifulsoupbs4的使用导入模块选择使用解析器使用标签名查找使用find\find_all查找使用select查找首发时间:2018-03-0200:10什么是beautifulsoup:是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(官方)beaut...
继续阅读 >
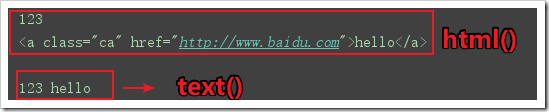 本文实例讲述了python爬虫学习笔记之pyquery模块基本用法。分享给大家供大家参考,具体如下:相关内容:pyquery的介绍pyquery的使用安装模块导入模块解析对象初始化css选择器在选定元素之后的元素再选取元素的文本、属性等内容的获取pyquery执行DOM操作、css操作Dom操作CSS操作一个利用pyquery爬取豆瓣新书的例子首发时间:2018-03-0921:26pyquery的介绍pyquery允许对xml...
本文实例讲述了python爬虫学习笔记之pyquery模块基本用法。分享给大家供大家参考,具体如下:相关内容:pyquery的介绍pyquery的使用安装模块导入模块解析对象初始化css选择器在选定元素之后的元素再选取元素的文本、属性等内容的获取pyquery执行DOM操作、css操作Dom操作CSS操作一个利用pyquery爬取豆瓣新书的例子首发时间:2018-03-0921:26pyquery的介绍pyquery允许对xml...
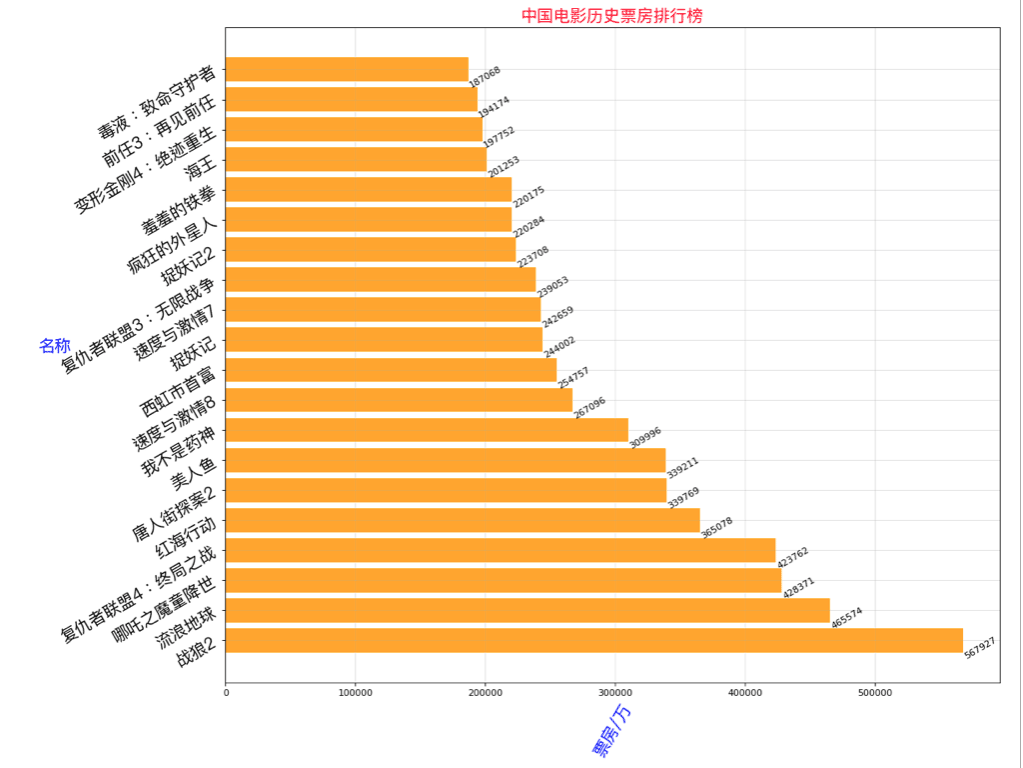 本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:爬虫电影历史票房排行榜http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0Python爬取历史电影票房纪录解析Json数据横向条形图展示面向对象思想导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportjson类代码部分classDYOrder(object):#初始化def...
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:爬虫电影历史票房排行榜http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0Python爬取历史电影票房纪录解析Json数据横向条形图展示面向对象思想导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportjson类代码部分classDYOrder(object):#初始化def...
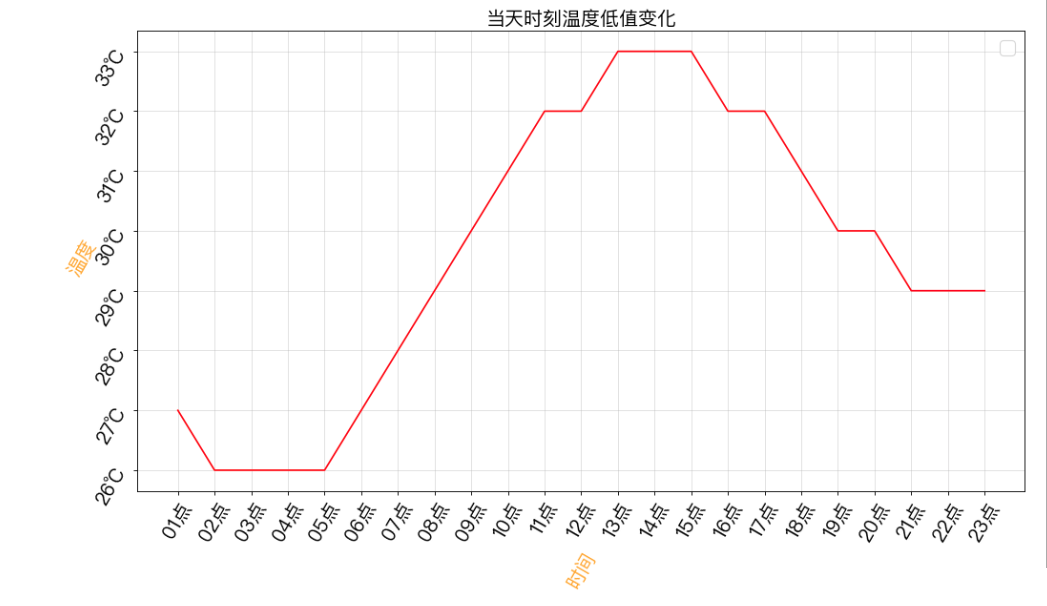 本文实例讲述了Python爬虫爬取杭州24时温度并展示操作。分享给大家供大家参考,具体如下:散点图爬虫杭州今日24时温度https://www.baidutianqi.com/today/58457.htm利用正则表达式爬取杭州温度面向对象编程图表展示(散点图/折线图)导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportmatplotlib类代码部分classWeather(object):def__init__(self):...
本文实例讲述了Python爬虫爬取杭州24时温度并展示操作。分享给大家供大家参考,具体如下:散点图爬虫杭州今日24时温度https://www.baidutianqi.com/today/58457.htm利用正则表达式爬取杭州温度面向对象编程图表展示(散点图/折线图)导入相关库importrequestsimportrefrommatplotlibimportpyplotaspltfrommatplotlibimportfont_managerimportmatplotlib类代码部分classWeather(object):def__init__(self):...
 1前言Python开发网络爬虫获取网页数据的基本流程为:发起请求通过URL向服务器发起request请求,请求可以包含额外的header信息。获取响应内容服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。解析内容如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理。...
1前言Python开发网络爬虫获取网页数据的基本流程为:发起请求通过URL向服务器发起request请求,请求可以包含额外的header信息。获取响应内容服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。解析内容如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理。...
 0x01常见的反爬虫这几天在爬一个网站,网站做了很多反爬虫工作,爬起来有些艰难,花了一些时间才绕过反爬虫。在这里把我写爬虫以来遇到的各种反爬虫策略和应对的方法总结一下。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。这里我们只讨论数据采集部分。一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第...
0x01常见的反爬虫这几天在爬一个网站,网站做了很多反爬虫工作,爬起来有些艰难,花了一些时间才绕过反爬虫。在这里把我写爬虫以来遇到的各种反爬虫策略和应对的方法总结一下。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。这里我们只讨论数据采集部分。一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第...