
2021
03-11
03-11
python实现selenium网络爬虫的方法小结
 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器,这里只用到谷歌浏览器。1.selenium初始化方法一:会打开网页#该方法会打开goole网页fromseleniumimportwebdriverurl='网址'driver=webdriver.Chrome()driver.get(url)driver....
继续阅读 >
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器,这里只用到谷歌浏览器。1.selenium初始化方法一:会打开网页#该方法会打开goole网页fromseleniumimportwebdriverurl='网址'driver=webdriver.Chrome()driver.get(url)driver....
继续阅读 >
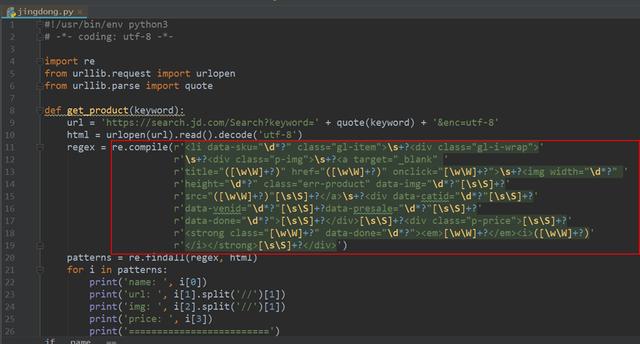 前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东网的商品信息。今天小编来给大家总结一下这四个选择器,让大家更加深刻的理解和熟悉Python选择器。一、正则表达式正则表达式为我们提供了抓取数据的快捷方式。虽然该正则表达式更容易适应未来变化,但又存在难以构造、可读性差的问题。当在爬京东网的时候,正则表达式如下图所示:利用正则表达式实现对目标信息的精...
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东网的商品信息。今天小编来给大家总结一下这四个选择器,让大家更加深刻的理解和熟悉Python选择器。一、正则表达式正则表达式为我们提供了抓取数据的快捷方式。虽然该正则表达式更容易适应未来变化,但又存在难以构造、可读性差的问题。当在爬京东网的时候,正则表达式如下图所示:利用正则表达式实现对目标信息的精...
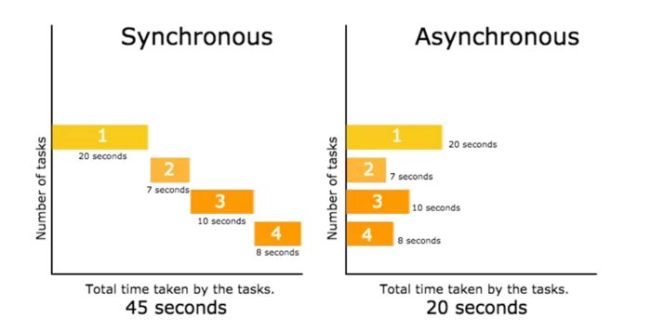 一、同步与异步#同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> &n...
一、同步与异步#同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> &n...
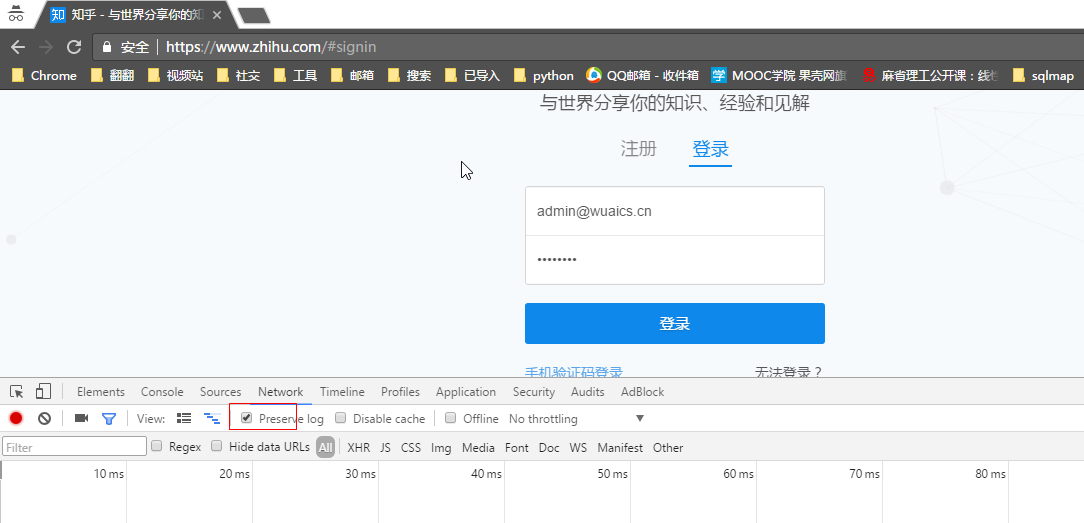 本次我们实现如何模拟登陆知乎。1.抓包首先打开知乎登录页知乎-与世界分享你的知识、经验和见解注意打开开发者工具后点击“preservelog”,密码记得故意输入错误,然后点击登录我们很简单的就找到了我们需要的请求_xsrf:81aa4a69cd410c3454ce515187f2d4c9password:***email:admin@wuaics.cn可以看到请求一共有三个参数email和password就是我们需要登录的账号及密码那么_xsrf...
本次我们实现如何模拟登陆知乎。1.抓包首先打开知乎登录页知乎-与世界分享你的知识、经验和见解注意打开开发者工具后点击“preservelog”,密码记得故意输入错误,然后点击登录我们很简单的就找到了我们需要的请求_xsrf:81aa4a69cd410c3454ce515187f2d4c9password:***email:admin@wuaics.cn可以看到请求一共有三个参数email和password就是我们需要登录的账号及密码那么_xsrf...
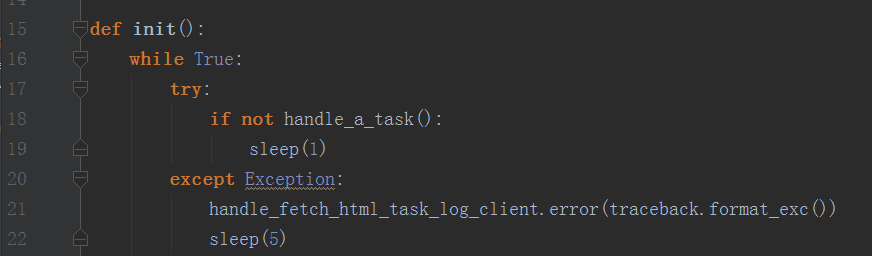 爬虫,几家欢喜几人愁。爬者,拿到有利数据,分析行为,产生价值。被爬者,一是损失数据,二是遇到不怀好意的爬虫往往被全站复制或服务器受冲击而无法服务。今天说的是一只友好的爬虫是如何构建出来的,请勿用它伤害他人。爬虫一生所遇俗话说,如果我比别人看得远些,那是因为我站在巨人们的肩上。前人之鉴,后人之师。小爬虫在胎教的时候就该传授它的前辈参悟的人生经验,了解网络的可怕之处。看看我提供的胎教课程:...
爬虫,几家欢喜几人愁。爬者,拿到有利数据,分析行为,产生价值。被爬者,一是损失数据,二是遇到不怀好意的爬虫往往被全站复制或服务器受冲击而无法服务。今天说的是一只友好的爬虫是如何构建出来的,请勿用它伤害他人。爬虫一生所遇俗话说,如果我比别人看得远些,那是因为我站在巨人们的肩上。前人之鉴,后人之师。小爬虫在胎教的时候就该传授它的前辈参悟的人生经验,了解网络的可怕之处。看看我提供的胎教课程:...