
2020
11-01
11-01
详解tensorflow之过拟合问题实战
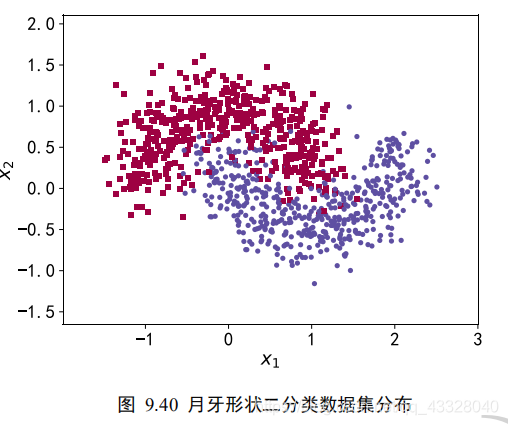 过拟合问题实战1.构建数据集我们使用的数据集样本特性向量长度为2,标签为0或1,分别代表了2种类别。借助于scikit-learn库中提供的make_moons工具我们可以生成任意多数据的训练集。importmatplotlib.pyplotasplt#导入数据集生成工具importnumpyasnpimportseabornassnsfromsklearn.datasetsimportmake_moonsfromsklearn.model_selectionimporttrain_test_splitfromtensorflow.kerasimportlayers,Seq...
继续阅读 >
过拟合问题实战1.构建数据集我们使用的数据集样本特性向量长度为2,标签为0或1,分别代表了2种类别。借助于scikit-learn库中提供的make_moons工具我们可以生成任意多数据的训练集。importmatplotlib.pyplotasplt#导入数据集生成工具importnumpyasnpimportseabornassnsfromsklearn.datasetsimportmake_moonsfromsklearn.model_selectionimporttrain_test_splitfromtensorflow.kerasimportlayers,Seq...
继续阅读 >
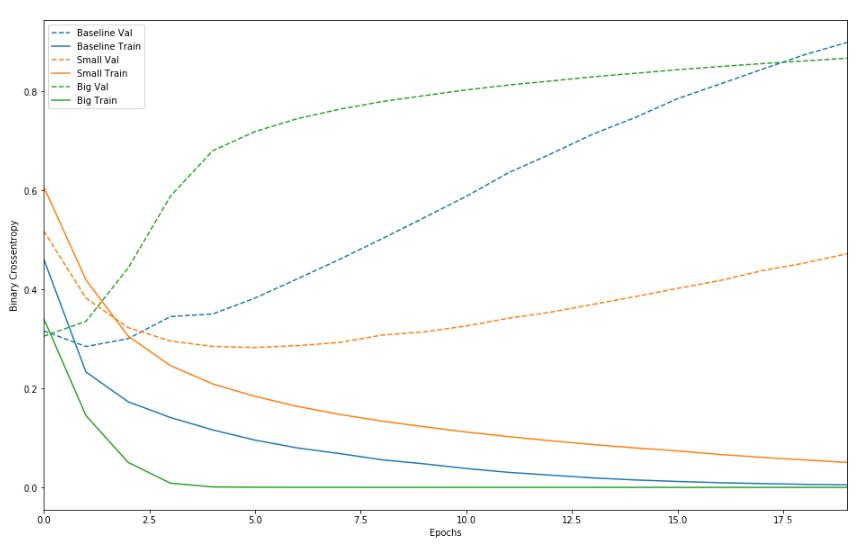 baselineimporttensorflow.keras.layersaslayersbaseline_model=keras.Sequential([layers.Dense(16,activation='relu',input_shape=(NUM_WORDS,)),layers.Dense(16,activation='relu'),layers.Dense(1,activation='sigmoid')])baseline_model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy','binary_crossentropy'])baseline_model.summary()baseline_history=baseline_mo...
baselineimporttensorflow.keras.layersaslayersbaseline_model=keras.Sequential([layers.Dense(16,activation='relu',input_shape=(NUM_WORDS,)),layers.Dense(16,activation='relu'),layers.Dense(1,activation='sigmoid')])baseline_model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy','binary_crossentropy'])baseline_model.summary()baseline_history=baseline_mo...
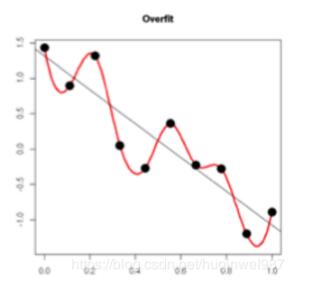 L2正则化原理:过拟合的原理:在loss下降,进行拟合的过程中(斜线),不同的batch数据样本造成红色曲线的波动大,图中低点也就是过拟合,得到的红线点低于真实的黑线,也就是泛化更差。可见,要想减小过拟合,减小这个波动,减少w的数值就能办到。L2正则化训练的原理:在Loss中加入(乘以系数λ的)参数w的平方和,这样训练过程中就会抑制w的值,w的(绝对)值小,模型复杂度低,曲线平滑,过拟合程度低(奥卡姆剃刀),参考公式...
L2正则化原理:过拟合的原理:在loss下降,进行拟合的过程中(斜线),不同的batch数据样本造成红色曲线的波动大,图中低点也就是过拟合,得到的红线点低于真实的黑线,也就是泛化更差。可见,要想减小过拟合,减小这个波动,减少w的数值就能办到。L2正则化训练的原理:在Loss中加入(乘以系数λ的)参数w的平方和,这样训练过程中就会抑制w的值,w的(绝对)值小,模型复杂度低,曲线平滑,过拟合程度低(奥卡姆剃刀),参考公式...