
2022
04-30
04-30
如何运用python读写CSV文件
目录1、使用基础Python代码来读写和处理CSV文件2、使用pandas读写和处理CSV文件3、使用内置csv读写和处理CSV文件1、使用基础Python代码来读写和处理CSV文件importsys#使用基础Python代码来读写和处理CSV文件input_file=sys.argv[1]output_file=sys.argv[2]withopen(input_file,'r',newline='')asfilereader:withopen(output_file,'w',newline='')asfilewriter:header=filereader.readline()h...
继续阅读 >
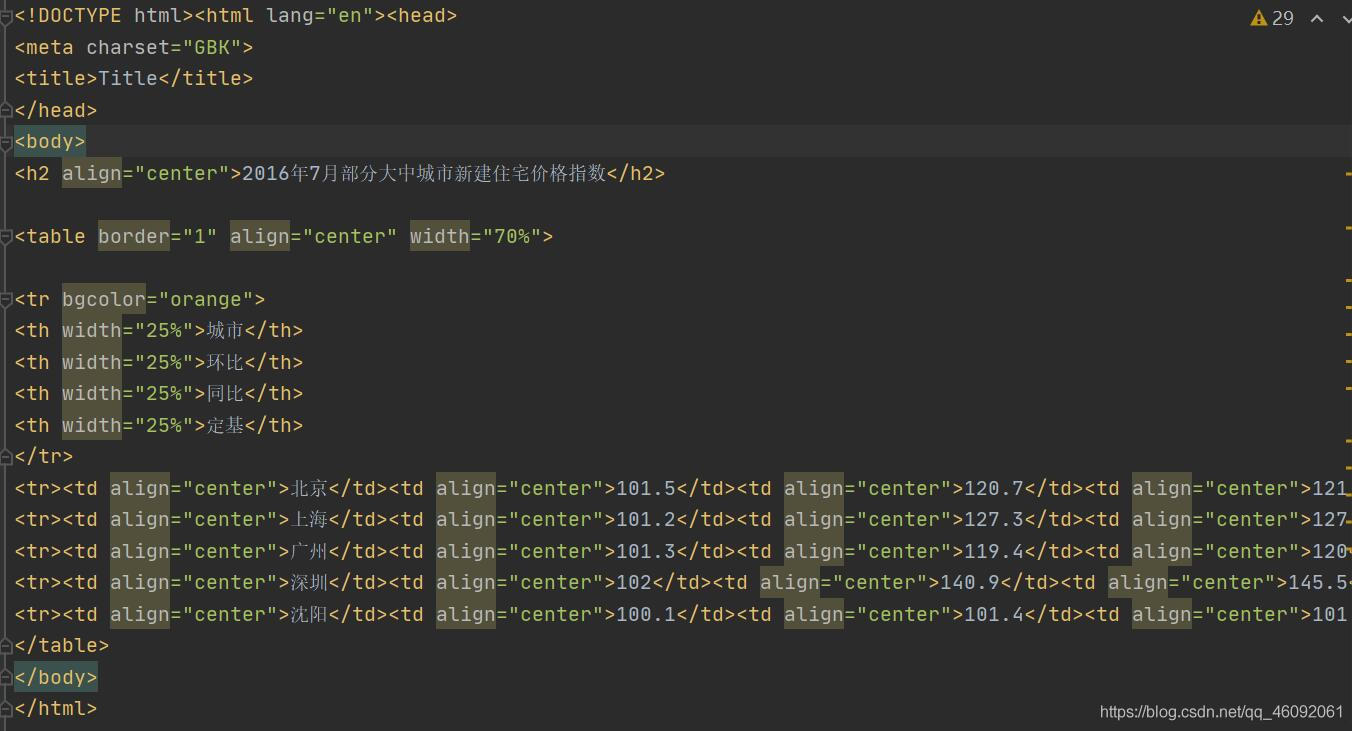 What'sCSVCSV逗号分隔值(Comma-SeparatedValues,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常...
What'sCSVCSV逗号分隔值(Comma-SeparatedValues,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常...
 pandas读取txt文件读取txt文件需要确定txt文件是否符合基本的格式,也就是是否存在\t,,,等特殊的分隔符一般txt文件长成这个样子txt文件举例下面的文件为空格间隔12019-03-2200:06:24.4463094中文测试22019-03-2200:06:32.4565680需要编辑encoding32019-03-2200:06:32.6835965ashshsh42017-03-2200:06:32.8041945eggg读取命令采用read_csv或者read_table都可以importpandasaspddf=pd.read_table("./test.txt"...
pandas读取txt文件读取txt文件需要确定txt文件是否符合基本的格式,也就是是否存在\t,,,等特殊的分隔符一般txt文件长成这个样子txt文件举例下面的文件为空格间隔12019-03-2200:06:24.4463094中文测试22019-03-2200:06:32.4565680需要编辑encoding32019-03-2200:06:32.6835965ashshsh42017-03-2200:06:32.8041945eggg读取命令采用read_csv或者read_table都可以importpandasaspddf=pd.read_table("./test.txt"...
 问题jupyternotebook读入csv数据时出现错误“SyntaxError:(unicodeerror)‘unicodeescape'codeccan'tdecodebytesinposition2-3:truncated\UX”解决方法将文件路径中'C:\Users\huangyanli\Desktop\churn.csv'的“\”改为“\\”就可以了。完美解决问题。补充:Jupyternotebook导出的csv文件是乱码的解决方案本人使用的是Jupyternotebook编辑器做数据分析的,API是pyspark,有时候需要把pysparkDataFrame转成pa...
问题jupyternotebook读入csv数据时出现错误“SyntaxError:(unicodeerror)‘unicodeescape'codeccan'tdecodebytesinposition2-3:truncated\UX”解决方法将文件路径中'C:\Users\huangyanli\Desktop\churn.csv'的“\”改为“\\”就可以了。完美解决问题。补充:Jupyternotebook导出的csv文件是乱码的解决方案本人使用的是Jupyternotebook编辑器做数据分析的,API是pyspark,有时候需要把pysparkDataFrame转成pa...
 一、我的需求对于这样的一个csv表,需要将其(1)将营业部名称和日期和股票代码进行拼接(2)对于除了买入金额不同的的数据需要将它们的买入金额相加,每个买入金额乘以买卖序号的符号表示该营业名称对应的买入金额比如:xx公司,20190731,1,股票1,4000,C20201010,xxxx我这里想要的结果是:xx公司2019713C20201010,4000二、代码(1)首先由于文件是gbk,所以读取是需要注意encoding(2)日期是int类型,所以需要转化为字符...
一、我的需求对于这样的一个csv表,需要将其(1)将营业部名称和日期和股票代码进行拼接(2)对于除了买入金额不同的的数据需要将它们的买入金额相加,每个买入金额乘以买卖序号的符号表示该营业名称对应的买入金额比如:xx公司,20190731,1,股票1,4000,C20201010,xxxx我这里想要的结果是:xx公司2019713C20201010,4000二、代码(1)首先由于文件是gbk,所以读取是需要注意encoding(2)日期是int类型,所以需要转化为字符...
 这个操作现在看来真没啥难的,但是我找相关的资料真的找了好久。多数大佬都是直接pandas官网甩我脸上,然后举一个入门级的例子。https://pandas.pydata.org/docs/reference/index.html首先导入pandas库importpandasaspd然后使用read_csv来打开指定的csv文件df=pd.read_csv('./IP2LOCATION.csv',encoding='utf-8')这个函数里面需要写入csv文件的路径,如果是把csv文件保存到了python的工程文件夹下,则只需要./文件名即可,然...
这个操作现在看来真没啥难的,但是我找相关的资料真的找了好久。多数大佬都是直接pandas官网甩我脸上,然后举一个入门级的例子。https://pandas.pydata.org/docs/reference/index.html首先导入pandas库importpandasaspd然后使用read_csv来打开指定的csv文件df=pd.read_csv('./IP2LOCATION.csv',encoding='utf-8')这个函数里面需要写入csv文件的路径,如果是把csv文件保存到了python的工程文件夹下,则只需要./文件名即可,然...
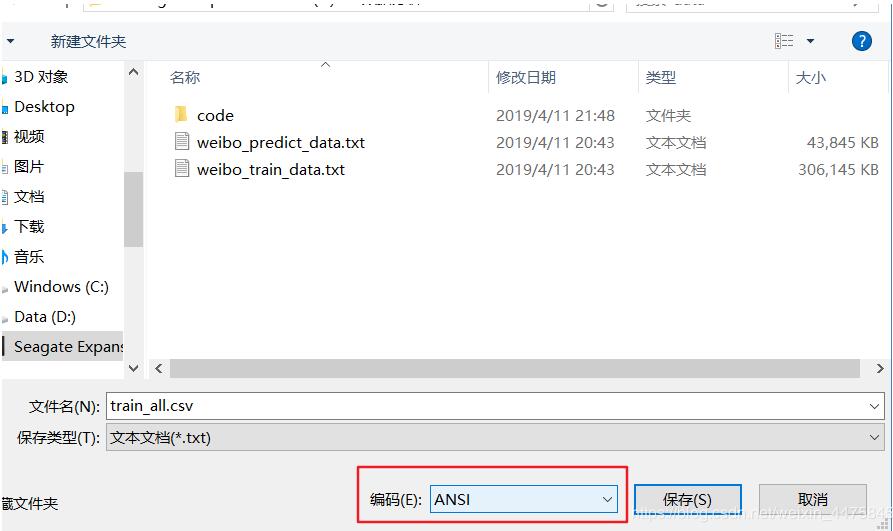 先将准备的文件上传到自己的jupyter工作空间importnumpyasnpimportpandasaspdhousing=pd.read_csv('housing.csv')补充知识:在jupyter中读取CSV文件时出现‘utf-8'codeccan'tdecodebyte0xd5inposition0:invalidcontinuationbyte解决方法导入import pandasaspd使用pd.read_csv()读csv文件时,出现如下错误:UnicodeDecodeError:‘utf-8'codeccan'tdecodebyte0xd5 inposition0:invalidcont...
先将准备的文件上传到自己的jupyter工作空间importnumpyasnpimportpandasaspdhousing=pd.read_csv('housing.csv')补充知识:在jupyter中读取CSV文件时出现‘utf-8'codeccan'tdecodebyte0xd5inposition0:invalidcontinuationbyte解决方法导入import pandasaspd使用pd.read_csv()读csv文件时,出现如下错误:UnicodeDecodeError:‘utf-8'codeccan'tdecodebyte0xd5 inposition0:invalidcont...