
2022
10-08
10-08
一文搞定Docker安装ElasticSearch的过程
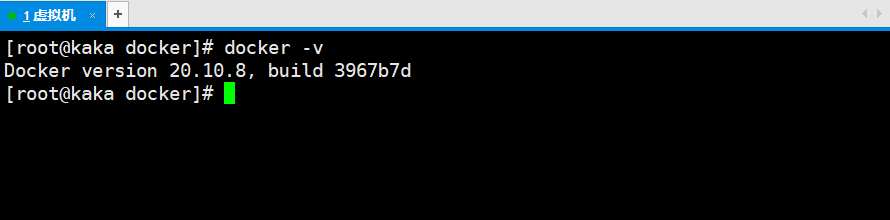 目录前言一、安装Docker二、安装ElasticSearch三、安装ElasticSearch-Head四、安装IK分词器五、总结前言项目准备上ElasticSearch,为了后期开发不卡壳只能笨鸟先飞,在整个安装过程中遇到以下三个问题。Docker安装非常慢ElasticSearch-Head连接出现跨域ElasticSearch-Head操作报出406错误码一、安装Docker目前咔咔对Docker的理解还只是个皮毛,对于不了解的东西就要多多使用,使用的多了自然而然也就会了。安装依赖包...
继续阅读 >
目录前言一、安装Docker二、安装ElasticSearch三、安装ElasticSearch-Head四、安装IK分词器五、总结前言项目准备上ElasticSearch,为了后期开发不卡壳只能笨鸟先飞,在整个安装过程中遇到以下三个问题。Docker安装非常慢ElasticSearch-Head连接出现跨域ElasticSearch-Head操作报出406错误码一、安装Docker目前咔咔对Docker的理解还只是个皮毛,对于不了解的东西就要多多使用,使用的多了自然而然也就会了。安装依赖包...
继续阅读 >
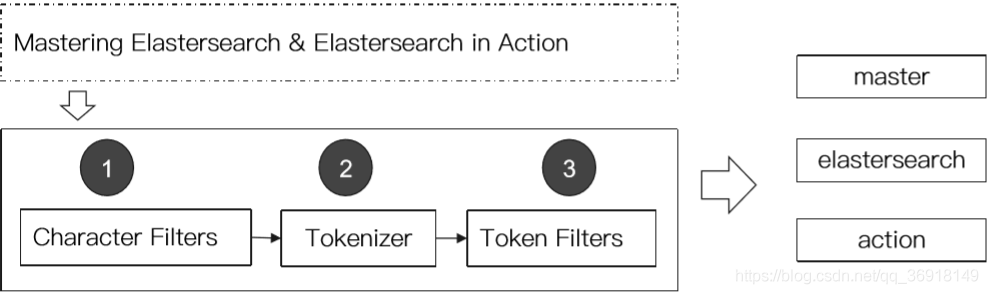 analyzer的使用规则查询只能查找倒排索引表中真实存在的项,所以保证文档在索引时与查询字符串在搜索时应用相同的分析过程非常重要,这样查询的项才能够匹配倒排索引中的项。尽管是在说文档,不过分析器可以由每个字段决定。每个字段都可以有不同的分析器,既可以通过配置为字段指定分析器,也可以使用更高层的类型(type)、索引(index)或节点(node)的默认配置。在索引时,一个字段值是根据配置或默认分析器分析的。例如...
analyzer的使用规则查询只能查找倒排索引表中真实存在的项,所以保证文档在索引时与查询字符串在搜索时应用相同的分析过程非常重要,这样查询的项才能够匹配倒排索引中的项。尽管是在说文档,不过分析器可以由每个字段决定。每个字段都可以有不同的分析器,既可以通过配置为字段指定分析器,也可以使用更高层的类型(type)、索引(index)或节点(node)的默认配置。在索引时,一个字段值是根据配置或默认分析器分析的。例如...
 elasticsearch的client,通过NewClient建立连接,通过NewClient中的Set.URL设置访问的地址,SetSniff设置集群获得连接后,通过Index方法插入数据,插入后可以通过Get方法获得数据(最后的测试用例中会使用elasticsearchclient的Get方法)funcSave(iteminterface{}){client,err:=elastic.NewClient(elastic.SetURL("http://192.168.174.128:9200/"),//Mustturnoffsniffindockerelastic.SetSn...
elasticsearch的client,通过NewClient建立连接,通过NewClient中的Set.URL设置访问的地址,SetSniff设置集群获得连接后,通过Index方法插入数据,插入后可以通过Get方法获得数据(最后的测试用例中会使用elasticsearchclient的Get方法)funcSave(iteminterface{}){client,err:=elastic.NewClient(elastic.SetURL("http://192.168.174.128:9200/"),//Mustturnoffsniffindockerelastic.SetSn...
 在互联网上,随处可见的搜索框。背后所用的技术大多数就是全文检索。在全文检索领域,常见的库/组件有:Lucene、Solr、Sphinx、ElasticSearch等。简单对比几种全文引擎的区别Lucene是一个基于Java开发的全文检索基础包,使用起来繁杂,且默认不支持分布式检索Solr是基于Lucene开发的一个搜索工具。抽象度更高,使用更简单,且提供一个控制面板。ElasticSearch也是基于Lucene开发的。同样是高度抽象,并提供了一个非常...
在互联网上,随处可见的搜索框。背后所用的技术大多数就是全文检索。在全文检索领域,常见的库/组件有:Lucene、Solr、Sphinx、ElasticSearch等。简单对比几种全文引擎的区别Lucene是一个基于Java开发的全文检索基础包,使用起来繁杂,且默认不支持分布式检索Solr是基于Lucene开发的一个搜索工具。抽象度更高,使用更简单,且提供一个控制面板。ElasticSearch也是基于Lucene开发的。同样是高度抽象,并提供了一个非常...
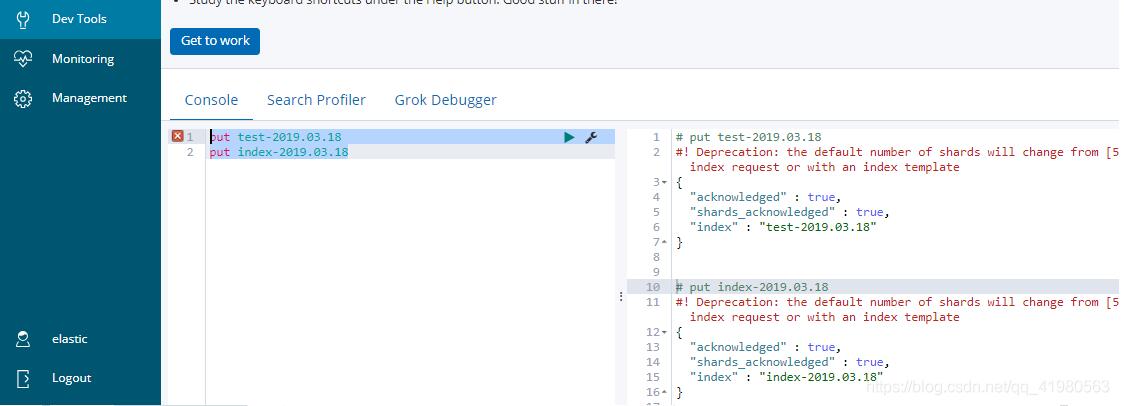 1、有的时候我们在使用ES由于资源有限或业务需求,我们只想保存最近一段时间的数据,所以有必要做定时删除数据。2、编写脚本vimdel_es_by_day.sh#!/bin/bash#定时删除elasticsearch索引#authormenard2019-3-25date=`date-d"-7days""+%Y.%m.%d"`/usr/bin/curl-v--userelastic:password-XDELETE"http://192.168.10.201:9200/*-$date"增加可执行权限chmod+xdel_es_by_day.sh3、创建用于测试的索引puttest-2019.03.18p...
1、有的时候我们在使用ES由于资源有限或业务需求,我们只想保存最近一段时间的数据,所以有必要做定时删除数据。2、编写脚本vimdel_es_by_day.sh#!/bin/bash#定时删除elasticsearch索引#authormenard2019-3-25date=`date-d"-7days""+%Y.%m.%d"`/usr/bin/curl-v--userelastic:password-XDELETE"http://192.168.10.201:9200/*-$date"增加可执行权限chmod+xdel_es_by_day.sh3、创建用于测试的索引puttest-2019.03.18p...
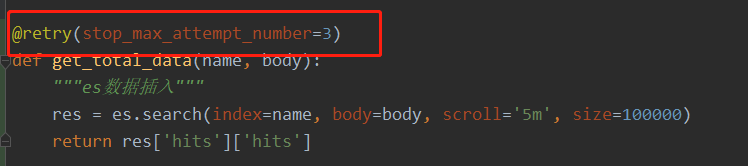
 使用ES做搜索引擎拉取数据的时候,如果数据量太大,通过传统的from+size的方式并不能获取所有的数据(默认最大记录数10000),因为随着页数的增加,会消耗大量的内存,导致ES集群不稳定。因此延伸出了scroll,search_after等翻页方式。一、from+size浅分页"浅"分页可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。GETtest/_search{"...
使用ES做搜索引擎拉取数据的时候,如果数据量太大,通过传统的from+size的方式并不能获取所有的数据(默认最大记录数10000),因为随着页数的增加,会消耗大量的内存,导致ES集群不稳定。因此延伸出了scroll,search_after等翻页方式。一、from+size浅分页"浅"分页可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。GETtest/_search{"...
 Elasticsearch是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch在ApacheLucene的基础上开发而成,由ElasticsearchN.V.(即现在的Elastic)于2010年首次发布Elasticsearch以其简单的REST风格API、分布式特性、速度和可扩展性而闻名,是ElasticStack的核心组件;ElasticStack是适用于数据采集、充实、存储、分析和可视化的一组开源工具...
Elasticsearch是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch在ApacheLucene的基础上开发而成,由ElasticsearchN.V.(即现在的Elastic)于2010年首次发布Elasticsearch以其简单的REST风格API、分布式特性、速度和可扩展性而闻名,是ElasticStack的核心组件;ElasticStack是适用于数据采集、充实、存储、分析和可视化的一组开源工具...