
2020
10-10
10-10
Java实现Twitter的分布式自增ID算法snowflake
概述分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。而twitter的snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。结构snowflake的结构如下(...
继续阅读 >
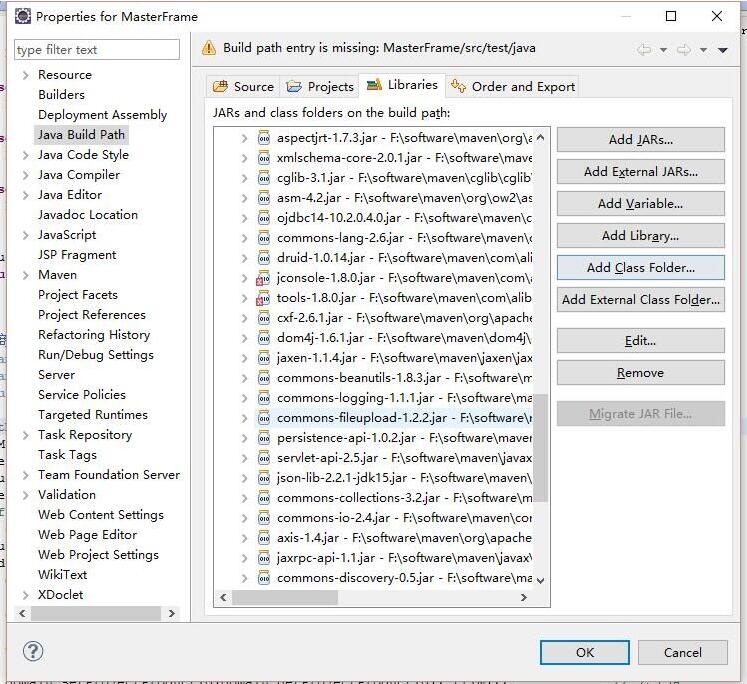 今天遇到了这样一种情况,自己的maven项目中并没有引用的jar包出现在了MavenDependencies的依赖包中。而我在pom.xml自己没有没有引入啊.图示怀疑是自己的alibaba的druid所依赖的包:<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.14</version></dependency>然后查看了它的相关依赖,果然找到了这两个依赖。解决方法是:pom.xml引入时排除掉这两个依赖:<dependency><gr...
今天遇到了这样一种情况,自己的maven项目中并没有引用的jar包出现在了MavenDependencies的依赖包中。而我在pom.xml自己没有没有引入啊.图示怀疑是自己的alibaba的druid所依赖的包:<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.14</version></dependency>然后查看了它的相关依赖,果然找到了这两个依赖。解决方法是:pom.xml引入时排除掉这两个依赖:<dependency><gr...
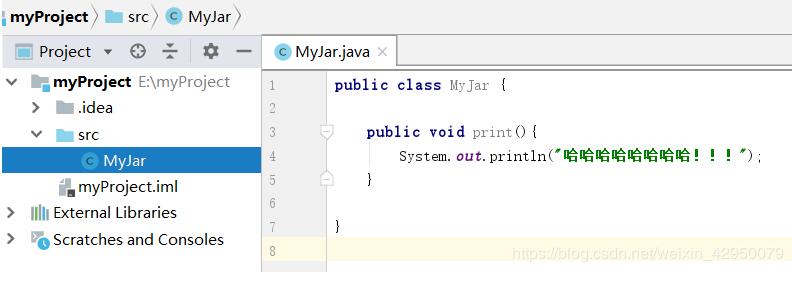 JAR文件的全称是JavaArchiveFile,即Java档案文件。JAR文件是一种压缩文件,与常见的ZIP压缩文件兼容,被称为JAR包。JAR文件与zip文件的主要区别是在JAR文件中默认包含了一个名为META-INF/MANIFEST.MF的清单文件,这个清单文件是在生成JAR文件时系统自动创建的。打包jar包1.先创建一个要打包成jar包的类2.File->ProjectStructrue->Artifacts->+->JAR->frommoduleswithdependencies…3.再MainClass中选择要打包的...
JAR文件的全称是JavaArchiveFile,即Java档案文件。JAR文件是一种压缩文件,与常见的ZIP压缩文件兼容,被称为JAR包。JAR文件与zip文件的主要区别是在JAR文件中默认包含了一个名为META-INF/MANIFEST.MF的清单文件,这个清单文件是在生成JAR文件时系统自动创建的。打包jar包1.先创建一个要打包成jar包的类2.File->ProjectStructrue->Artifacts->+->JAR->frommoduleswithdependencies…3.再MainClass中选择要打包的...
 1.问题描述在一个目录及子目录下查找TXT或Java文件,从中搜索所有“对象”字样的行。在D盘中的所有文件中搜索含有“对象”的行。2.解题思路先找出D盘下所有文件再对每个文件中的每行内容进行,进行查找,若含有“对象”两字,输出该行。3.程序代码importjava.io.File;importjava.io.IOException;importjava.util.Scanner;publicclassB{staticintm=1;staticvoidsearch(Filea,Stringx)throwsIOException{//在文件...
1.问题描述在一个目录及子目录下查找TXT或Java文件,从中搜索所有“对象”字样的行。在D盘中的所有文件中搜索含有“对象”的行。2.解题思路先找出D盘下所有文件再对每个文件中的每行内容进行,进行查找,若含有“对象”两字,输出该行。3.程序代码importjava.io.File;importjava.io.IOException;importjava.util.Scanner;publicclassB{staticintm=1;staticvoidsearch(Filea,Stringx)throwsIOException{//在文件...
 Excel的批量导入是很常见的功能,这里采用Jxl实现,数据量或样式要求较高可以采用poi框架环境:Spring+SpringMvc(注解实现)1.首先导入依赖jar包<dependency><groupId>net.sourceforge.jexcelapi</groupId><artifactId>jxl</artifactId><version>2.6.10</version></dependency>2.前端页面?jsp(enctype必须为"multipart/form-data")<%@taglibprefix="c"uri="http://java.sun.com/jsp/jstl/core"%><%@pagecontentTyp...
Excel的批量导入是很常见的功能,这里采用Jxl实现,数据量或样式要求较高可以采用poi框架环境:Spring+SpringMvc(注解实现)1.首先导入依赖jar包<dependency><groupId>net.sourceforge.jexcelapi</groupId><artifactId>jxl</artifactId><version>2.6.10</version></dependency>2.前端页面?jsp(enctype必须为"multipart/form-data")<%@taglibprefix="c"uri="http://java.sun.com/jsp/jstl/core"%><%@pagecontentTyp...
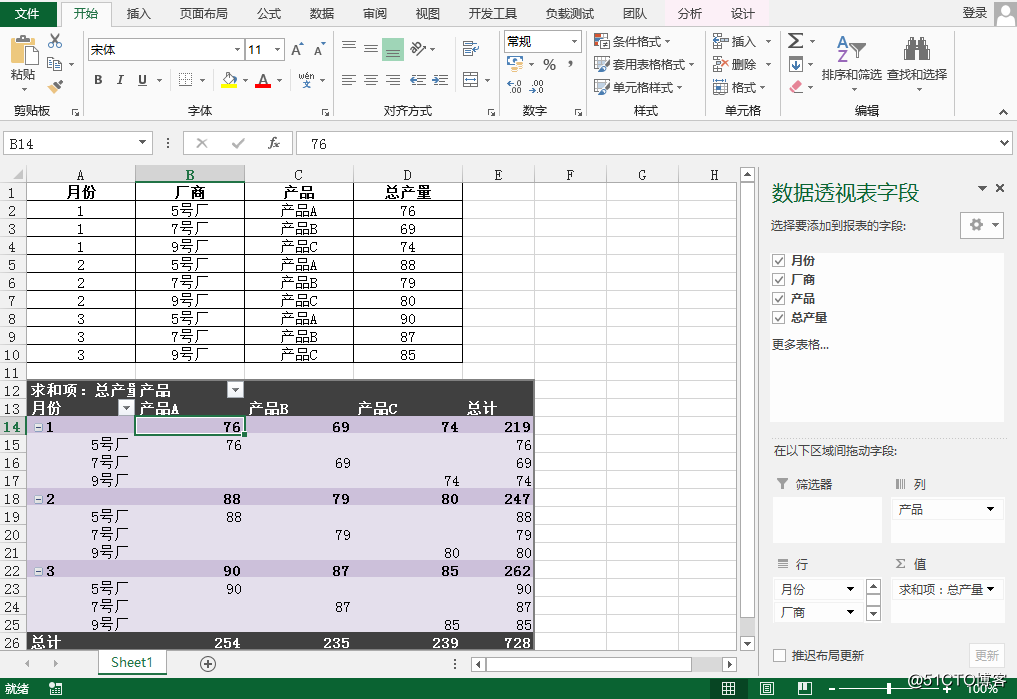 概述透视表是依据已有数据源来创建的交互式表格,我们可在excel中创建透视表,也可编辑已有透视表。所需工具:FreeSpire.XLSforJava免费版,编辑代码前,先下载导入jar到Java程序(可手动下载导入,或通过Maven仓库下载导入)。示例代码1.创建透视表importcom.spire.xls.*;publicclassCreatePivotTable{publicstaticvoidmain(String[]args){//加载Excel测试文档Workbookwb=newWorkbook();wb.loadFr...
概述透视表是依据已有数据源来创建的交互式表格,我们可在excel中创建透视表,也可编辑已有透视表。所需工具:FreeSpire.XLSforJava免费版,编辑代码前,先下载导入jar到Java程序(可手动下载导入,或通过Maven仓库下载导入)。示例代码1.创建透视表importcom.spire.xls.*;publicclassCreatePivotTable{publicstaticvoidmain(String[]args){//加载Excel测试文档Workbookwb=newWorkbook();wb.loadFr...
 插入字符代码:publicclassTest{/**在原字符中插入新字符**/publicstaticvoidmain(String[]args){StringBuffersb=newStringBuffer("田田是一个女生!");//建立一个字符缓存区,缓存区中的内容为"田田是一个女生!"System.out.println("原字符缓存区中的内容为:"+sb);//输出原字符缓存区中的内容System.out.println("原字符缓存区中的长度为:"+sb.length());//长度System.out.println("原字符缓存区中...
插入字符代码:publicclassTest{/**在原字符中插入新字符**/publicstaticvoidmain(String[]args){StringBuffersb=newStringBuffer("田田是一个女生!");//建立一个字符缓存区,缓存区中的内容为"田田是一个女生!"System.out.println("原字符缓存区中的内容为:"+sb);//输出原字符缓存区中的内容System.out.println("原字符缓存区中的长度为:"+sb.length());//长度System.out.println("原字符缓存区中...