分类:Keras
2020
10-08
2020
10-08
 如下所示:keras.callbacks.ModelCheckpoint(self.checkpoint_path,verbose=0,save_weights_only=True,mode="max",save_best_only=True),默认是每一次poch,但是这样硬盘空间很快就会被耗光.将save_best_only设置为True使其只保存最好的模型,值得一提的是其记录的acc是来自于一个monitor_op,其默认为"val_loss",其实现是取self.best为-np.Inf.所以,第一次的训练结果总是被保存.mode模式自动为auto和max一样,还有一个min的选项...
继续阅读 >
如下所示:keras.callbacks.ModelCheckpoint(self.checkpoint_path,verbose=0,save_weights_only=True,mode="max",save_best_only=True),默认是每一次poch,但是这样硬盘空间很快就会被耗光.将save_best_only设置为True使其只保存最好的模型,值得一提的是其记录的acc是来自于一个monitor_op,其默认为"val_loss",其实现是取self.best为-np.Inf.所以,第一次的训练结果总是被保存.mode模式自动为auto和max一样,还有一个min的选项...
继续阅读 >
2020
10-08
首先Keras中的fit()函数传入的x_train和y_train是被完整的加载进内存的,当然用起来很方便,但是如果我们数据量很大,那么是不可能将所有数据载入内存的,必将导致内存泄漏,这时候我们可以用fit_generator函数来进行训练。keras中文文档fitfit(x=None,y=None,batch_size=None,epochs=1,verbose=1,callbacks=None,validation_split=0.0,validation_data=None,shuffle=True,class_weight=None,sample_weight=None,initial...
继续阅读 >
2020
10-08
关于Keras中,当数据比较大时,不能全部载入内存,在训练的时候就需要利用train_on_batch或fit_generator进行训练了。两者均是利用生成器,每次载入一个batch-size的数据进行训练。那么fit_generator与train_on_batch该用哪一个呢?train_on_batch(self,x,y,class_weight=None,sample_weight=None)fit_generator(self,generator,samples_per_epoch,nb_epoch,verbose=1,callbacks=[],validation_data=None,nb_val_sample...
继续阅读 >
keras训练fit(self,x,y,batch_size=32,nb_epoch=10,verbose=1,callbacks=[],validation_split=0.0,validation_data=None,shuffle=True,class_weight=None,sample_weight=None)1.x:输入数据。如果模型只有一个输入,那么x的类型是numpyarray,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpyarray。如果模型的每个输入都有名字,则可以传入一个字典,将输入名与其输入数...
继续阅读 >

 在一个比较好的数据集中,比如在分辨不同文字的任务中,一下是几个样本使用VGG19,vol_acc和acc基本是同步保持增长的,比如40/40[==============================]-23s579ms/step-loss:1.3896-acc:0.95-val_loss:1.3876-val_acc:0.95Epoch13/1540/40[==============================]-23s579ms/step-loss:1.3829-acc:0.96-val_loss:1.3964-val_acc:0.96Epoch14/1540/40[======================...
继续阅读 >
在一个比较好的数据集中,比如在分辨不同文字的任务中,一下是几个样本使用VGG19,vol_acc和acc基本是同步保持增长的,比如40/40[==============================]-23s579ms/step-loss:1.3896-acc:0.95-val_loss:1.3876-val_acc:0.95Epoch13/1540/40[==============================]-23s579ms/step-loss:1.3829-acc:0.96-val_loss:1.3964-val_acc:0.96Epoch14/1540/40[======================...
继续阅读 >
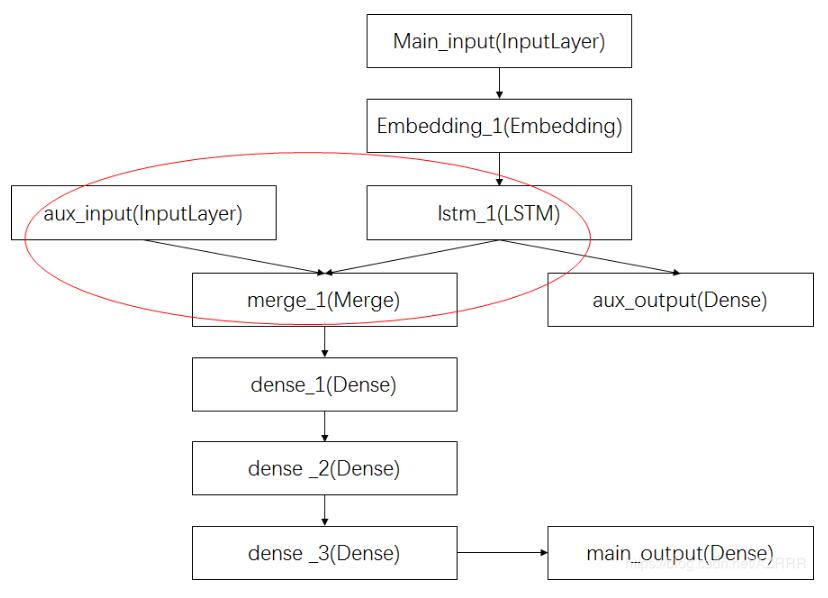 整理自keras:https://keras-cn.readthedocs.io/en/latest/other/callbacks/回调函数Callbacks回调函数是一个函数的合集,会在训练的阶段中所使用。你可以使用回调函数来查看训练模型的内在状态和统计。你可以传递一个列表的回调函数(作为callbacks关键字参数)到Sequential或Model类型的.fit()方法。在训练时,相应的回调函数的方法就会被在各自的阶段被调用。Callbackkeras.callbacks.Callback()这是回调函数的抽象类,...
整理自keras:https://keras-cn.readthedocs.io/en/latest/other/callbacks/回调函数Callbacks回调函数是一个函数的合集,会在训练的阶段中所使用。你可以使用回调函数来查看训练模型的内在状态和统计。你可以传递一个列表的回调函数(作为callbacks关键字参数)到Sequential或Model类型的.fit()方法。在训练时,相应的回调函数的方法就会被在各自的阶段被调用。Callbackkeras.callbacks.Callback()这是回调函数的抽象类,...
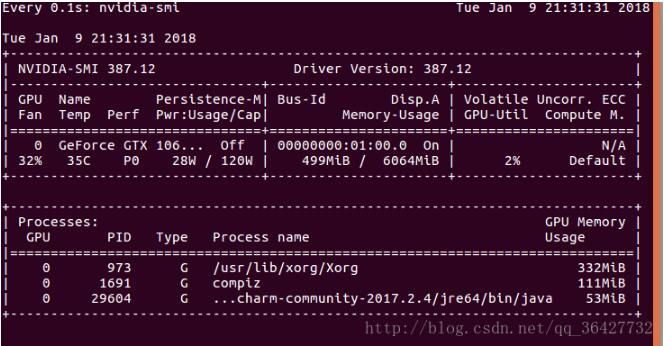 1.keras新版本中加入多GPU并行使用的函数下面程序段即可实现一个或多个GPU加速:注意:使用多GPU加速时,Keras版本必须是Keras2.0.9以上版本fromkeras.utils.training_utilsimportmulti_gpu_model#导入keras多GPU函数importVGG19#导入已经写好的函数模型,例如VGG19ifG<=1:print("[INFO]trainingwith1GPU...")model=VGG19()#otherwise,wearecompilingusingmultipleGPUselse:print("[INFO]train...
1.keras新版本中加入多GPU并行使用的函数下面程序段即可实现一个或多个GPU加速:注意:使用多GPU加速时,Keras版本必须是Keras2.0.9以上版本fromkeras.utils.training_utilsimportmulti_gpu_model#导入keras多GPU函数importVGG19#导入已经写好的函数模型,例如VGG19ifG<=1:print("[INFO]trainingwith1GPU...")model=VGG19()#otherwise,wearecompilingusingmultipleGPUselse:print("[INFO]train...
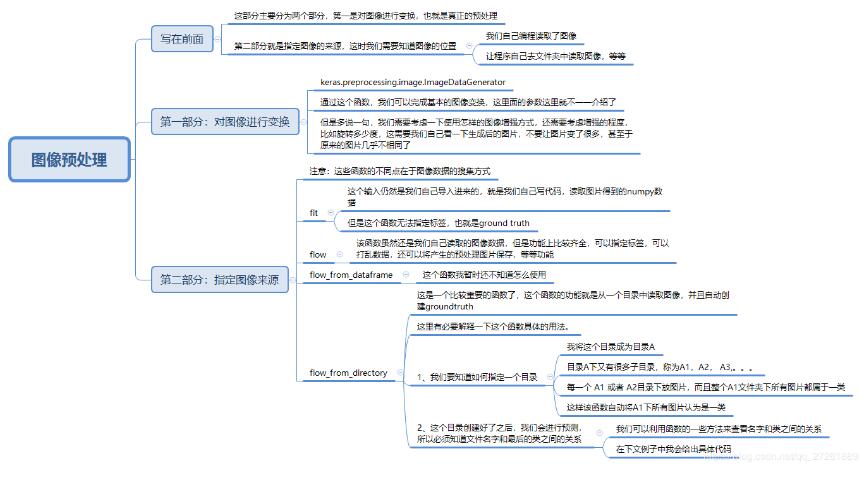
 ImageDataGenerator位于keras.preprocessing.image模块当中,可用于做数据增强,或者仅仅用于一个批次一个批次的读进图片数据.一开始以为ImageDataGenerator是用来做数据增强的,但我的目的只是想一个batch一个batch的读进图片而已,所以一开始没用它,后来发现它是有这个功能的,而且使用起来很方便.ImageDataGenerator类包含了如下参数:(keras中文教程)ImageDataGenerator(featurewise_center=False,#布尔值。将输入数据的均值设置为...
ImageDataGenerator位于keras.preprocessing.image模块当中,可用于做数据增强,或者仅仅用于一个批次一个批次的读进图片数据.一开始以为ImageDataGenerator是用来做数据增强的,但我的目的只是想一个batch一个batch的读进图片而已,所以一开始没用它,后来发现它是有这个功能的,而且使用起来很方便.ImageDataGenerator类包含了如下参数:(keras中文教程)ImageDataGenerator(featurewise_center=False,#布尔值。将输入数据的均值设置为...
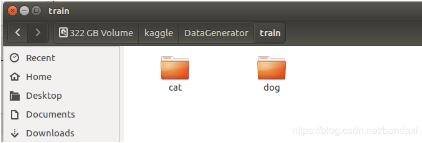
 如下所示:接下来,给出我自己目前积累的代码,从目录中自动读取图像,并产生generator:第一步:建立好目录结构和图像可以看到目录images_keras_dict下有次级目录,次级目录下就直接包含照片了**第二步:写代码建立预处理程序#先进行预处理图像train_datagen=ImageDataGenerator(rescale=1./255,rotation_range=50,height_shift_range=[-0.005,0,0.005],width_shift...
如下所示:接下来,给出我自己目前积累的代码,从目录中自动读取图像,并产生generator:第一步:建立好目录结构和图像可以看到目录images_keras_dict下有次级目录,次级目录下就直接包含照片了**第二步:写代码建立预处理程序#先进行预处理图像train_datagen=ImageDataGenerator(rescale=1./255,rotation_range=50,height_shift_range=[-0.005,0,0.005],width_shift...
 在win764位,Anaconda安装的Python3.6.1下安装的TensorFlow与Keras,Keras的backend为TensorFlow。在运行MaskR-CNN时,在进行调试时想知道PyCharm(PythonIDE)底部窗口输出的Loss格式是在哪里定义的,如下图红框中所示:图1训练过程的Loss格式化输出在上图红框中,Loss的输出格式是在哪里定义的呢?有一点是明确的,即上图红框中的内容是在训练的时候输出的。那么先来看一下MaskR-CNN的训练过程。Keras以Numpy数组作为输入数...
在win764位,Anaconda安装的Python3.6.1下安装的TensorFlow与Keras,Keras的backend为TensorFlow。在运行MaskR-CNN时,在进行调试时想知道PyCharm(PythonIDE)底部窗口输出的Loss格式是在哪里定义的,如下图红框中所示:图1训练过程的Loss格式化输出在上图红框中,Loss的输出格式是在哪里定义的呢?有一点是明确的,即上图红框中的内容是在训练的时候输出的。那么先来看一下MaskR-CNN的训练过程。Keras以Numpy数组作为输入数...
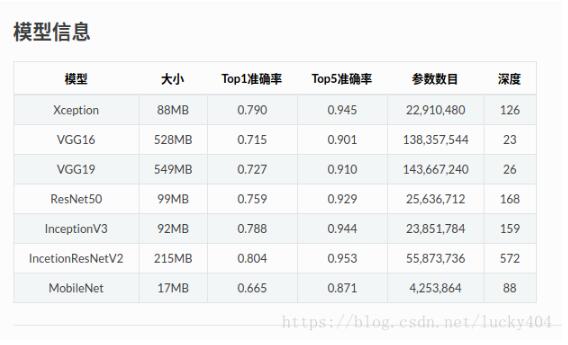 keras模块里面为我们提供了一个预训练好的模型,也就是开箱即可使用的图像识别模型趁着国庆假期有时间我们就来看看这个预训练模型如何使用吧可用的模型有哪些?根据官方文档目前可用的模型大概有如下几个1、VGG162、VGG193、ResNet504、InceptionResNetV25、InceptionV3它们都被集成到了keras.applications中模型文件从哪来当我们使用了这几个模型时,keras就会去自动下载这些已经训练好的模型保存到我们本机上面模型文件会被下...
keras模块里面为我们提供了一个预训练好的模型,也就是开箱即可使用的图像识别模型趁着国庆假期有时间我们就来看看这个预训练模型如何使用吧可用的模型有哪些?根据官方文档目前可用的模型大概有如下几个1、VGG162、VGG193、ResNet504、InceptionResNetV25、InceptionV3它们都被集成到了keras.applications中模型文件从哪来当我们使用了这几个模型时,keras就会去自动下载这些已经训练好的模型保存到我们本机上面模型文件会被下...