
2020
10-08
10-08
keras.layer.input()用法说明
tenserflow建立网络由于先建立静态的graph,所以没有数据,用placeholder来占位好申请内存。那么keras的layer类其实是一个方便的直接帮你建立深度网络中的layer的类。该类继承了object,是个基础的类,后续的诸如input_layer类都会继承与layer由于model.py中利用这个方法建立网络,所以仔细看一下:他的说明详尽而丰富。input()这个方法是用来初始化一个kerastensor的,tensor说白了就是个数组。他强大到之通过输入和输出就能建立...
继续阅读 >
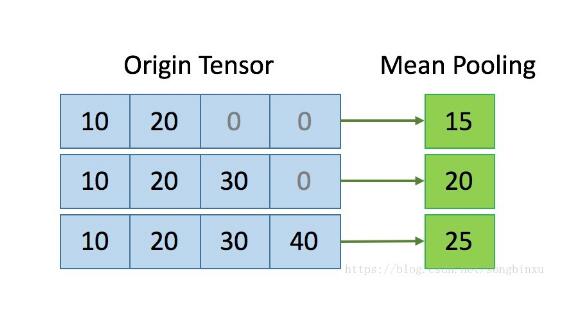 Keras确实是一大神器,代码可以写得非常简洁,但是最近在写LSTM和DeepFM的时候,遇到了一个问题:样本的长度不一样。对不定长序列的一种预处理方法是,首先对数据进行padding补0,然后引入keras的Masking层,它能自动对0值进行过滤。问题在于keras的某些层不支持Masking层处理过的输入数据,例如Flatten、AveragePooling1D等等,而其中meanpooling是我需要的一个运算。例如LSTM对每一个序列的输出长度都等于该序列的长度,那么均值...
Keras确实是一大神器,代码可以写得非常简洁,但是最近在写LSTM和DeepFM的时候,遇到了一个问题:样本的长度不一样。对不定长序列的一种预处理方法是,首先对数据进行padding补0,然后引入keras的Masking层,它能自动对0值进行过滤。问题在于keras的某些层不支持Masking层处理过的输入数据,例如Flatten、AveragePooling1D等等,而其中meanpooling是我需要的一个运算。例如LSTM对每一个序列的输出长度都等于该序列的长度,那么均值...
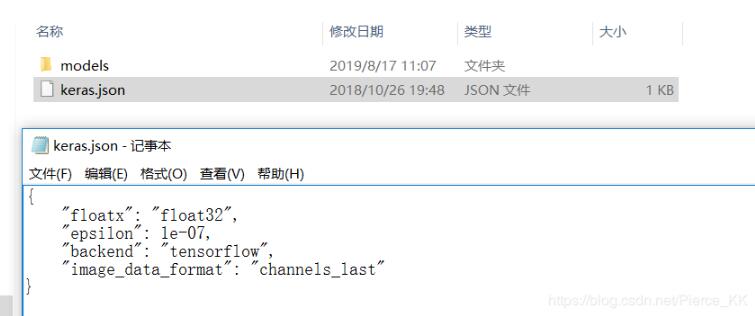 keras后端简介:Keras是一个模型级库,为开发深度学习模型提供了高层次的构建模块。它不处理诸如张量乘积和卷积等底层操作,目的也就是尽量不重复造轮子。但是底层操作还是需要的,所以keras依赖于一个专门的、优化的张量操作库来完成这个操作。我们可以简单的认为这是Keras的「后端引擎」,keras有三个后端实现可用、即:TensorFlow后端,Theano后端,CNTK后端。如果你需要修改你的后端,只要将字段backend更改为...
keras后端简介:Keras是一个模型级库,为开发深度学习模型提供了高层次的构建模块。它不处理诸如张量乘积和卷积等底层操作,目的也就是尽量不重复造轮子。但是底层操作还是需要的,所以keras依赖于一个专门的、优化的张量操作库来完成这个操作。我们可以简单的认为这是Keras的「后端引擎」,keras有三个后端实现可用、即:TensorFlow后端,Theano后端,CNTK后端。如果你需要修改你的后端,只要将字段backend更改为...
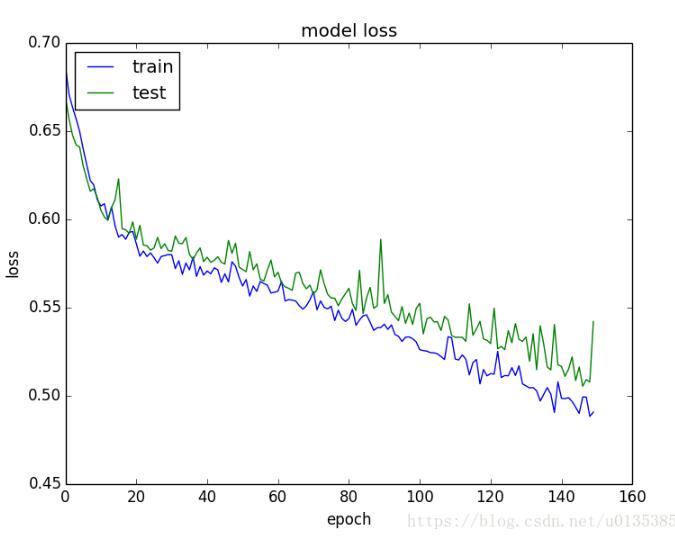 详细的解释,读者自行打开这个链接查看,我这里只把最重要的说下fit()方法会返回一个训练期间历史数据记录对象,包含trainingerror,trainingaccuracy,validationerror,validationaccuracy字段,如下打印#listalldatainhistoryprint(history.history.keys())完整代码#Visualizetraininghistoryfromkeras.modelsimportSequentialfromkeras.layersimportDenseimportmatplotlib.pyplotaspltimportnumpy#...
详细的解释,读者自行打开这个链接查看,我这里只把最重要的说下fit()方法会返回一个训练期间历史数据记录对象,包含trainingerror,trainingaccuracy,validationerror,validationaccuracy字段,如下打印#listalldatainhistoryprint(history.history.keys())完整代码#Visualizetraininghistoryfromkeras.modelsimportSequentialfromkeras.layersimportDenseimportmatplotlib.pyplotaspltimportnumpy#...
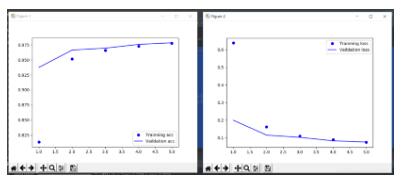 1.在搭建网络开始时,会调用到keras.models的Sequential()方法,返回一个model参数表示模型2.model参数里面有个fit()方法,用于把训练集传进网络。fit()返回一个参数,该参数包含训练集和验证集的准确性acc和错误值loss,用这些数据画成图表即可。如:history=model.fit(x_train,y_train,batch_size=32,epochs=5,validation_split=0.25)#获取数据#########画图acc=history.history['acc']#获取训练集准确性数据val_acc...
1.在搭建网络开始时,会调用到keras.models的Sequential()方法,返回一个model参数表示模型2.model参数里面有个fit()方法,用于把训练集传进网络。fit()返回一个参数,该参数包含训练集和验证集的准确性acc和错误值loss,用这些数据画成图表即可。如:history=model.fit(x_train,y_train,batch_size=32,epochs=5,validation_split=0.25)#获取数据#########画图acc=history.history['acc']#获取训练集准确性数据val_acc...
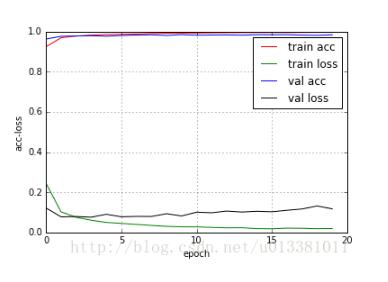 我就废话不多说了,大家还是直接看代码吧!#加载keras模块from__future__importprint_functionimportnumpyasnpnp.random.seed(1337)#forreproducibilityimportkerasfromkeras.datasetsimportmnistfromkeras.modelsimportSequentialfromkeras.layers.coreimportDense,Dropout,Activationfromkeras.optimizersimportSGD,Adam,RMSpropfromkeras.utilsimportnp_utilsimportmatplotlib.pyplotasplt%mat...
我就废话不多说了,大家还是直接看代码吧!#加载keras模块from__future__importprint_functionimportnumpyasnpnp.random.seed(1337)#forreproducibilityimportkerasfromkeras.datasetsimportmnistfromkeras.modelsimportSequentialfromkeras.layers.coreimportDense,Dropout,Activationfromkeras.optimizersimportSGD,Adam,RMSpropfromkeras.utilsimportnp_utilsimportmatplotlib.pyplotasplt%mat...
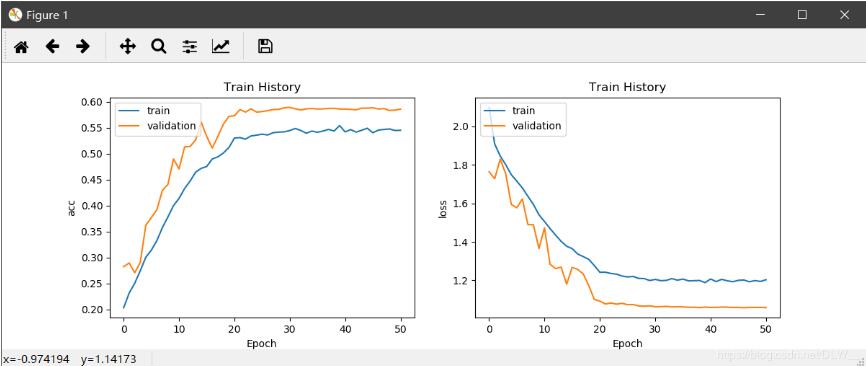 训练曲线defshow_train_history(train_history,train_metrics,validation_metrics):plt.plot(train_history.history[train_metrics])plt.plot(train_history.history[validation_metrics])plt.title('TrainHistory')plt.ylabel(train_metrics)plt.xlabel('Epoch')plt.legend(['train','validation'],loc='upperleft')#显示训练过程defplot(history):plt.figure(figsize=(12,4))plt.subplot(1,2,1)show_train_...
训练曲线defshow_train_history(train_history,train_metrics,validation_metrics):plt.plot(train_history.history[train_metrics])plt.plot(train_history.history[validation_metrics])plt.title('TrainHistory')plt.ylabel(train_metrics)plt.xlabel('Epoch')plt.legend(['train','validation'],loc='upperleft')#显示训练过程defplot(history):plt.figure(figsize=(12,4))plt.subplot(1,2,1)show_train_...
 介绍本博文中的代码,实现的是加载训练好的模型model_halcon_resenet.h5,并把该模型的参数赋值给两个不同的新的model。函数式模型官网上给出的调用一个训练好模型,并输出任意层的feature。model=Model(inputs=base_model.input,outputs=base_model.get_layer(‘block4_pool').output)但是这有一个问题,就是新的model,如果输入inputs和训练好的model的inputs大小不同呢?比如我想建立一个输入是600x600x3的新model,但是训练...
介绍本博文中的代码,实现的是加载训练好的模型model_halcon_resenet.h5,并把该模型的参数赋值给两个不同的新的model。函数式模型官网上给出的调用一个训练好模型,并输出任意层的feature。model=Model(inputs=base_model.input,outputs=base_model.get_layer(‘block4_pool').output)但是这有一个问题,就是新的model,如果输入inputs和训练好的model的inputs大小不同呢?比如我想建立一个输入是600x600x3的新model,但是训练...
 使用keras搭建好一个模型,训练好,怎么得到每层的系数呢:weights=np.array(model.get_weights())print(weights)print(weights[0].shape)print(weights[1].shape)这样系数就被存放到一个np中了。补充知识:使用keras框架编写的深度模型输出及每一层的特征可视化使用训练好的模型进行预测的时候,为分析效果,通常需要对特征提取过程中的特征映射做可视化操作本文以keras为例,对特征可视化操作进行详解。一、首先,对模型的最...
使用keras搭建好一个模型,训练好,怎么得到每层的系数呢:weights=np.array(model.get_weights())print(weights)print(weights[0].shape)print(weights[1].shape)这样系数就被存放到一个np中了。补充知识:使用keras框架编写的深度模型输出及每一层的特征可视化使用训练好的模型进行预测的时候,为分析效果,通常需要对特征提取过程中的特征映射做可视化操作本文以keras为例,对特征可视化操作进行详解。一、首先,对模型的最...
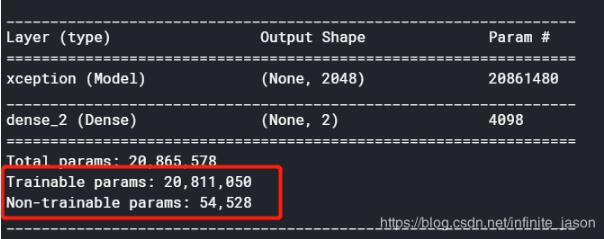 在解决一个任务时,我会选择加载预训练模型并逐步fine-tune。比如,分类任务中,优异的深度学习网络有很多。ResNet,VGG,Xception等等...并且这些模型参数已经在imagenet数据集中训练的很好了,可以直接拿过来用。根据自己的任务,训练一下最后的分类层即可得到比较好的结果。此时,就需要“冻结”预训练模型的所有层,即这些层的权重永不会更新。以Xception为例:加载预训练模型:fromtensorflow.python.keras.applicationsim...
在解决一个任务时,我会选择加载预训练模型并逐步fine-tune。比如,分类任务中,优异的深度学习网络有很多。ResNet,VGG,Xception等等...并且这些模型参数已经在imagenet数据集中训练的很好了,可以直接拿过来用。根据自己的任务,训练一下最后的分类层即可得到比较好的结果。此时,就需要“冻结”预训练模型的所有层,即这些层的权重永不会更新。以Xception为例:加载预训练模型:fromtensorflow.python.keras.applicationsim...