
2020
10-10
10-10
python输入中文的实例方法
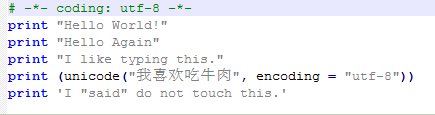 解决中文输入的两种应用:在脚本中加语言编码声明“-*-coding:uft-8-*-”应用一:print中出现中文方法一:用unicode('',encoding='utf-8')或者unicode("",encoding="utf-8")。方法二:用u''或者u""。应用二:函数输入中出现中文,如raw_input()用unicode('','utf-8').encode('gbk')或者unicode("","utf-8").encode("gbk") 方法一:unicode()转码,声明是gbk,对文字打印统一声明。方法二...
继续阅读 >
解决中文输入的两种应用:在脚本中加语言编码声明“-*-coding:uft-8-*-”应用一:print中出现中文方法一:用unicode('',encoding='utf-8')或者unicode("",encoding="utf-8")。方法二:用u''或者u""。应用二:函数输入中出现中文,如raw_input()用unicode('','utf-8').encode('gbk')或者unicode("","utf-8").encode("gbk") 方法一:unicode()转码,声明是gbk,对文字打印统一声明。方法二...
继续阅读 >
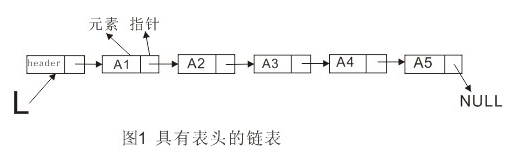 python中的链表(linkedlist)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接。链表有两种类型:单链表和双链表。链表的数据结构如下图所示:在链表中删除操作可以通过修改指针来实现,如下图所示:插入则是调整,插入点的前后两个指针的指向关系,如下图所示:在python中每个变量都是指针,例如:用内置数据结构(list,dict,tuple等)的嵌套/组合,它们隐式地包含了指向/嵌套关...
python中的链表(linkedlist)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接。链表有两种类型:单链表和双链表。链表的数据结构如下图所示:在链表中删除操作可以通过修改指针来实现,如下图所示:插入则是调整,插入点的前后两个指针的指向关系,如下图所示:在python中每个变量都是指针,例如:用内置数据结构(list,dict,tuple等)的嵌套/组合,它们隐式地包含了指向/嵌套关...
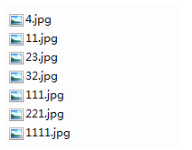 在python环境中提供两种排序方案:用库函数sorted()对字符串排序,它的对象是字符;用函数sort()对数字排序,它的对象是数字,如果读取文件的话,需要进行处理(把文件后缀名‘屏蔽')。(1)首先:我测试的文件夹是/img/,里面的文件都是图片,如下图所示:(2)测试库函数sorted(),直接贴出代码:import numpy as npimport os img_path='./img/' img_list=sorted(os.listdir(img_path))#文件名按...
在python环境中提供两种排序方案:用库函数sorted()对字符串排序,它的对象是字符;用函数sort()对数字排序,它的对象是数字,如果读取文件的话,需要进行处理(把文件后缀名‘屏蔽')。(1)首先:我测试的文件夹是/img/,里面的文件都是图片,如下图所示:(2)测试库函数sorted(),直接贴出代码:import numpy as npimport os img_path='./img/' img_list=sorted(os.listdir(img_path))#文件名按...
 1、介绍在爬虫中经常会遇到验证码识别的问题,现在的验证码大多分计算验证码、滑块验证码、识图验证码、语音验证码等四种。本文就是识图验证码,识别的是简单的验证码,要想让识别率更高,识别的更加准确就需要花很多的精力去训练自己的字体库。识别验证码通常是这几个步骤:(1)灰度处理(2)二值化(3)去除边框(如果有的话)(4)降噪(5)切割字符或者倾斜度矫正(6)训练字体库(7)识别这6个步骤中前三个步骤是基本的,4或...
1、介绍在爬虫中经常会遇到验证码识别的问题,现在的验证码大多分计算验证码、滑块验证码、识图验证码、语音验证码等四种。本文就是识图验证码,识别的是简单的验证码,要想让识别率更高,识别的更加准确就需要花很多的精力去训练自己的字体库。识别验证码通常是这几个步骤:(1)灰度处理(2)二值化(3)去除边框(如果有的话)(4)降噪(5)切割字符或者倾斜度矫正(6)训练字体库(7)识别这6个步骤中前三个步骤是基本的,4或...
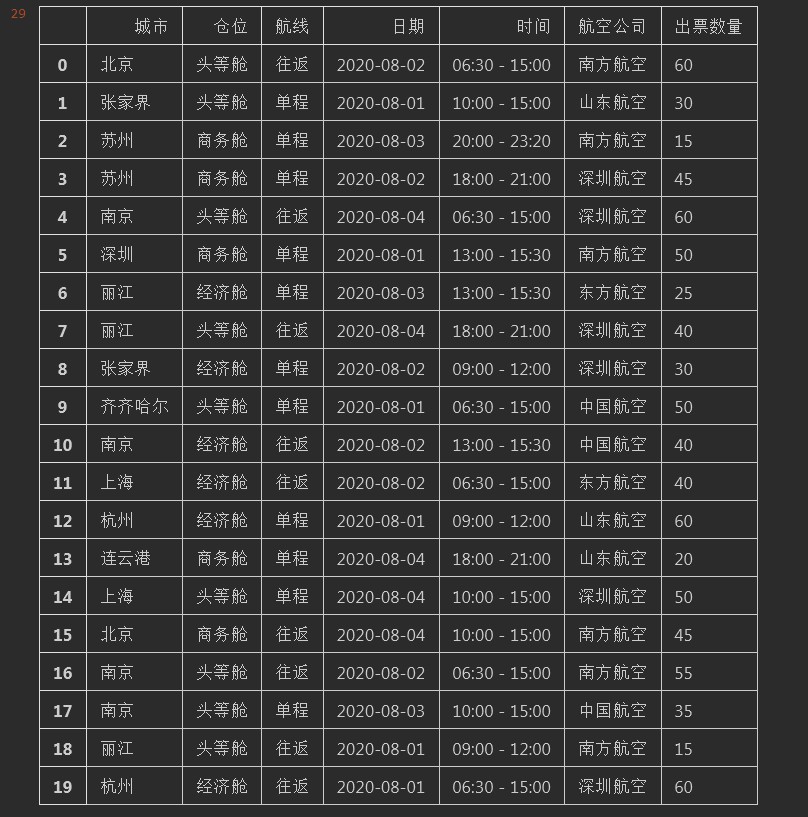 CategoricalDtype自定义排序当我们的透视表生成完毕后,有很多情况下需要我们对某列或某行值进行排序。排序有很多种方法。例如sort_index及sort_values函数也可以对数据进行排序,这里就不多说了。对于数值和字母的排序很容易,但是对于中文的排序就有点麻烦了。默认情况下是按照utf-8的编码来进行排序的但是即使如此也很难满足我们对汉字排序的要求。所以通过CategoricalDtye可以把数据类型转成Category类型然后通过指定参数列表...
CategoricalDtype自定义排序当我们的透视表生成完毕后,有很多情况下需要我们对某列或某行值进行排序。排序有很多种方法。例如sort_index及sort_values函数也可以对数据进行排序,这里就不多说了。对于数值和字母的排序很容易,但是对于中文的排序就有点麻烦了。默认情况下是按照utf-8的编码来进行排序的但是即使如此也很难满足我们对汉字排序的要求。所以通过CategoricalDtye可以把数据类型转成Category类型然后通过指定参数列表...
 Pivot及Pivot_table函数用法Pivot和Pivot_table函数都是对数据做透视表而使用的。其中的区别在于Pivot_table可以支持重复元素的聚合操作,而Pivot函数只能对不重复的元素进行聚合操作。在一般的日常业务中,因为Pivot_table的功能更为强大,Pivot能做的不能做的Pivot_table都可做。所以只需要记住Pivot_table函数用法就好了。Pivot函数的使用演示#%%importpandasaspddf01=pd.DataFrame({"年份":[2019,2019,2019,2020,2...
Pivot及Pivot_table函数用法Pivot和Pivot_table函数都是对数据做透视表而使用的。其中的区别在于Pivot_table可以支持重复元素的聚合操作,而Pivot函数只能对不重复的元素进行聚合操作。在一般的日常业务中,因为Pivot_table的功能更为强大,Pivot能做的不能做的Pivot_table都可做。所以只需要记住Pivot_table函数用法就好了。Pivot函数的使用演示#%%importpandasaspddf01=pd.DataFrame({"年份":[2019,2019,2019,2020,2...
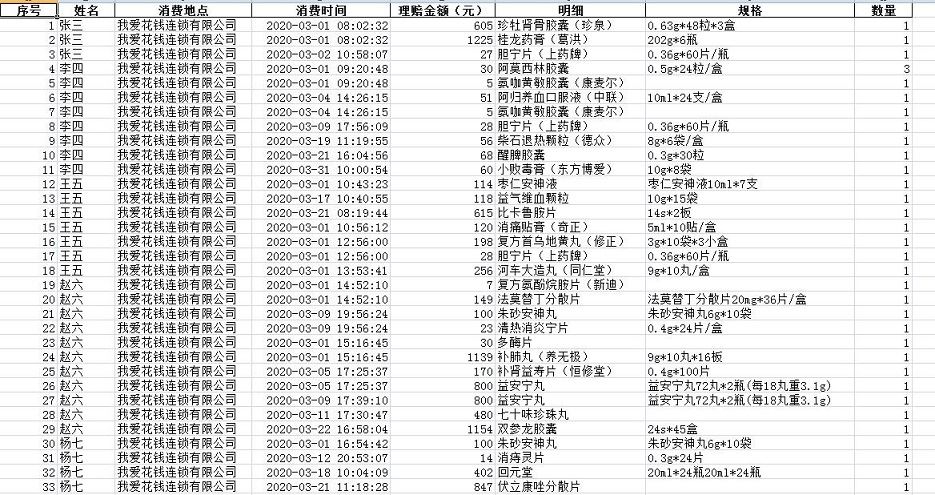 一,extract方法的使用extract函数主要是对于数据进行提取。场景一般对于DataFrame中的一列中的数据进行提取的场合比较多。例如一列中包含了很长的字段,我们希望在这些字段中提取出我们想要的字段时,就可以通过extract方法进行数据的提取了。好了,废话不多说直接上代码。数据源序号姓名服务卡卡号消费地点消费时间理赔金额(元)交易明细数量1张三8100001我爱花钱连锁有限公司2020/3/18:02605珍牡肾...
一,extract方法的使用extract函数主要是对于数据进行提取。场景一般对于DataFrame中的一列中的数据进行提取的场合比较多。例如一列中包含了很长的字段,我们希望在这些字段中提取出我们想要的字段时,就可以通过extract方法进行数据的提取了。好了,废话不多说直接上代码。数据源序号姓名服务卡卡号消费地点消费时间理赔金额(元)交易明细数量1张三8100001我爱花钱连锁有限公司2020/3/18:02605珍牡肾...