
2020
10-09
10-09
基于Python爬取51cto博客页面信息过程解析
介绍提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码!实验环境1.安装Python3.72.安装requests,bs4模块实验步骤1.安装Python3.7环境2.安装requests,bs4模块打开cmd,输入:pipinstallrequests-ihttps://pypi.tuna.tsinghua.edu.cn/simple/再安装bs4,输入...
继续阅读 >
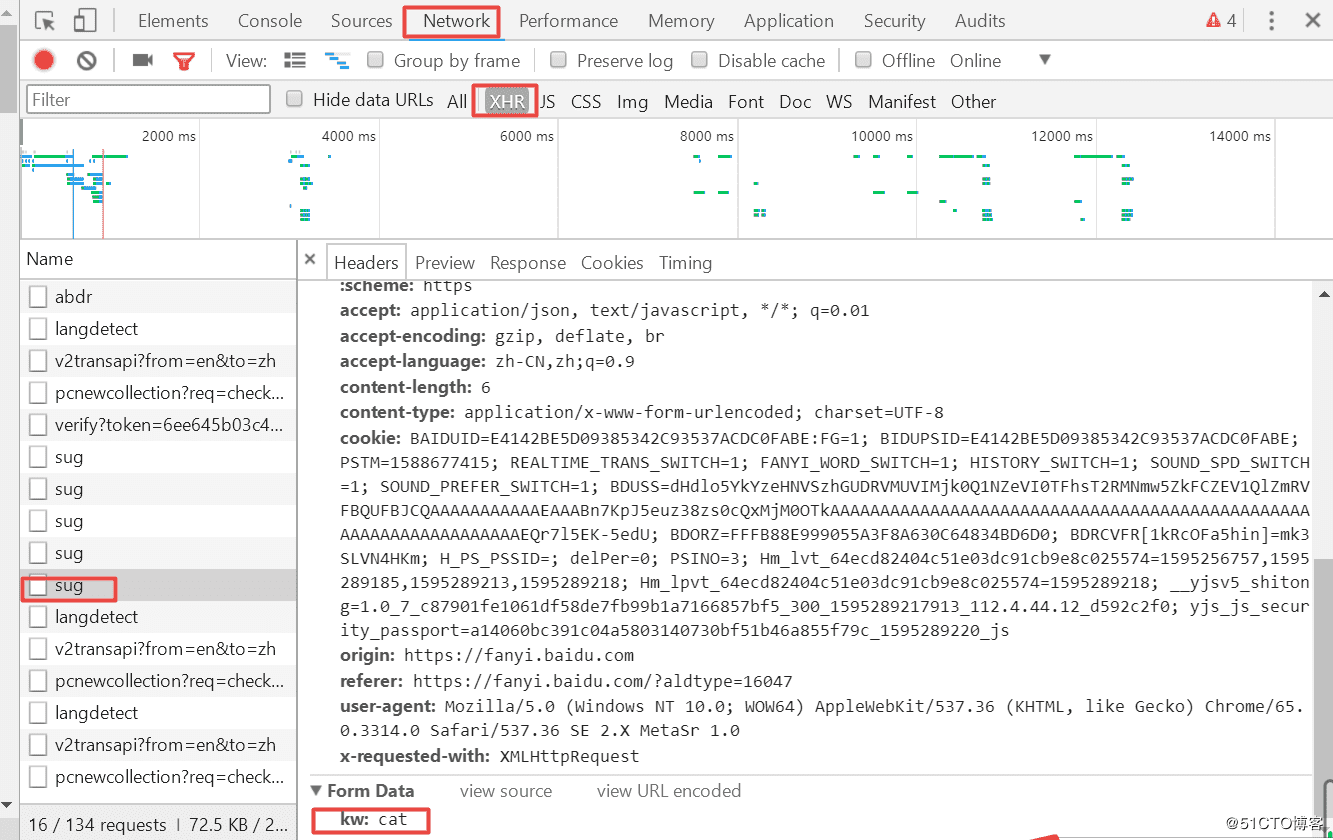 requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。作用:模拟浏览器发请求。提示:老版使用urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可!requests模块编码流程指定url1.1UA伪装1.2请求参数的处理2.发起请求3.获取响应数据4.持久化存储环境安装:pipinstallrequests案例一:破解百度翻译(post请求)1.代码如下:#爬取百度翻译#导入模块importrequestsi...
requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。作用:模拟浏览器发请求。提示:老版使用urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可!requests模块编码流程指定url1.1UA伪装1.2请求参数的处理2.发起请求3.获取响应数据4.持久化存储环境安装:pipinstallrequests案例一:破解百度翻译(post请求)1.代码如下:#爬取百度翻译#导入模块importrequestsi...
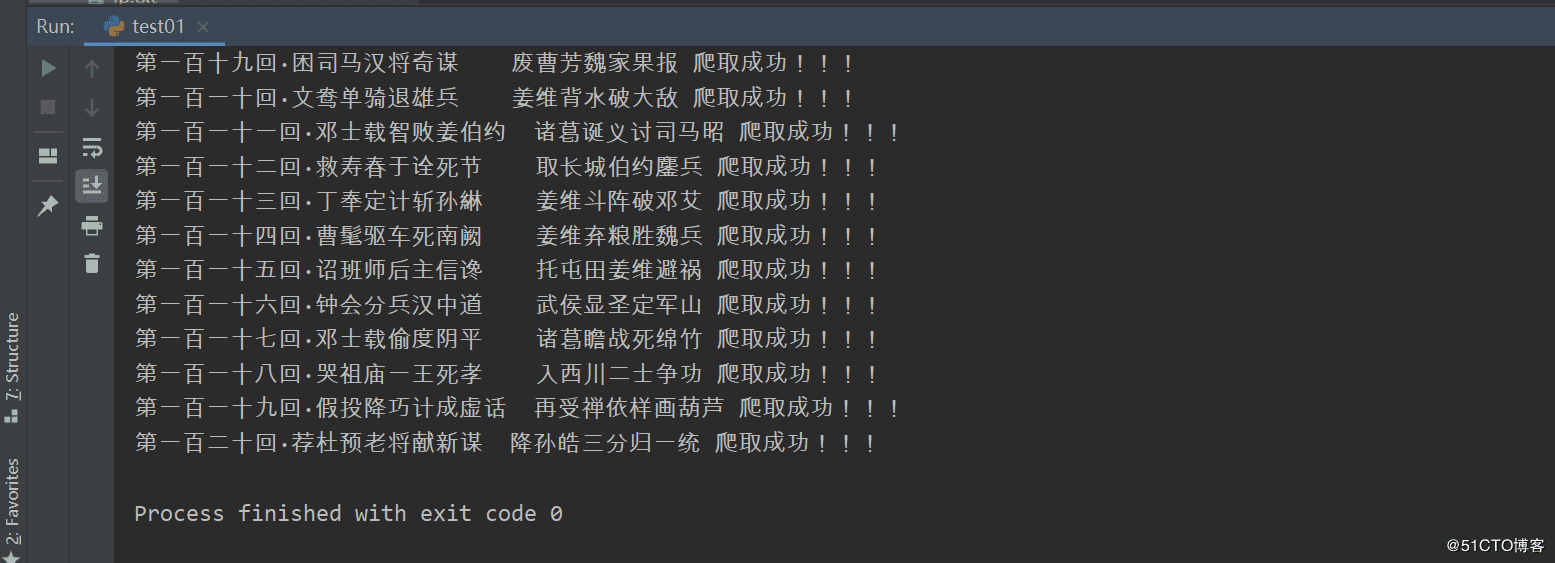 聚焦爬虫:爬取页面中指定的页面内容。编码流程:1.指定url2.发起请求3.获取响应数据4.数据解析5.持久化存储数据解析分类:1.bs42.正则3.xpath(***)数据解析原理概述:解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储1.进行指定标签的定位2.标签或者标签对应的属性中存储的数据值进行提取(解析)bs4进行数据解析数据解析的原理:1.标签定位2.提取标签、标签属性中存储的数据值bs4数据解析的原理...
聚焦爬虫:爬取页面中指定的页面内容。编码流程:1.指定url2.发起请求3.获取响应数据4.数据解析5.持久化存储数据解析分类:1.bs42.正则3.xpath(***)数据解析原理概述:解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储1.进行指定标签的定位2.标签或者标签对应的属性中存储的数据值进行提取(解析)bs4进行数据解析数据解析的原理:1.标签定位2.提取标签、标签属性中存储的数据值bs4数据解析的原理...
 前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出。现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论。最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^。实...
前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出。现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论。最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^。实...
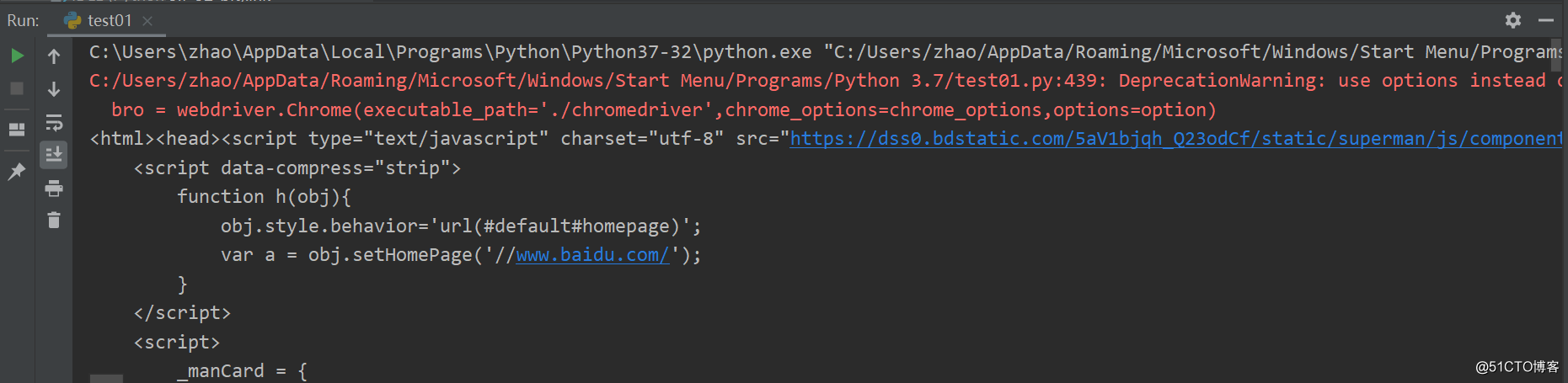 无可视化界面的意义有时候我们爬取网页数据,并不希望看其中的过程,只想看到最后的数据结果就可以了,这时候,***面就很有必要了!代码如下fromseleniumimportwebdriverfromtimeimportsleep#实现无可视化界面fromselenium.webdriver.chrome.optionsimportOptions#实现规避检测fromselenium.webdriverimportChromeOptions#实现无可视化界面的操作chrome_options=Options()chrome_options.add_argument('--headless')...
无可视化界面的意义有时候我们爬取网页数据,并不希望看其中的过程,只想看到最后的数据结果就可以了,这时候,***面就很有必要了!代码如下fromseleniumimportwebdriverfromtimeimportsleep#实现无可视化界面fromselenium.webdriver.chrome.optionsimportOptions#实现规避检测fromselenium.webdriverimportChromeOptions#实现无可视化界面的操作chrome_options=Options()chrome_options.add_argument('--headless')...
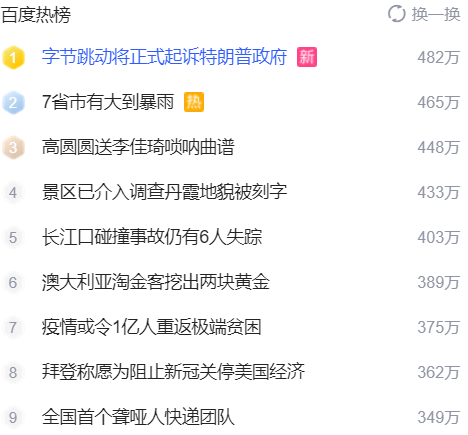 目标网址:https://www.baidu.com/要获取的内容:链接分析:从下图可以看出只需要获取关键字,再构建就可以了。完整代码:import requestsimport pprintimport reimport urllib.parseurl = 'https://www.baidu.com/'headers = { 'Host': 'www.baidu.com', 'Referer': 'https://www.baidu.com/', 'User-A...
目标网址:https://www.baidu.com/要获取的内容:链接分析:从下图可以看出只需要获取关键字,再构建就可以了。完整代码:import requestsimport pprintimport reimport urllib.parseurl = 'https://www.baidu.com/'headers = { 'Host': 'www.baidu.com', 'Referer': 'https://www.baidu.com/', 'User-A...
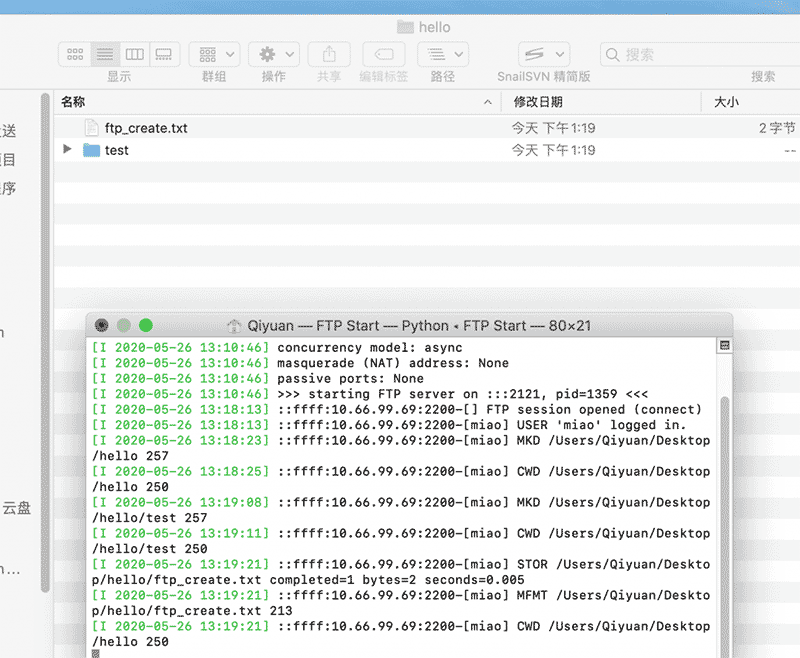 在同一个局域网的多台电脑,传递文件时可以通过搭建web服务器,设置目录浏览的方式快速分享。如果上传就比较麻烦了,通过QQ/微信会产生很多文件记录,通过teamviewer太慢,ftp是一个不错的选择。FTP服务器软件在日常开发中,基本不会用到。还涉及macOS、Windows的环境差异,非常麻烦。虽然有免费开源的filezzila,配置还是很繁琐的。开发机都安装了python,安装pyftpdlib库就可以解决这个问题。一条命令即可解决(使用前需要...
在同一个局域网的多台电脑,传递文件时可以通过搭建web服务器,设置目录浏览的方式快速分享。如果上传就比较麻烦了,通过QQ/微信会产生很多文件记录,通过teamviewer太慢,ftp是一个不错的选择。FTP服务器软件在日常开发中,基本不会用到。还涉及macOS、Windows的环境差异,非常麻烦。虽然有免费开源的filezzila,配置还是很繁琐的。开发机都安装了python,安装pyftpdlib库就可以解决这个问题。一条命令即可解决(使用前需要...