
2021
04-07
04-07
Pandas提取单元格的值操作
如提取第1行,第2列的值:df.iloc[[0],[1]]则会返回一个df,即有字段名和行号。如果用values属性取值:df.iloc[[0],[1]].values返回的值会是列表,而且是嵌套列表:[[值]]因此,正确的写法是:df.iloc[[0],[1]].values[0][0]补充:pandas取出符合条件的某单元格的值已经读取excel表中的值,得出DATAFRAME-----data1想取出某些值写入另一个excel表发现用data1[‘任务指标利润总额'][data1[‘企业']==namelist],给excel表中的单元格...
继续阅读 >
 pandas读取txt文件读取txt文件需要确定txt文件是否符合基本的格式,也就是是否存在\t,,,等特殊的分隔符一般txt文件长成这个样子txt文件举例下面的文件为空格间隔12019-03-2200:06:24.4463094中文测试22019-03-2200:06:32.4565680需要编辑encoding32019-03-2200:06:32.6835965ashshsh42017-03-2200:06:32.8041945eggg读取命令采用read_csv或者read_table都可以importpandasaspddf=pd.read_table("./test.txt"...
pandas读取txt文件读取txt文件需要确定txt文件是否符合基本的格式,也就是是否存在\t,,,等特殊的分隔符一般txt文件长成这个样子txt文件举例下面的文件为空格间隔12019-03-2200:06:24.4463094中文测试22019-03-2200:06:32.4565680需要编辑encoding32019-03-2200:06:32.6835965ashshsh42017-03-2200:06:32.8041945eggg读取命令采用read_csv或者read_table都可以importpandasaspddf=pd.read_table("./test.txt"...
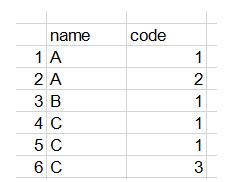 在对dataframe进行分析的时候会遇到需要分组计数,计数的column中属性有重复,但又需要仅对不重复的项计数(即重复N次出现的项只计1次)。函数如下:dataframe.groupby([‘分组的列名']).需要计数的列名.nunique()举例:数组“data”如下:StoreIDSalesSalesDateChannelA1002018/1/101A902018/1/102A110...
在对dataframe进行分析的时候会遇到需要分组计数,计数的column中属性有重复,但又需要仅对不重复的项计数(即重复N次出现的项只计1次)。函数如下:dataframe.groupby([‘分组的列名']).需要计数的列名.nunique()举例:数组“data”如下:StoreIDSalesSalesDateChannelA1002018/1/101A902018/1/102A110...
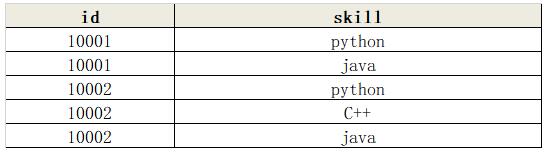 pandas列转换为字典,但将相同第一列(键)的所有值合并为一个键形式一:importpandasaspd#datadata=pd.DataFrame({'column1':['key1','key1','key2','key2'],'column2':['value1','value2','value3','value3']})print(data)#Groupeddictdata_dict=data.groupby('column1').column2.apply(list).to_dict()print(data_dict)输出结果:column1column20key1value11key1value22key2value33key2value3{...
pandas列转换为字典,但将相同第一列(键)的所有值合并为一个键形式一:importpandasaspd#datadata=pd.DataFrame({'column1':['key1','key1','key2','key2'],'column2':['value1','value2','value3','value3']})print(data)#Groupeddictdata_dict=data.groupby('column1').column2.apply(list).to_dict()print(data_dict)输出结果:column1column20key1value11key1value22key2value33key2value3{...
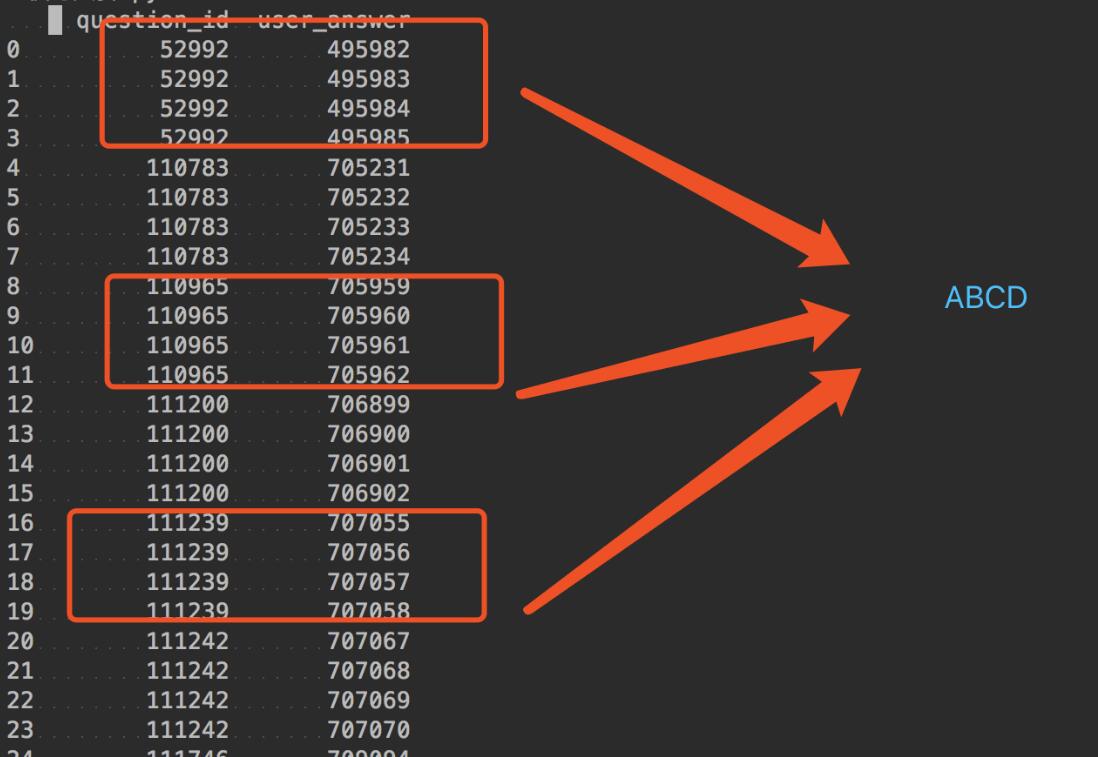 目的:把question_id对应的user_answer转成ABCDsolutiondfa=df.groupby('question_id').nth(0).reset_index()dfa['flag']='A'dfb=df.groupby('question_id').nth(1).reset_index()dfb['flag']='B'dfc=df.groupby('question_id').nth(2).reset_index()dfc['flag']='C'dfd=df.groupby('question_id').nth(3).reset_index()dfd['flag']='D'resdf=dfa.append([dfb,dfc,dfd])resdf.sort_values(by='question_id')result:focus:g.nth(...
目的:把question_id对应的user_answer转成ABCDsolutiondfa=df.groupby('question_id').nth(0).reset_index()dfa['flag']='A'dfb=df.groupby('question_id').nth(1).reset_index()dfb['flag']='B'dfc=df.groupby('question_id').nth(2).reset_index()dfc['flag']='C'dfd=df.groupby('question_id').nth(3).reset_index()dfd['flag']='D'resdf=dfa.append([dfb,dfc,dfd])resdf.sort_values(by='question_id')result:focus:g.nth(...
 agg方法将一个函数使用在一个数列上,然后返回一个标量的值。也就是说agg每次传入的是一列数据,对其聚合后返回标量。对一列使用三个函数:对不同列使用不同函数apply是一个更一般化的方法:将一个数据分拆-应用-汇总。而apply会将当前分组后的数据一起传入,可以返回多维数据。实例:1、数据如下:lawsuit2[['EID','LAWAMOUNT','LAWDATE']]2、groupby后应用apply传入函数数据如下:lawsuit2[['EID','LAWAMOUNT','LAWDATE']].gro...
agg方法将一个函数使用在一个数列上,然后返回一个标量的值。也就是说agg每次传入的是一列数据,对其聚合后返回标量。对一列使用三个函数:对不同列使用不同函数apply是一个更一般化的方法:将一个数据分拆-应用-汇总。而apply会将当前分组后的数据一起传入,可以返回多维数据。实例:1、数据如下:lawsuit2[['EID','LAWAMOUNT','LAWDATE']]2、groupby后应用apply传入函数数据如下:lawsuit2[['EID','LAWAMOUNT','LAWDATE']].gro...