
2020
12-14
12-14
python绘图pyecharts+pandas的使用详解
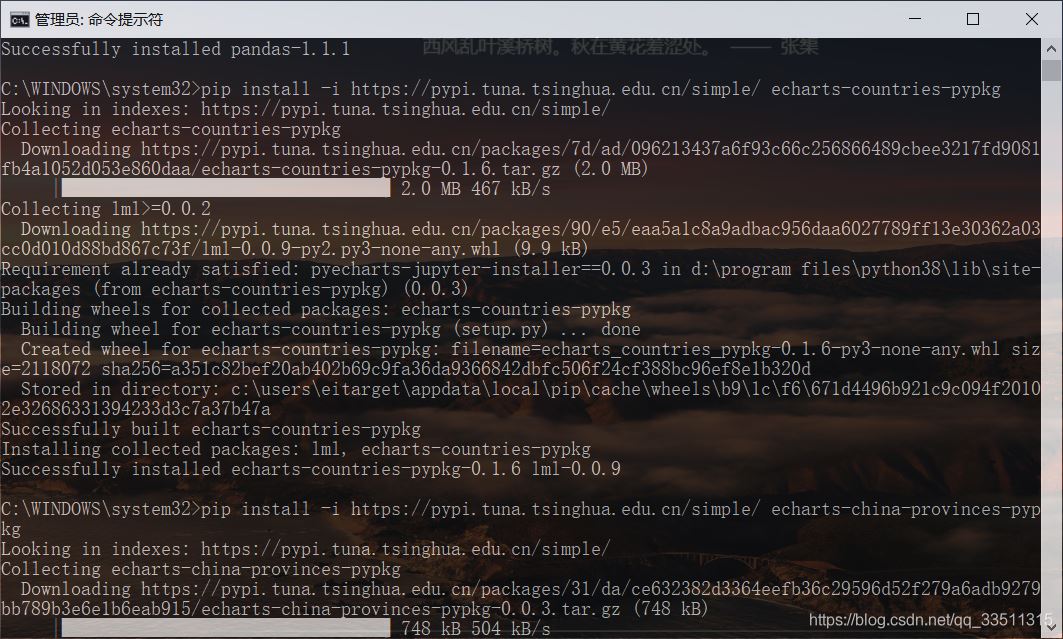 pyecharts介绍pyecharts是一个用于生成Echarts图表的类库。Echarts是百度开源的一个数据可视化JS库。用Echarts生成的图可视化效果非常棒为避免绘制缺漏,建议全部安装为了避免下载缓慢,作者全部使用镜像源下载过了pipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simple/echarts-countries-pypkgpipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simple/echarts-china-provinces-pypkgpipinstall-ihttps://pypi...
继续阅读 >
pyecharts介绍pyecharts是一个用于生成Echarts图表的类库。Echarts是百度开源的一个数据可视化JS库。用Echarts生成的图可视化效果非常棒为避免绘制缺漏,建议全部安装为了避免下载缓慢,作者全部使用镜像源下载过了pipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simple/echarts-countries-pypkgpipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simple/echarts-china-provinces-pypkgpipinstall-ihttps://pypi...
继续阅读 >
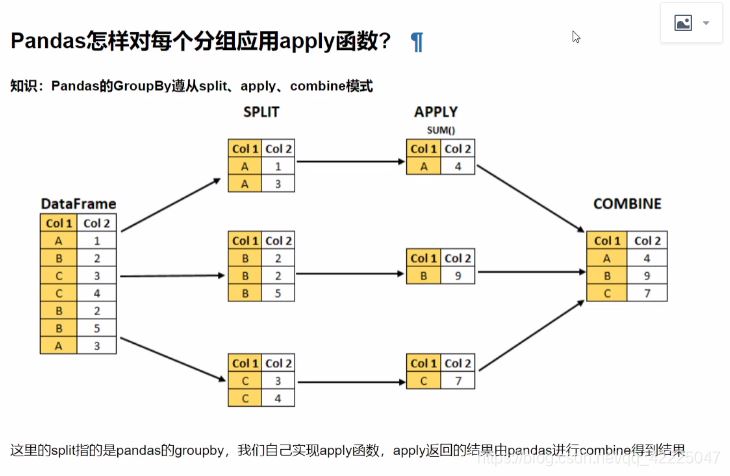 Pandas的apply函数概念(图解)实例1:怎样对数值按分组的归一化实例2:怎样取每个分组的TOPN数据到此这篇关于Pandas对每个分组应用apply函数的实现的文章就介绍到这了,更多相关Pandas应用apply函数内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!
Pandas的apply函数概念(图解)实例1:怎样对数值按分组的归一化实例2:怎样取每个分组的TOPN数据到此这篇关于Pandas对每个分组应用apply函数的实现的文章就介绍到这了,更多相关Pandas应用apply函数内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!
 Series对象和DataFrame的列数据提供了cat、dt、str三种属性接口(accessors),分别对应分类数据、日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷。今天翻阅pandas官方文档总结了以下几个常用的api。1.dt.date和dt.normalize(),他们都返回一个日期的日期部分,即只包含年月日。但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的。这里先简单创建一个datafram...
Series对象和DataFrame的列数据提供了cat、dt、str三种属性接口(accessors),分别对应分类数据、日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷。今天翻阅pandas官方文档总结了以下几个常用的api。1.dt.date和dt.normalize(),他们都返回一个日期的日期部分,即只包含年月日。但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的。这里先简单创建一个datafram...
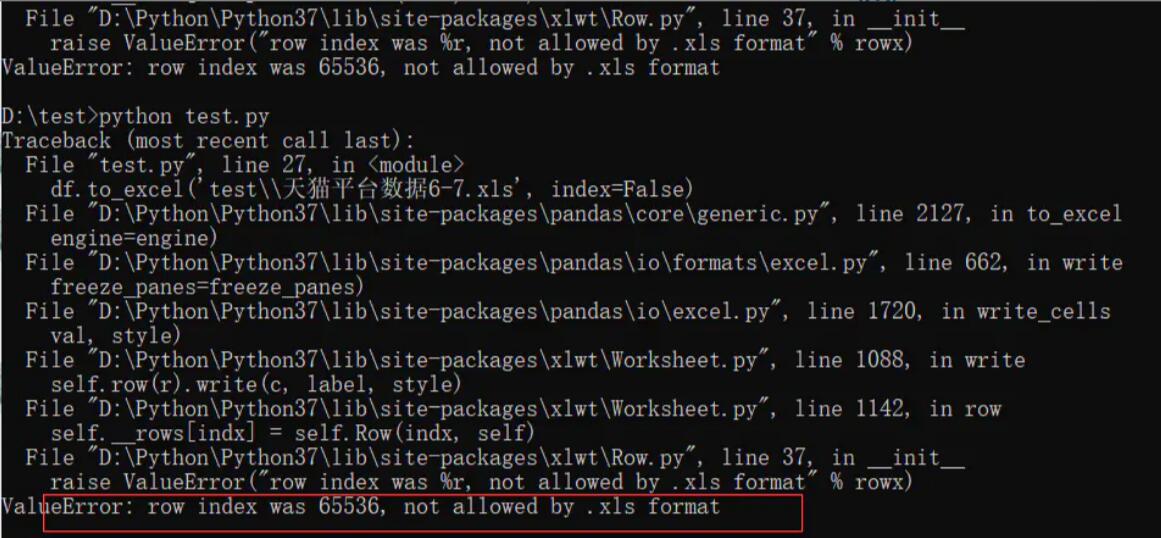 场景今天需要合并天猫订单数据,由于前期6.18活动有很多数据需要处理,将几个月份合并一起,结果报错。问题分析Excel文件的格式曾经发生过一次变化,在Excel2007以前,使用扩展名为.xls格式的文件,这种文件格式是一种特定的二进制格式,最多支持65,536行,256列表格。从Excel2007版开始,默认采用了基于XML的新的文件格式.xlsx,支持的表格行数达到了1,048,576,列数达到了16,384。需要注意的是,将.xlsx格式...
场景今天需要合并天猫订单数据,由于前期6.18活动有很多数据需要处理,将几个月份合并一起,结果报错。问题分析Excel文件的格式曾经发生过一次变化,在Excel2007以前,使用扩展名为.xls格式的文件,这种文件格式是一种特定的二进制格式,最多支持65,536行,256列表格。从Excel2007版开始,默认采用了基于XML的新的文件格式.xlsx,支持的表格行数达到了1,048,576,列数达到了16,384。需要注意的是,将.xlsx格式...
 1、介绍Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器。它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列2、创建DataFrame#-*-encoding=utf-8-*-importpandasif__name__=='__main__':passtest_stu=pandas.DataFrame({'高数':[66,77,88,99,85],'大物':[88,...
1、介绍Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器。它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列2、创建DataFrame#-*-encoding=utf-8-*-importpandasif__name__=='__main__':passtest_stu=pandas.DataFrame({'高数':[66,77,88,99,85],'大物':[88,...
 一、我的需求对于这样的一个csv表,需要将其(1)将营业部名称和日期和股票代码进行拼接(2)对于除了买入金额不同的的数据需要将它们的买入金额相加,每个买入金额乘以买卖序号的符号表示该营业名称对应的买入金额比如:xx公司,20190731,1,股票1,4000,C20201010,xxxx我这里想要的结果是:xx公司2019713C20201010,4000二、代码(1)首先由于文件是gbk,所以读取是需要注意encoding(2)日期是int类型,所以需要转化为字符...
一、我的需求对于这样的一个csv表,需要将其(1)将营业部名称和日期和股票代码进行拼接(2)对于除了买入金额不同的的数据需要将它们的买入金额相加,每个买入金额乘以买卖序号的符号表示该营业名称对应的买入金额比如:xx公司,20190731,1,股票1,4000,C20201010,xxxx我这里想要的结果是:xx公司2019713C20201010,4000二、代码(1)首先由于文件是gbk,所以读取是需要注意encoding(2)日期是int类型,所以需要转化为字符...
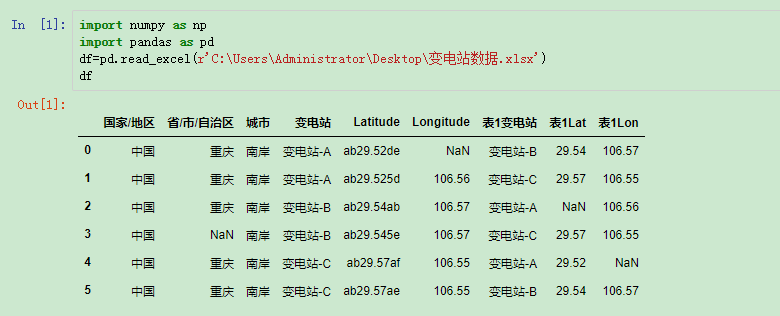 在处理数据的时候,很多时候会遇到批量替换的情况,如果一个一个去修改效率过低,也容易出错。replace()是很好的方法。源数据1、替换全部或者某一行replace的基本结构是:df.replace(to_replace,value)前面是需要替换的值,后面是替换后的值。例如我们要将南岸改为城区:将南岸改为城区这样Python就会搜索整个DataFrame并将文档中所有的南岸替换成了城区(要注意这样的操作并没有改变文档的源数据,要改变源数据需要使用inplace...
在处理数据的时候,很多时候会遇到批量替换的情况,如果一个一个去修改效率过低,也容易出错。replace()是很好的方法。源数据1、替换全部或者某一行replace的基本结构是:df.replace(to_replace,value)前面是需要替换的值,后面是替换后的值。例如我们要将南岸改为城区:将南岸改为城区这样Python就会搜索整个DataFrame并将文档中所有的南岸替换成了城区(要注意这样的操作并没有改变文档的源数据,要改变源数据需要使用inplace...
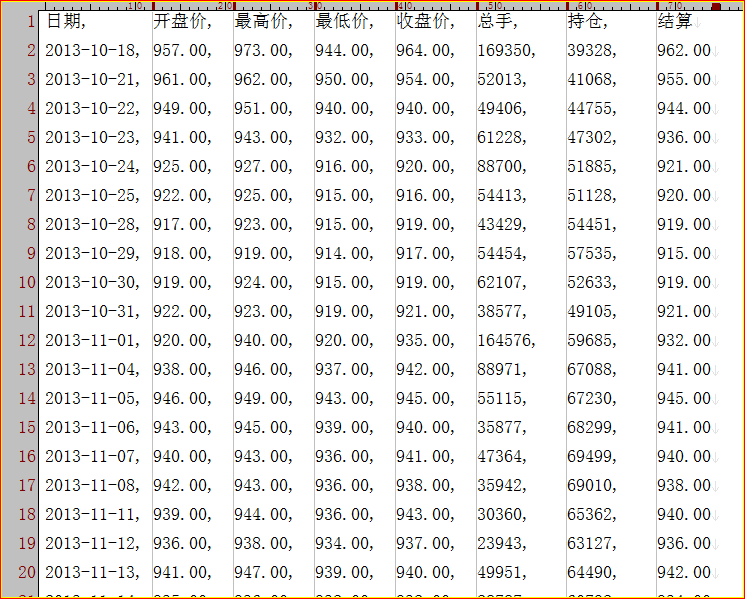 最近在研究螺纹钢与铁矿石的比价变化,所以用python写个代码分析一下。数据文件:数据下载自网络。代码:中间有些没用的,看官们请忽略,那是我从另一个文件直接复制来的,后面要plt出图的。今天的文章只讲两个DataFrame如何连接到一起,相当于SQL的left-join,或者updateAleftjoinBONkey1=key2。控制台输出:好了,数据已经按日期关联到一起,后面就简单了,准备用matplotlib画3条拆线,观察历史相关性。以上就是本文的全...
最近在研究螺纹钢与铁矿石的比价变化,所以用python写个代码分析一下。数据文件:数据下载自网络。代码:中间有些没用的,看官们请忽略,那是我从另一个文件直接复制来的,后面要plt出图的。今天的文章只讲两个DataFrame如何连接到一起,相当于SQL的left-join,或者updateAleftjoinBONkey1=key2。控制台输出:好了,数据已经按日期关联到一起,后面就简单了,准备用matplotlib画3条拆线,观察历史相关性。以上就是本文的全...
 前言在日常使用pandas的过程中,由于我们所分析的数据表规模、格式上的差异,使得同样的函数或方法作用在不同数据上的效果存在差异。而pandas有着自己的一套参数设置系统,可以帮助我们在遇到不同的数据时灵活调节从而达到最好的效果,本文就将介绍pandas中常用的参数设置方面的知识。图11设置DataFrame最大显示行数pandas设置参数中的display.max_rows用于控制打印出的数据框的最大显示行数,我们使用pd.set_option()来有针对的...
前言在日常使用pandas的过程中,由于我们所分析的数据表规模、格式上的差异,使得同样的函数或方法作用在不同数据上的效果存在差异。而pandas有着自己的一套参数设置系统,可以帮助我们在遇到不同的数据时灵活调节从而达到最好的效果,本文就将介绍pandas中常用的参数设置方面的知识。图11设置DataFrame最大显示行数pandas设置参数中的display.max_rows用于控制打印出的数据框的最大显示行数,我们使用pd.set_option()来有针对的...
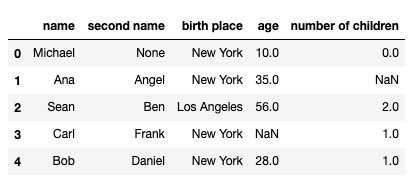 介绍在操作数据帧时,初学者有时甚至是更高级的数据科学家会对如何在pandas中使用inplace参数感到困惑。更有趣的是,我看到的解释这个概念的文章或教程并不多。它似乎被假定为知识或自我解释的概念。不幸的是,这对每个人来说都不是那么简单,因此本文试图解释什么是inplace参数以及如何正确使用它。让我们来看看一些使用inplace的函数的例子:fillna()dropna()sort_values()reset_index()sort_index()rename()我已经创...
介绍在操作数据帧时,初学者有时甚至是更高级的数据科学家会对如何在pandas中使用inplace参数感到困惑。更有趣的是,我看到的解释这个概念的文章或教程并不多。它似乎被假定为知识或自我解释的概念。不幸的是,这对每个人来说都不是那么简单,因此本文试图解释什么是inplace参数以及如何正确使用它。让我们来看看一些使用inplace的函数的例子:fillna()dropna()sort_values()reset_index()sort_index()rename()我已经创...
 Pandas最好用的函数Pandas是Python语言中非常好用的一种数据结构包,包含了许多有用的数据操作方法。而且很多算法相关的库函数的输入数据结构都要求是pandas数据,或者有该数据的接口。仔细看pandas的API说明文档,就会发现有好多有用的函数,比如非常常用的文件的读写函数就包括如下函数:FormatTypeDataDescriptionReaderWritertextCSVread_csvto_csv...
Pandas最好用的函数Pandas是Python语言中非常好用的一种数据结构包,包含了许多有用的数据操作方法。而且很多算法相关的库函数的输入数据结构都要求是pandas数据,或者有该数据的接口。仔细看pandas的API说明文档,就会发现有好多有用的函数,比如非常常用的文件的读写函数就包括如下函数:FormatTypeDataDescriptionReaderWritertextCSVread_csvto_csv...
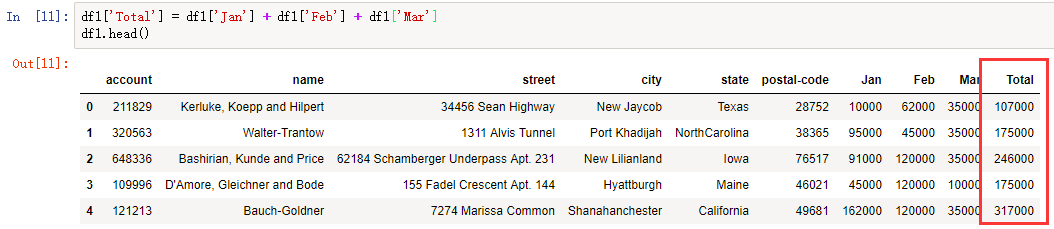 最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程。本篇介绍pandas的DataFrame对列(Column)的处理方法。示例数据请通过明哥的gitee进行下载。增加计算列pandas的DataFrame,每一行或每一列都是一个序列(Series)。比如:importpandasaspddf1=pd.read_excel('./excel-comp-data.xlsx');此时,用type(df1['city'],显示该数据列(column)的类型是...
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程。本篇介绍pandas的DataFrame对列(Column)的处理方法。示例数据请通过明哥的gitee进行下载。增加计算列pandas的DataFrame,每一行或每一列都是一个序列(Series)。比如:importpandasaspddf1=pd.read_excel('./excel-comp-data.xlsx');此时,用type(df1['city'],显示该数据列(column)的类型是...