
2021
07-26
07-26
pytorch lstm gru rnn 得到每个state输出的操作
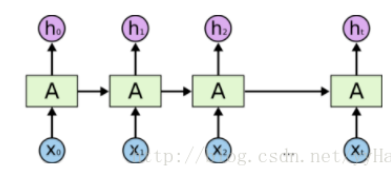 默认只返回最后一个state,所以一次输入一个step的input#coding=UTF-8importtorchimporttorch.autogradasautograd#torch中自动计算梯度模块importtorch.nnasnn#神经网络模块torch.manual_seed(1)#lstm单元输入和输出维度都是3lstm=nn.LSTM(input_size=3,hidden_size=3)#生成一个长度为5,每一个元素为1*3的序列作为输入,这里的数字3对应于上句中第一个3inputs=[autograd.Variable(torch.randn((1,3)))...
继续阅读 >
默认只返回最后一个state,所以一次输入一个step的input#coding=UTF-8importtorchimporttorch.autogradasautograd#torch中自动计算梯度模块importtorch.nnasnn#神经网络模块torch.manual_seed(1)#lstm单元输入和输出维度都是3lstm=nn.LSTM(input_size=3,hidden_size=3)#生成一个长度为5,每一个元素为1*3的序列作为输入,这里的数字3对应于上句中第一个3inputs=[autograd.Variable(torch.randn((1,3)))...
继续阅读 >
 pytorch中为什么要用zero_grad()将梯度清零调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度。optimizer.zero_grad()output=net(input)loss=loss_f(output,target)loss.backward()补充:Pytorch为什么每一...
pytorch中为什么要用zero_grad()将梯度清零调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度。optimizer.zero_grad()output=net(input)loss=loss_f(output,target)loss.backward()补充:Pytorch为什么每一...
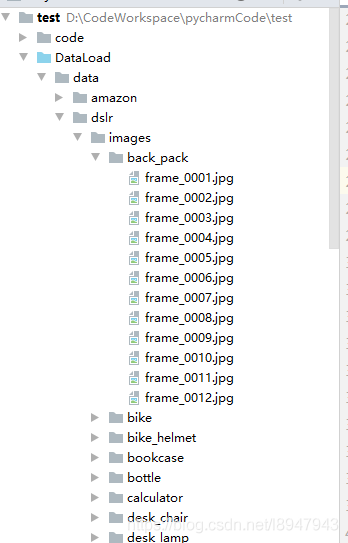 1、手上目前拥有数据集是一大坨,没有train,test,val的划分如图所示2、目录结构:|---data|---dslr|---images|---back_pack|---a.jpg|---b.jpg...3、转换后的格式如图目录结构为:|---datanews|---dslr|---images|---test|---train|---valid|---back_pack|---a.jpg|---b.j...
1、手上目前拥有数据集是一大坨,没有train,test,val的划分如图所示2、目录结构:|---data|---dslr|---images|---back_pack|---a.jpg|---b.jpg...3、转换后的格式如图目录结构为:|---datanews|---dslr|---images|---test|---train|---valid|---back_pack|---a.jpg|---b.j...
 问题最近用pytorch做实验时,遇到加载大量数据的问题。实验数据大小在400Gb,而本身机器的memory只有256Gb,显然无法将数据一次全部load到memory。解决方法首先自定义一个MyDataset继承torch.utils.data.Dataset,然后将MyDataset的对象feedintorch.utils.data.DataLoader()即可。MyDataset在__init__中声明一个文件对象,然后在__getitem__中缓慢读取数据,这样就不会一次把所有数据加载到内存中了。训练数据存放在train.txt中...
问题最近用pytorch做实验时,遇到加载大量数据的问题。实验数据大小在400Gb,而本身机器的memory只有256Gb,显然无法将数据一次全部load到memory。解决方法首先自定义一个MyDataset继承torch.utils.data.Dataset,然后将MyDataset的对象feedintorch.utils.data.DataLoader()即可。MyDataset在__init__中声明一个文件对象,然后在__getitem__中缓慢读取数据,这样就不会一次把所有数据加载到内存中了。训练数据存放在train.txt中...
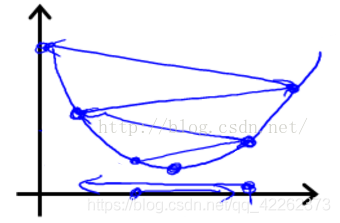 为了得到更好的网络,学习率通常是要调整的,即刚开始用较大的学习率来加快网络的训练,之后为了提高精确度,需要将学习率调低一点。如图所示,步长(学习率)太大容易跨过最优解。代码如下:表示每20个epoch学习率调整为之前的10%optimizer=optim.SGD(gan.parameters(),lr=0.1,momentum=0.9,weight_decay=0.0005)lr=...
为了得到更好的网络,学习率通常是要调整的,即刚开始用较大的学习率来加快网络的训练,之后为了提高精确度,需要将学习率调低一点。如图所示,步长(学习率)太大容易跨过最优解。代码如下:表示每20个epoch学习率调整为之前的10%optimizer=optim.SGD(gan.parameters(),lr=0.1,momentum=0.9,weight_decay=0.0005)lr=...
 看代码吧~如果两个dataloader的长度不一样,那就加个:fromitertoolsimportcycle仅使用zip,迭代器将在长度等于最小数据集的长度时耗尽。但是,使用cycle时,我们将再次重复最小的数据集,除非迭代器查看最大数据集中的所有样本。补充:pytorch技巧:自定义数据集torch.utils.data.DataLoader及Dataset的使用本博客中有可直接运行的例子,便于直观的理解,在torch环境中运行即可。1.数据传递机制在pytorch中数据传递按一...
看代码吧~如果两个dataloader的长度不一样,那就加个:fromitertoolsimportcycle仅使用zip,迭代器将在长度等于最小数据集的长度时耗尽。但是,使用cycle时,我们将再次重复最小的数据集,除非迭代器查看最大数据集中的所有样本。补充:pytorch技巧:自定义数据集torch.utils.data.DataLoader及Dataset的使用本博客中有可直接运行的例子,便于直观的理解,在torch环境中运行即可。1.数据传递机制在pytorch中数据传递按一...
 batch的lstm#导入相应的包importtorchimporttorch.nnasnnimporttorch.nn.functionalasFimporttorch.optimasoptimimporttorch.utils.dataasDatatorch.manual_seed(1)#准备数据的阶段defprepare_sequence(seq,to_ix):idxs=[to_ix[w]forwinseq]returntorch.tensor(idxs,dtype=torch.long)withopen("/home/lstm_train.txt",encoding='utf8')asf:train_data=[]word=[]label...
batch的lstm#导入相应的包importtorchimporttorch.nnasnnimporttorch.nn.functionalasFimporttorch.optimasoptimimporttorch.utils.dataasDatatorch.manual_seed(1)#准备数据的阶段defprepare_sequence(seq,to_ix):idxs=[to_ix[w]forwinseq]returntorch.tensor(idxs,dtype=torch.long)withopen("/home/lstm_train.txt",encoding='utf8')asf:train_data=[]word=[]label...
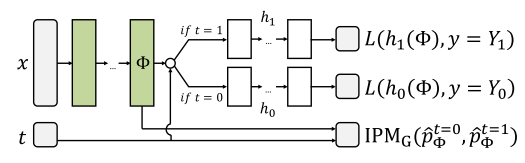 如何使用Pytorch实现two-head(多输出)模型1.two-head模型定义先放一张我要实现的模型结构图:如上图,就是一个two-head模型,也是一个但输入多输出模型。该模型的特点是输入一个x和一个t,h0和h1中只有一个会输出,所以可能这不算是一个典型的多输出模型。2.实现所遇到的困难一开始的想法:这不是很简单嘛,做一个判断不就完了,t=0时模型为前半段加h0,t=1时模型为前半段加h1。但实现的时候傻眼了,发现在真正前向传播的时候t...
如何使用Pytorch实现two-head(多输出)模型1.two-head模型定义先放一张我要实现的模型结构图:如上图,就是一个two-head模型,也是一个但输入多输出模型。该模型的特点是输入一个x和一个t,h0和h1中只有一个会输出,所以可能这不算是一个典型的多输出模型。2.实现所遇到的困难一开始的想法:这不是很简单嘛,做一个判断不就完了,t=0时模型为前半段加h0,t=1时模型为前半段加h1。但实现的时候傻眼了,发现在真正前向传播的时候t...