
2022
05-17
05-17
使用Atom支持基于Jupyter的Python开教程详解
 有关于使用Atom进行Python开发的网上资料比较少,最近发现使用Atom结合Hydrogen插件进行Python开发,尤其是数据挖掘相关的工作,整体体验要好于Vscode,Vscode虽然说也有连接Jupyter的工具,但是交互式的开发Hydrogen体验更好。这里放了个动图来展示一下Hydrogen的强大插件安装PythonHydrogenatom-ide-uiide-python 这里要注意,本地的pip需要安装python-language-server[all],在ide-python的readme中有详细说...
继续阅读 >
有关于使用Atom进行Python开发的网上资料比较少,最近发现使用Atom结合Hydrogen插件进行Python开发,尤其是数据挖掘相关的工作,整体体验要好于Vscode,Vscode虽然说也有连接Jupyter的工具,但是交互式的开发Hydrogen体验更好。这里放了个动图来展示一下Hydrogen的强大插件安装PythonHydrogenatom-ide-uiide-python 这里要注意,本地的pip需要安装python-language-server[all],在ide-python的readme中有详细说...
继续阅读 >
 2018年,Python仍然是数据科学领域解决重大任务和挑战的佼佼者。去年,我们发了一篇博文,列举了一些被证明是最有用的Python库。今年,我们扩充了原来的清单,并重新审视之前讨论过的库,重点关注在过去一年内出现的更新。我们对它们进行了分组,排序不分先后,因为真的说不清它们哪个更好。核心库与统计1.NumPy(提交:17911,贡献者:641)一般我们会将科学领域的库作为清单打头,NumPy是该领域的主要软件库之一...
2018年,Python仍然是数据科学领域解决重大任务和挑战的佼佼者。去年,我们发了一篇博文,列举了一些被证明是最有用的Python库。今年,我们扩充了原来的清单,并重新审视之前讨论过的库,重点关注在过去一年内出现的更新。我们对它们进行了分组,排序不分先后,因为真的说不清它们哪个更好。核心库与统计1.NumPy(提交:17911,贡献者:641)一般我们会将科学领域的库作为清单打头,NumPy是该领域的主要软件库之一...
 你的下一个Python项目需要一个模板引擎来自动生成HTML吗?这有几种选择。在我的日常工作中,我花费大量的时间将各种来源的数据转化为可读的信息。虽然很多时候这只是电子表格或某种类型的图表或其他数据可视化的形式,但也有其他时候,将数据以书面形式呈现是有意义的。但我的头疼地方就是复制和粘贴。如果你要将数据从源头移动到标准化模板,则不应该复制和粘贴。这很容易出错,说实话,这会浪费你的时间。...
你的下一个Python项目需要一个模板引擎来自动生成HTML吗?这有几种选择。在我的日常工作中,我花费大量的时间将各种来源的数据转化为可读的信息。虽然很多时候这只是电子表格或某种类型的图表或其他数据可视化的形式,但也有其他时候,将数据以书面形式呈现是有意义的。但我的头疼地方就是复制和粘贴。如果你要将数据从源头移动到标准化模板,则不应该复制和粘贴。这很容易出错,说实话,这会浪费你的时间。...
 面向对象的编程在实现想法乃至系统的过程中都非常重要,我们不论是使用TensorFlow还是PyTorch来构建模型都或多或少需要使用类和方法。而采用类的方法来构建模型会令代码非常具有可读性和条理性,本文介绍了算法实现中使用类和方法来构建模型所需要注意的设计原则,它们可以让我们的机器学习代码更加美丽迷人。大多数现代编程语言都支持并且鼓励面向对象编程(OOP)。即使我们最近似乎看到了一些偏离,因为人们开始使用...
面向对象的编程在实现想法乃至系统的过程中都非常重要,我们不论是使用TensorFlow还是PyTorch来构建模型都或多或少需要使用类和方法。而采用类的方法来构建模型会令代码非常具有可读性和条理性,本文介绍了算法实现中使用类和方法来构建模型所需要注意的设计原则,它们可以让我们的机器学习代码更加美丽迷人。大多数现代编程语言都支持并且鼓励面向对象编程(OOP)。即使我们最近似乎看到了一些偏离,因为人们开始使用...
 优化算法时间复杂度算法的时间复杂度对程序的执行效率影响最大,在Python中可以通过选择合适的数据结构来优化时间复杂度,如list和set查找某一个元素的时间复杂度分别是O(n)和O(1)。不同的场景有不同的优化方式,总得来说,一般有分治,分支界限,贪心,动态规划等思想。减少冗余数据如用上三角或下三角的方式去保存一个大的对称矩阵。在0元素占大多数的矩阵里使用稀疏矩阵表示。合理使用copy与de...
优化算法时间复杂度算法的时间复杂度对程序的执行效率影响最大,在Python中可以通过选择合适的数据结构来优化时间复杂度,如list和set查找某一个元素的时间复杂度分别是O(n)和O(1)。不同的场景有不同的优化方式,总得来说,一般有分治,分支界限,贪心,动态规划等思想。减少冗余数据如用上三角或下三角的方式去保存一个大的对称矩阵。在0元素占大多数的矩阵里使用稀疏矩阵表示。合理使用copy与de...
 人生苦短,我用Python,Python是非常棒的快速构建应用程序的编程语言。在这篇文章中我们将学习如何使用Python去构建一个RSS提示系统,目标是使用Fedora快乐地学习Python。如果你正在寻找一个完整的RSS提示应用程序,在Fedora中已经准备好了几个包。Fedora和Python——入门知识Python3.6在Fedora中是默认安装的,它包含了Python的很多标准库。标准库提供了一些可以让我们的任务更加简单完成...
人生苦短,我用Python,Python是非常棒的快速构建应用程序的编程语言。在这篇文章中我们将学习如何使用Python去构建一个RSS提示系统,目标是使用Fedora快乐地学习Python。如果你正在寻找一个完整的RSS提示应用程序,在Fedora中已经准备好了几个包。Fedora和Python——入门知识Python3.6在Fedora中是默认安装的,它包含了Python的很多标准库。标准库提供了一些可以让我们的任务更加简单完成...
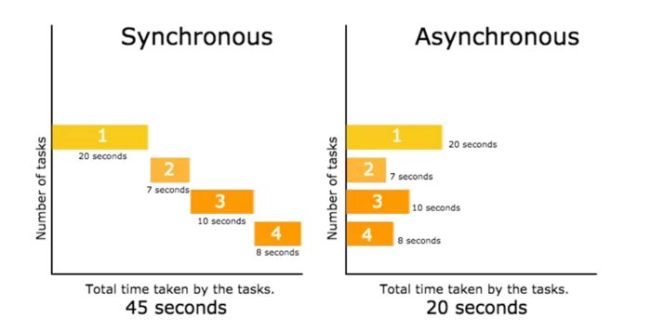 一、同步与异步#同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> &n...
一、同步与异步#同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> &n...
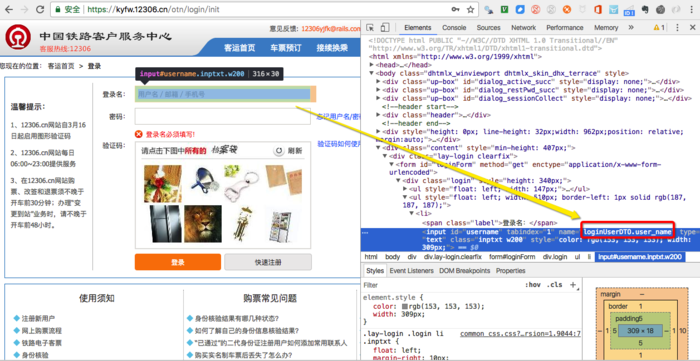 今年你不妨自己写一段代码来抢回家的火车票,是不是很Cool。先准备好:12306网站用户名和密码chrome浏览器及下载chromedriver下载Python代码,来自网络整理[点击下载]代码用的Python+Splinter开发,Splinter是一个使用Python开发的开源Web应用测试工具,它可以帮你实现自动浏览站点和与其进行交互。Splinter官网http://splinter.readthedocs.io/en/latest/。Splinter执行的时候会...
今年你不妨自己写一段代码来抢回家的火车票,是不是很Cool。先准备好:12306网站用户名和密码chrome浏览器及下载chromedriver下载Python代码,来自网络整理[点击下载]代码用的Python+Splinter开发,Splinter是一个使用Python开发的开源Web应用测试工具,它可以帮你实现自动浏览站点和与其进行交互。Splinter官网http://splinter.readthedocs.io/en/latest/。Splinter执行的时候会...
 本文主要介绍了数据结构中的八大排序算法,利用Python分别将他们进行实现。前言八大排序,三大查找是《数据结构》当中非常基础的知识点,在这里为了复习顺带总结了一下常见的八种排序算法。常见的八大排序算法,他们之间关系如下:排序算法他们的性能比较:性能比较下面,利用Python分别将他们进行实现。直接插入排序算法思想:直接插入排序直接插入排序的核心思想就...
本文主要介绍了数据结构中的八大排序算法,利用Python分别将他们进行实现。前言八大排序,三大查找是《数据结构》当中非常基础的知识点,在这里为了复习顺带总结了一下常见的八种排序算法。常见的八大排序算法,他们之间关系如下:排序算法他们的性能比较:性能比较下面,利用Python分别将他们进行实现。直接插入排序算法思想:直接插入排序直接插入排序的核心思想就...
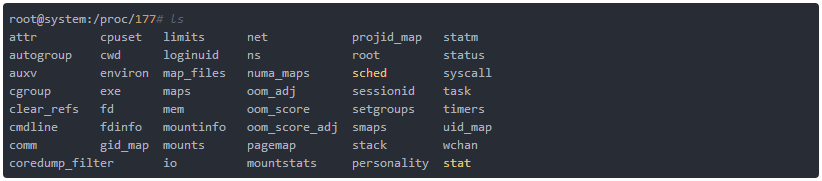 简介当你在机器上启动某个程序时,它只是在自己的“bubble”里面运行,这个气泡的作用就是用来将同一时刻运行的所有程序进行分离。这个“bubble”也可以称之为进程,包含了管理该程序调用所需要的一切。例如,这个所谓的进程环境包括该进程使用的内存页,处理该进程打开的文件,用户和组的访问权限,以及它的整个命令行调用,包括给定的参数。此信息保存在UNIX/Linux系统的流程文件系统中,该系统是一个虚拟文...
简介当你在机器上启动某个程序时,它只是在自己的“bubble”里面运行,这个气泡的作用就是用来将同一时刻运行的所有程序进行分离。这个“bubble”也可以称之为进程,包含了管理该程序调用所需要的一切。例如,这个所谓的进程环境包括该进程使用的内存页,处理该进程打开的文件,用户和组的访问权限,以及它的整个命令行调用,包括给定的参数。此信息保存在UNIX/Linux系统的流程文件系统中,该系统是一个虚拟文...