
2023
01-03
01-03
Python爬虫和反爬技术过程详解
 目录一、浏览器模拟(Headers)如何找到浏览器信息打开浏览器,按F12(或者鼠标右键+检查)点击如下图所示的Network按钮按键盘Ctrl+R(MAC:Command+R)进行抓包在Python中使用user-agent的方式如下:常用的请求头(模拟浏览器)信息如下:二、IP代理Python使用IP代理的方式如下:控制访问频率使用time模块即可:三、Cookies模拟手动获取cookie自动获取cookie使用cookies一、浏览器模拟(Headers)浏览器模拟是最常用的一种反爬方...
继续阅读 >
目录一、浏览器模拟(Headers)如何找到浏览器信息打开浏览器,按F12(或者鼠标右键+检查)点击如下图所示的Network按钮按键盘Ctrl+R(MAC:Command+R)进行抓包在Python中使用user-agent的方式如下:常用的请求头(模拟浏览器)信息如下:二、IP代理Python使用IP代理的方式如下:控制访问频率使用time模块即可:三、Cookies模拟手动获取cookie自动获取cookie使用cookies一、浏览器模拟(Headers)浏览器模拟是最常用的一种反爬方...
继续阅读 >
 目录爬虫为什么我们要使用爬虫爬虫准备工作爬虫项目讲解代码分析1.爬取网页2.逐一解析数据3.保存数据讲解我们的爬虫之前,先概述关于爬虫的简单概念(毕竟是零基础教程)爬虫网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。为什么我们要使用爬虫互联网大数据时代,给予我们的是生活...
目录爬虫为什么我们要使用爬虫爬虫准备工作爬虫项目讲解代码分析1.爬取网页2.逐一解析数据3.保存数据讲解我们的爬虫之前,先概述关于爬虫的简单概念(毕竟是零基础教程)爬虫网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。为什么我们要使用爬虫互联网大数据时代,给予我们的是生活...
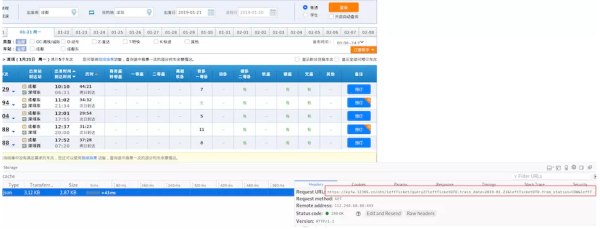 python实现12306余票查询我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包余票查询界面可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看[https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-21&leftTicketDTO.from_station=CDW&leftTicketDTO.to_station=SZQ&purpose_codes=ADULT](https://kyfw.12306.cn/otn/le...
python实现12306余票查询我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包余票查询界面可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看[https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-21&leftTicketDTO.from_station=CDW&leftTicketDTO.to_station=SZQ&purpose_codes=ADULT](https://kyfw.12306.cn/otn/le...
 一、问答平台这个「生活常识解答」机器人采用的是:阿里达摩院发布的语言模型PLUG(最近刚发布的,目前是测试阶段),地址链接如下:https://nlp.aliyun.com/portal#/BigText_chinese该模型参数规模达270亿,采用1TB以上高质量中文文本训练数据,包括了新闻、小说、诗歌、常识问答等类型。先来看一下原页面效果这里是需要登录阿里云账号,登录之后可以在网页进行测试问答!因此我们下面将通过抓包方式获取这个问答的请求链接,然后...
一、问答平台这个「生活常识解答」机器人采用的是:阿里达摩院发布的语言模型PLUG(最近刚发布的,目前是测试阶段),地址链接如下:https://nlp.aliyun.com/portal#/BigText_chinese该模型参数规模达270亿,采用1TB以上高质量中文文本训练数据,包括了新闻、小说、诗歌、常识问答等类型。先来看一下原页面效果这里是需要登录阿里云账号,登录之后可以在网页进行测试问答!因此我们下面将通过抓包方式获取这个问答的请求链接,然后...
 项目需求在专门供爬虫初学者训练爬虫技术的网站(http://quotes.toscrape.com)上爬取名言警句。创建项目在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:(base)λscrapystartprojectquotesNewscrapyproject'quotes',usingtemplatedirectory'd:\anaconda3\lib\site-packages\scrapy\temp1ates\project',createdin:D:\XXXYoucanstartyourfirstspiderwith:cd...
项目需求在专门供爬虫初学者训练爬虫技术的网站(http://quotes.toscrape.com)上爬取名言警句。创建项目在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:(base)λscrapystartprojectquotesNewscrapyproject'quotes',usingtemplatedirectory'd:\anaconda3\lib\site-packages\scrapy\temp1ates\project',createdin:D:\XXXYoucanstartyourfirstspiderwith:cd...
 前言本文结构如下:1、爬取某东畅销商品数据2、清洗数据并并进行简单分析3、将数据进行可视化展示数据的字段如下:一共爬取了243条某东畅销商品数据一、获取数据1.分析网页在编写代码之前,先来分析一波网页。上面是某东的畅销商品,通过辰哥分析分析,该网页有异步加载(前面10个商品是静态加载,剩下的是动态异步加载),因此我们需要写了个请求去获取数据。2.获取静态网页商品链接商品的销售、评论等数据在商品详情页,这里先...
前言本文结构如下:1、爬取某东畅销商品数据2、清洗数据并并进行简单分析3、将数据进行可视化展示数据的字段如下:一共爬取了243条某东畅销商品数据一、获取数据1.分析网页在编写代码之前,先来分析一波网页。上面是某东的畅销商品,通过辰哥分析分析,该网页有异步加载(前面10个商品是静态加载,剩下的是动态异步加载),因此我们需要写了个请求去获取数据。2.获取静态网页商品链接商品的销售、评论等数据在商品详情页,这里先...
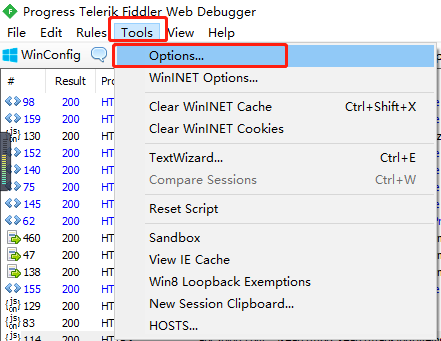 目录一、配置抓包工具二、配置手机代理三、抓取数据四、总结一、配置抓包工具1.安装软件本文选择的抓包工具:Fiddler 具体的下载安装这里不详细赘述!(网上搜Fiddler安装,一大堆教程),本文以实战为例,就不再这里浪费时间了!2.配置Fiddler安装好之后,接下来就开始配置Fiddler工具(这里是关键,仔细阅读!)配置Connections打开Fiddler后,点击Tools->Options点击Connections勾选上对应的选项配置HTTPS由于目前大...
目录一、配置抓包工具二、配置手机代理三、抓取数据四、总结一、配置抓包工具1.安装软件本文选择的抓包工具:Fiddler 具体的下载安装这里不详细赘述!(网上搜Fiddler安装,一大堆教程),本文以实战为例,就不再这里浪费时间了!2.配置Fiddler安装好之后,接下来就开始配置Fiddler工具(这里是关键,仔细阅读!)配置Connections打开Fiddler后,点击Tools->Options点击Connections勾选上对应的选项配置HTTPS由于目前大...
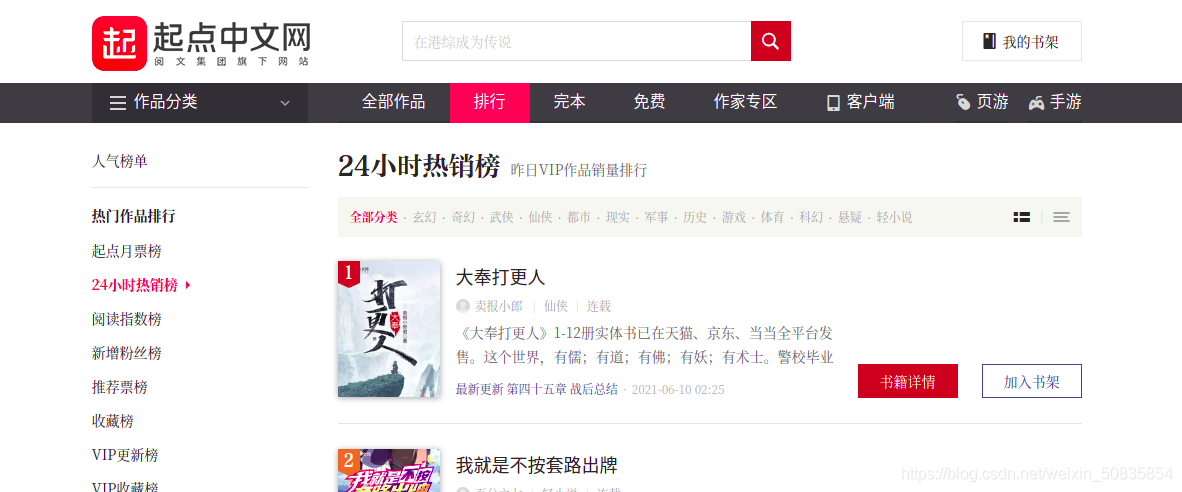 一、项目需求爬取排行榜小说的作者,书名,分类以及完结或连载二、项目分析目标url:“https://www.qidian.com/rank/hotsales?style=1&page=1”通过控制台搜索发现相应信息均存在于html静态网页中,所以此次爬虫难度较低。通过控制台观察发现,需要的内容都在一个个li列表中,每一个列表代表一本书的内容。在li中找到所需的内容找到第两页的url“https://www.qidian.com/rank/hotsales?style=1&page=1”“https://www.qidi...
一、项目需求爬取排行榜小说的作者,书名,分类以及完结或连载二、项目分析目标url:“https://www.qidian.com/rank/hotsales?style=1&page=1”通过控制台搜索发现相应信息均存在于html静态网页中,所以此次爬虫难度较低。通过控制台观察发现,需要的内容都在一个个li列表中,每一个列表代表一本书的内容。在li中找到所需的内容找到第两页的url“https://www.qidian.com/rank/hotsales?style=1&page=1”“https://www.qidi...
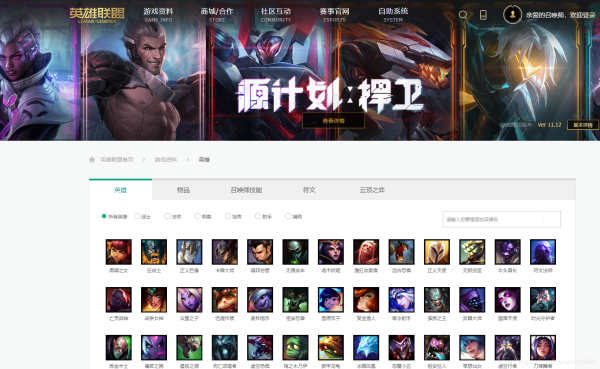 一、推理原理1.先去《英雄联盟》官网找到英雄及皮肤图片的网址:http://lol.qq.com/data/info-heros.shtml2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中。这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典——里面就包含了所有英雄的名字(英文)以及对应的编号。3.但是只有英雄的名字(英文)以及对应的编号并不...
一、推理原理1.先去《英雄联盟》官网找到英雄及皮肤图片的网址:http://lol.qq.com/data/info-heros.shtml2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中。这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典——里面就包含了所有英雄的名字(英文)以及对应的编号。3.但是只有英雄的名字(英文)以及对应的编号并不...
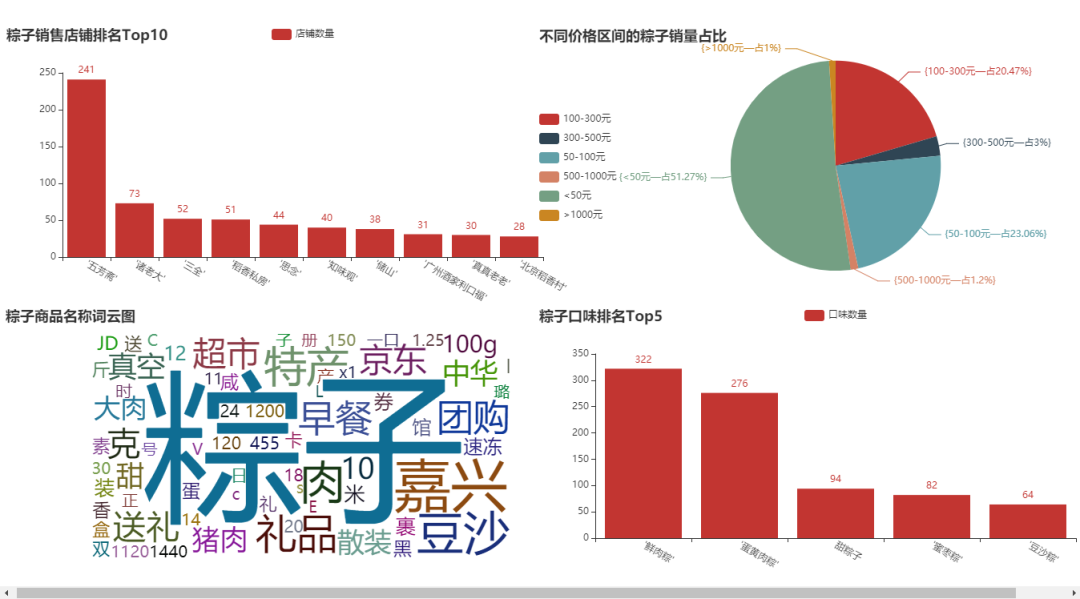 目录一、前言二、数据爬取三、数据清洗四、数据可视化一、前言本文就从数据爬取、数据清洗、数据可视化,这三个方面入手,但你简单完成一个小型的数据分析项目,让你对知识能够有一个综合的运用。整个思路如下:爬取网页:https://www.jd.com/爬取说明: 基于京东网站,我们搜索网站“粽子”数据,大概有100页。我们爬取的字段,既有一级页面的相关信息,还有二级页面的部分信息;爬取思路: 先针对某一页数...
目录一、前言二、数据爬取三、数据清洗四、数据可视化一、前言本文就从数据爬取、数据清洗、数据可视化,这三个方面入手,但你简单完成一个小型的数据分析项目,让你对知识能够有一个综合的运用。整个思路如下:爬取网页:https://www.jd.com/爬取说明: 基于京东网站,我们搜索网站“粽子”数据,大概有100页。我们爬取的字段,既有一级页面的相关信息,还有二级页面的部分信息;爬取思路: 先针对某一页数...
 目录一、抓取目标二、工具使用三、重点学习内容四、项目思路解析五、简易源码分享一、抓取目标目标网址:美拍视频二、工具使用开发环境:win10、python3.7开发工具:pycharm、Chrome工具包:requests、xpath、base64三、重点学习内容爬虫采集数据的解析过程js代码调试技巧js逆向解析代码Python代码的转换四、项目思路解析进入到网站的首页挑选你感兴趣的分类根据首页地址获取到进入详情页面的超链接的跳转地址找到对应加密的视频播...
目录一、抓取目标二、工具使用三、重点学习内容四、项目思路解析五、简易源码分享一、抓取目标目标网址:美拍视频二、工具使用开发环境:win10、python3.7开发工具:pycharm、Chrome工具包:requests、xpath、base64三、重点学习内容爬虫采集数据的解析过程js代码调试技巧js逆向解析代码Python代码的转换四、项目思路解析进入到网站的首页挑选你感兴趣的分类根据首页地址获取到进入详情页面的超链接的跳转地址找到对应加密的视频播...
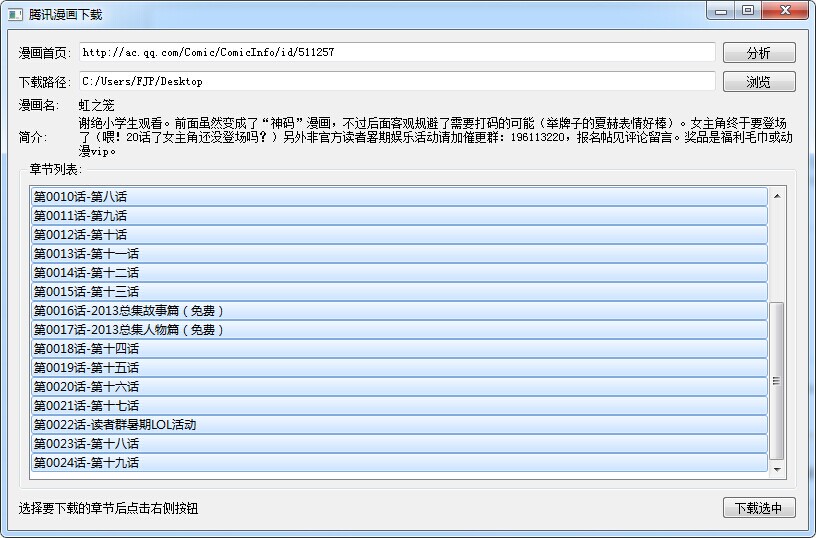 目录一、工具二、命令行帮助三、GUI预览效果四、全部源码五、下载源码一、工具python3第三方类库requestspython3-pyqt5(GUI依赖,不用GUI可不装)ubuntu系列系统使用以下命令安装依赖:URL格式:漫画首页的URL,如http://m.ac.qq.com/Comic/view/id/518333(移动版)或http://ac.qq.com/Comic/comicInfo/id/17114,http://ac.qq.com/naruto(PC版)注意:火影忍者彩漫需要访问m.ac.qq.com搜索火影忍者,因为PC端页面火影...
目录一、工具二、命令行帮助三、GUI预览效果四、全部源码五、下载源码一、工具python3第三方类库requestspython3-pyqt5(GUI依赖,不用GUI可不装)ubuntu系列系统使用以下命令安装依赖:URL格式:漫画首页的URL,如http://m.ac.qq.com/Comic/view/id/518333(移动版)或http://ac.qq.com/Comic/comicInfo/id/17114,http://ac.qq.com/naruto(PC版)注意:火影忍者彩漫需要访问m.ac.qq.com搜索火影忍者,因为PC端页面火影...
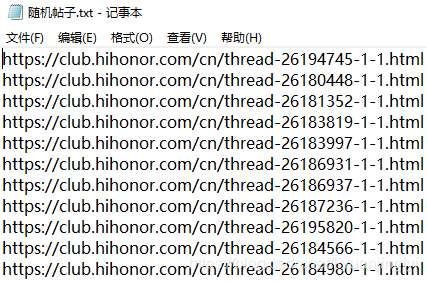 目录一、分析链接二、切分提取tid三、随机提取评论的内容四、盖楼刷抽奖一、分析链接上一篇文章指路一般来说,我们参加某个网站的盖楼抽奖活动,并不是仅仅只参加一个,而是多个盖楼活动一起参加。这个时候,我们就需要分析评论的链接是怎么区分不同帖子进行评论的,如上篇的刷帖链接,具体格式如下:https://club.hihonor.com/cn/forum.php?mod=post&action=reply&fid=154&tid=21089001&extra=page%3D1&replysubmit=yes&inflo...
目录一、分析链接二、切分提取tid三、随机提取评论的内容四、盖楼刷抽奖一、分析链接上一篇文章指路一般来说,我们参加某个网站的盖楼抽奖活动,并不是仅仅只参加一个,而是多个盖楼活动一起参加。这个时候,我们就需要分析评论的链接是怎么区分不同帖子进行评论的,如上篇的刷帖链接,具体格式如下:https://club.hihonor.com/cn/forum.php?mod=post&action=reply&fid=154&tid=21089001&extra=page%3D1&replysubmit=yes&inflo...