
2021
08-10
08-10
还在手动盖楼抽奖?教你用Python实现自动评论盖楼抽奖(一)
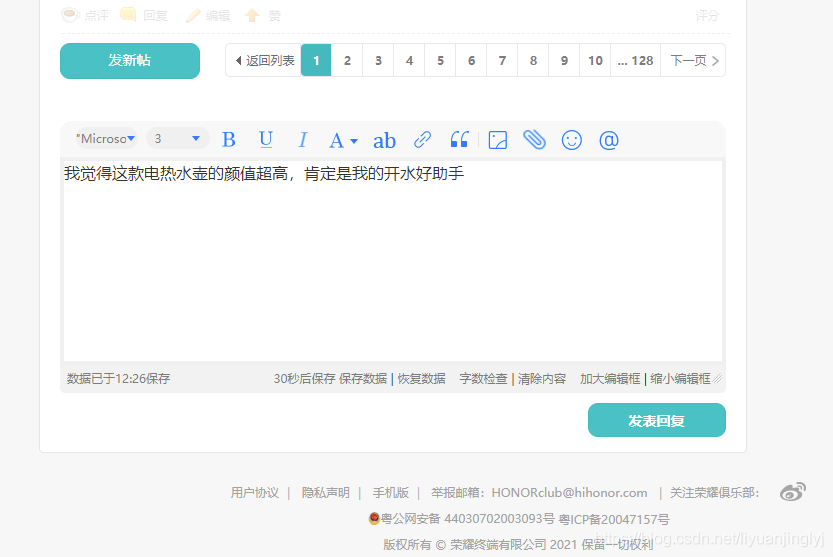 获取评论贴的请求头与表单数据下一篇在这里这里,我们随便选取一个网站,获取该贴评论后的请求头,表单数据以及评论贴链接。(因为涉及敏感信息,自己看图片是哪个网址)比如这个网站,经常有不定时的盖楼活动推出,我们随便评论一条,通过chromeF12功能,获取其请求头与表单数据。可以看到其右侧的表单数据(评论参数)有:message:盖楼的内容,一般来说这个内容可以提供一个文档随机选择评论,可以规避自动盖楼导致评论一模一...
继续阅读 >
获取评论贴的请求头与表单数据下一篇在这里这里,我们随便选取一个网站,获取该贴评论后的请求头,表单数据以及评论贴链接。(因为涉及敏感信息,自己看图片是哪个网址)比如这个网站,经常有不定时的盖楼活动推出,我们随便评论一条,通过chromeF12功能,获取其请求头与表单数据。可以看到其右侧的表单数据(评论参数)有:message:盖楼的内容,一般来说这个内容可以提供一个文档随机选择评论,可以规避自动盖楼导致评论一模一...
继续阅读 >
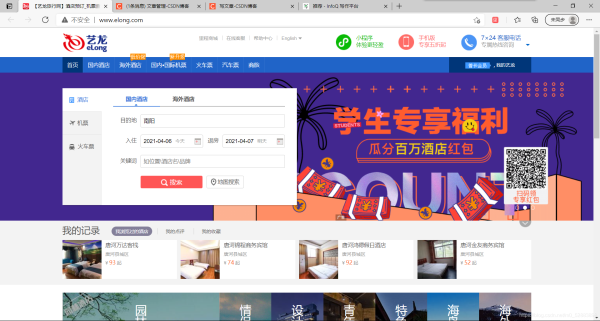 目录一、selenium实战二、打开艺龙网三、精确目标四、成功结语一、selenium实战这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的二、打开艺龙网可以直接点击这里进入:艺龙网这里是主页三、精确目标我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢?打开pycharm,新建一个叫做艺龙网的py文件,先导包:fromseleniumimportwebdriverim...
目录一、selenium实战二、打开艺龙网三、精确目标四、成功结语一、selenium实战这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的二、打开艺龙网可以直接点击这里进入:艺龙网这里是主页三、精确目标我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢?打开pycharm,新建一个叫做艺龙网的py文件,先导包:fromseleniumimportwebdriverim...
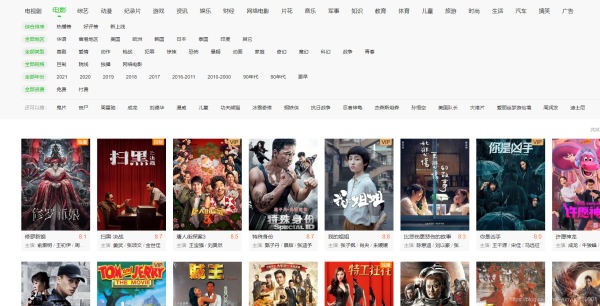 目录一、首先我们要找到目标二、F12查看网页源代码三、进行代码实现,获取想要资源。四、查看现象一、首先我们要找到目标找到目标先分析一下网页很幸运这个只有一个网页,不需要翻页。二、F12查看网页源代码找到目标,分析如何获取需要的数据。找到href与电影名称三、进行代码实现,获取想要资源。'''操作步骤1,获取到url内容2,css选择其选择内容3,保存自己需要数据'''#导入爬虫需要的包importrequestsfrombs4importBeaut...
目录一、首先我们要找到目标二、F12查看网页源代码三、进行代码实现,获取想要资源。四、查看现象一、首先我们要找到目标找到目标先分析一下网页很幸运这个只有一个网页,不需要翻页。二、F12查看网页源代码找到目标,分析如何获取需要的数据。找到href与电影名称三、进行代码实现,获取想要资源。'''操作步骤1,获取到url内容2,css选择其选择内容3,保存自己需要数据'''#导入爬虫需要的包importrequestsfrombs4importBeaut...
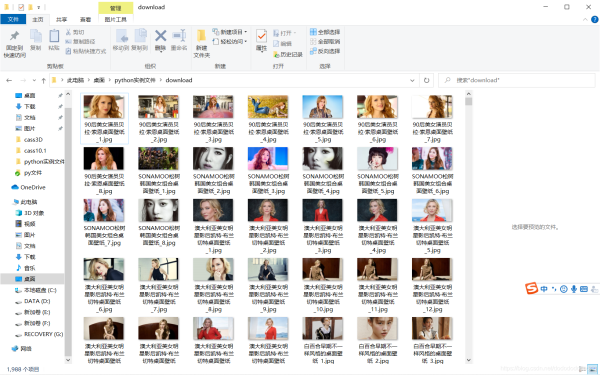 不得不说python真是一个神奇的东西,学三天就能爬网站真香完整代码#-*-coding:utf-8-*-"""CreatedonWedMay2617:53:132021@author:19088"""importurllib.requestimportosimportpickleimportreimportrandomimportsys#获取http代理classgetHttpAgents:#初始化函数def__init__(self):self.attArray=self.__loadAgentList()self.myagent=""#注意返回对象未进行解码defopenUr...
不得不说python真是一个神奇的东西,学三天就能爬网站真香完整代码#-*-coding:utf-8-*-"""CreatedonWedMay2617:53:132021@author:19088"""importurllib.requestimportosimportpickleimportreimportrandomimportsys#获取http代理classgetHttpAgents:#初始化函数def__init__(self):self.attArray=self.__loadAgentList()self.myagent=""#注意返回对象未进行解码defopenUr...
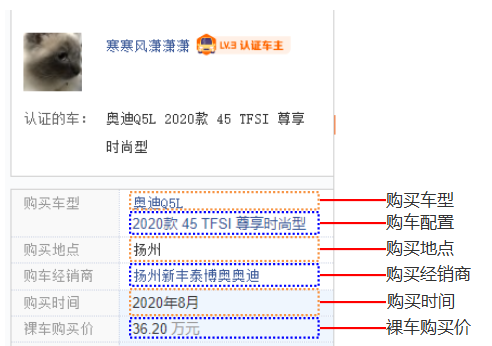 目录一、目标网页分析二、数据请求三、数据解析四、数据存储五、采集结果预览一、目标网页分析目标网站是某车之家关于品牌汽车车型的口碑模块相关数据,比如我们演示的案例奥迪Q5L的口碑页面如下:https://k.autohome.com.cn/4851/#pvareaid=3311678为了演示方式,大家可以直接打开上面这个网址,然后拖到全部口碑位置,找到我们本次采集需要的字段如下图所示:采集字段我们进行翻页发现,浏览器网址发生了变化,大家可以对下如下...
目录一、目标网页分析二、数据请求三、数据解析四、数据存储五、采集结果预览一、目标网页分析目标网站是某车之家关于品牌汽车车型的口碑模块相关数据,比如我们演示的案例奥迪Q5L的口碑页面如下:https://k.autohome.com.cn/4851/#pvareaid=3311678为了演示方式,大家可以直接打开上面这个网址,然后拖到全部口碑位置,找到我们本次采集需要的字段如下图所示:采集字段我们进行翻页发现,浏览器网址发生了变化,大家可以对下如下...
 目录一、技术路线二、获取网页信息三、网页爬取分析四、网页详情页链接获取五、依据图片链接保存图片六、main()函数七、完整代码一、技术路线requests:网页请求BeautifulSoup:解析html网页re:正则表达式,提取html网页信息os:保存文件importreimportrequestsimportosfrombs4importBeautifulSoup二、获取网页信息常规操作,获取网页信息的固定格式,返回的字符串格式的网页内容,其中headers参数可模拟人为的操作,‘欺骗...
目录一、技术路线二、获取网页信息三、网页爬取分析四、网页详情页链接获取五、依据图片链接保存图片六、main()函数七、完整代码一、技术路线requests:网页请求BeautifulSoup:解析html网页re:正则表达式,提取html网页信息os:保存文件importreimportrequestsimportosfrombs4importBeautifulSoup二、获取网页信息常规操作,获取网页信息的固定格式,返回的字符串格式的网页内容,其中headers参数可模拟人为的操作,‘欺骗...
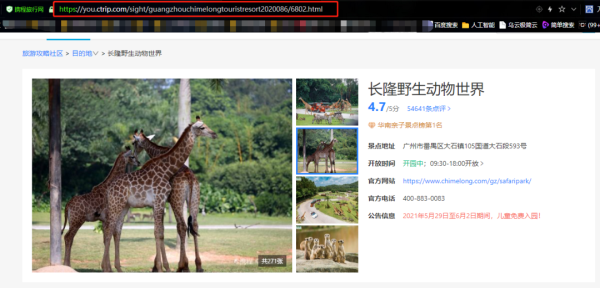 目录一、分析数据源二、分析数据包三、采集全部评论一、分析数据源这里的数据源是指html网页?还是Aajx异步。对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍。提示:以下操作均不需要登录(当然登录也可以)咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据。 页面下方则是评论数据 从上面两张图可以...
目录一、分析数据源二、分析数据包三、采集全部评论一、分析数据源这里的数据源是指html网页?还是Aajx异步。对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍。提示:以下操作均不需要登录(当然登录也可以)咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据。 页面下方则是评论数据 从上面两张图可以...
 目录一、基础第三方库使用二、爬虫的网页抓取三、动态网页和静态网页的区分四、动态网页和静态网页的抓取一、基础第三方库使用1.基本使用方法"""例"""fromurllibimportrequestresponse=request.urlopen(r'http://bbs.pinggu.org/')#返回状态200证明访问成功print("返回状态码:"+str(response.status))#读取页面信息转换文本并进行解码,如果本身是UTF-8就不要,具体看页面格式#搜索“charset”查看编码格式response.read...
目录一、基础第三方库使用二、爬虫的网页抓取三、动态网页和静态网页的区分四、动态网页和静态网页的抓取一、基础第三方库使用1.基本使用方法"""例"""fromurllibimportrequestresponse=request.urlopen(r'http://bbs.pinggu.org/')#返回状态200证明访问成功print("返回状态码:"+str(response.status))#读取页面信息转换文本并进行解码,如果本身是UTF-8就不要,具体看页面格式#搜索“charset”查看编码格式response.read...
 目录一、环境准备二、数据准备三、代码如下四、词云图效果展示一、环境准备安装相关第三方库pipinstalljiebapipinstallwordcloud二、数据准备爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息爬取对象路径:方式1、根据开发者工具(F12),获取请求url、请求头、cookie等信息;方式2:根据直播地址url,前+字符i我们这里演示的是,采用方式2。三、代码如下importrequests,reimportjieba,wordcloud"""#以下是练习代码def...
目录一、环境准备二、数据准备三、代码如下四、词云图效果展示一、环境准备安装相关第三方库pipinstalljiebapipinstallwordcloud二、数据准备爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息爬取对象路径:方式1、根据开发者工具(F12),获取请求url、请求头、cookie等信息;方式2:根据直播地址url,前+字符i我们这里演示的是,采用方式2。三、代码如下importrequests,reimportjieba,wordcloud"""#以下是练习代码def...
 目录一、系统环境二、爬取中国天气网三、爬取微博热搜四、微信自动发送消息五、源代码六、运行效果七、总结一、系统环境1.python3.8.22.webdriver(用于驱动edge)3.微信电脑版4.windows10二、爬取中国天气网因为中国天气网的网页是动态生成的,所以不能直接爬取到数据,需要先使用webdriver打开网页并渲染完成,然后保存网页源代码,使用beautifulsoup分析数据。爬取的数据包括实时温度、最高温度与最低温度、污染状况、风向和湿度...
目录一、系统环境二、爬取中国天气网三、爬取微博热搜四、微信自动发送消息五、源代码六、运行效果七、总结一、系统环境1.python3.8.22.webdriver(用于驱动edge)3.微信电脑版4.windows10二、爬取中国天气网因为中国天气网的网页是动态生成的,所以不能直接爬取到数据,需要先使用webdriver打开网页并渲染完成,然后保存网页源代码,使用beautifulsoup分析数据。爬取的数据包括实时温度、最高温度与最低温度、污染状况、风向和湿度...
 目录一、问题说明二、解决方法三、完整代码四、数据展示一、问题说明首先,运行下述代码,复现问题:#-*-coding:utf-8-*-importreimportrequestsfrombs4importBeautifulSoupcookie='PHPSESSID=aivms4ufg15sbrj0qgboo3c6gj;HMF_CI=4d8ff20092e9832daed8fe5eb0475663812603504e007aca93e6630c00b84dc207;_ga=GA1.2.556271139.1620784679;gr_user_id=4c878c8f-406b-46a0-86ee-a9baf2267477;_dx_uzZo5y=68b673b0aaec1f296c...
目录一、问题说明二、解决方法三、完整代码四、数据展示一、问题说明首先,运行下述代码,复现问题:#-*-coding:utf-8-*-importreimportrequestsfrombs4importBeautifulSoupcookie='PHPSESSID=aivms4ufg15sbrj0qgboo3c6gj;HMF_CI=4d8ff20092e9832daed8fe5eb0475663812603504e007aca93e6630c00b84dc207;_ga=GA1.2.556271139.1620784679;gr_user_id=4c878c8f-406b-46a0-86ee-a9baf2267477;_dx_uzZo5y=68b673b0aaec1f296c...
 目录一、安装selenium库二、下载一个浏览器的驱动程序(谷歌浏览器)三、智慧校园评教实现四、附录一、安装selenium库问题1:什么是selenium模块?基于浏览器自动化的一个模块。 问题2:selenium模块有什么作用呢?便捷地获取网站中动态加载的数据便捷地实现模拟登录问题3:环境安装pipinstallselenium二、下载一个浏览器的驱动程序(谷歌浏览器)1.下载路径http://chromedriver.storage.googleapis.com/index....
目录一、安装selenium库二、下载一个浏览器的驱动程序(谷歌浏览器)三、智慧校园评教实现四、附录一、安装selenium库问题1:什么是selenium模块?基于浏览器自动化的一个模块。 问题2:selenium模块有什么作用呢?便捷地获取网站中动态加载的数据便捷地实现模拟登录问题3:环境安装pipinstallselenium二、下载一个浏览器的驱动程序(谷歌浏览器)1.下载路径http://chromedriver.storage.googleapis.com/index....
 目录一、selenium简介二、selenium基本用法三、常用用法四、cookie的设置、获取与删除五、文件的上传与下载文件上传upload六、窗口的切换七、项目实战一、selenium简介官网总的来说:selenium库主要用来做浏览器的自动化脚本库。二、selenium基本用法fromseleniumimportwebdriverurl='http://www.baidu.com'#将webdriver实例化path='C:\ProgramFiles(x86)\Python38-32\chromedriver.exe'browser=webdriver.Chrome(ex...
目录一、selenium简介二、selenium基本用法三、常用用法四、cookie的设置、获取与删除五、文件的上传与下载文件上传upload六、窗口的切换七、项目实战一、selenium简介官网总的来说:selenium库主要用来做浏览器的自动化脚本库。二、selenium基本用法fromseleniumimportwebdriverurl='http://www.baidu.com'#将webdriver实例化path='C:\ProgramFiles(x86)\Python38-32\chromedriver.exe'browser=webdriver.Chrome(ex...
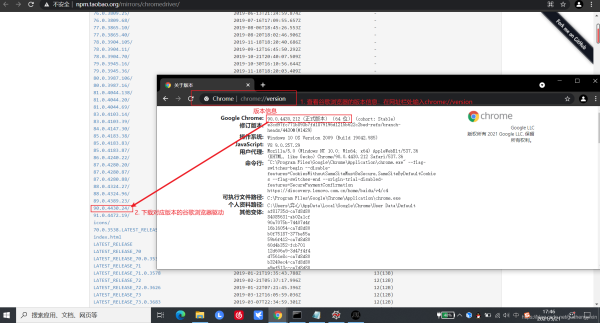 目录第一步:python中安装selenium库第二步:下载谷歌浏览器驱动并合理放置第三步:使用selenium爬取QQ音乐歌词(简单示例)第一步:python中安装selenium库和其他所有Python库一样,selenium库需要安装pipinstallselenium#Windows电脑安装seleniumpip3installselenium#Mac电脑安装selenium第二步:下载谷歌浏览器驱动并合理放置selenium的脚本可以控制所有常见浏览器,在使用之前需要安装浏览器端的驱动注意:驱动和浏览...
目录第一步:python中安装selenium库第二步:下载谷歌浏览器驱动并合理放置第三步:使用selenium爬取QQ音乐歌词(简单示例)第一步:python中安装selenium库和其他所有Python库一样,selenium库需要安装pipinstallselenium#Windows电脑安装seleniumpip3installselenium#Mac电脑安装selenium第二步:下载谷歌浏览器驱动并合理放置selenium的脚本可以控制所有常见浏览器,在使用之前需要安装浏览器端的驱动注意:驱动和浏览...
 目录一、请求目标(URL)二、网址的组成:三、请求体(response)四、请求方法(Method)五、常用的请求报头六、requests模块查看请求体一、请求目标(URL)URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法。类似于windows的文件路径。二、网址的组成:1.http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议。2.mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail。3.163...
目录一、请求目标(URL)二、网址的组成:三、请求体(response)四、请求方法(Method)五、常用的请求报头六、requests模块查看请求体一、请求目标(URL)URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法。类似于windows的文件路径。二、网址的组成:1.http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议。2.mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail。3.163...