
2021
07-01
07-01
Python爬虫基础之爬虫的分类知识总结
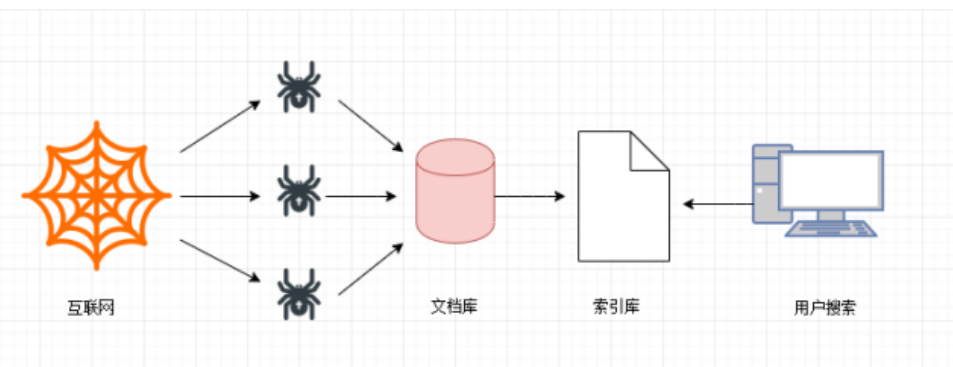 目录一、通用爬虫二、搜索引擎的局限性三、Robots协议四、请求与相应一、通用爬虫通用网络爬虫是搜索引擎抓取系统(Baidu、Google、Sogou等)的一个重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。为搜索引擎提供搜索支持。第一步搜索引擎去成千上万个网站抓取数据。第二步搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库(也就是文档库)。其中的页面数据与用户浏览器得到的HTML是完全...
继续阅读 >
目录一、通用爬虫二、搜索引擎的局限性三、Robots协议四、请求与相应一、通用爬虫通用网络爬虫是搜索引擎抓取系统(Baidu、Google、Sogou等)的一个重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。为搜索引擎提供搜索支持。第一步搜索引擎去成千上万个网站抓取数据。第二步搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库(也就是文档库)。其中的页面数据与用户浏览器得到的HTML是完全...
继续阅读 >
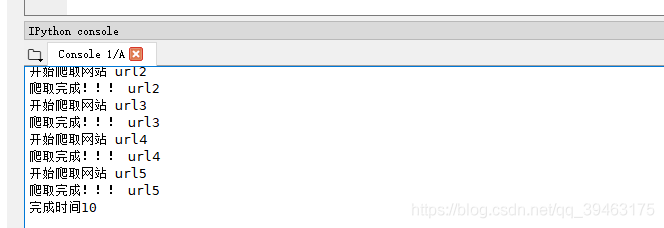 目录一、背景二、多线程实现三、协程实现四、多任务协程实现一、背景默认情况下,用get请求时,会出现阻塞,需要很多时间来等待,对于有很多请求url时,速度就很慢。因为需要一个url请求的完成,才能让下一个url继续访问。一种很自然的想法就是用异步机制来提高爬虫速度。通过构建线程池或者进程池完成异步爬虫,即使用多线程或者多进程来处理多个请求(在别的进程或者线程阻塞时)。importtime#串形defgetPage(url):print...
目录一、背景二、多线程实现三、协程实现四、多任务协程实现一、背景默认情况下,用get请求时,会出现阻塞,需要很多时间来等待,对于有很多请求url时,速度就很慢。因为需要一个url请求的完成,才能让下一个url继续访问。一种很自然的想法就是用异步机制来提高爬虫速度。通过构建线程池或者进程池完成异步爬虫,即使用多线程或者多进程来处理多个请求(在别的进程或者线程阻塞时)。importtime#串形defgetPage(url):print...
 目录一、前言二、同步代码演示三、异步,线程池代码四、同步爬虫爬取图片五、使用线程池的异步爬虫爬取4K美女图片一、前言学到现在,我们可以说已经学习了爬虫的基础知识,如果没有那些奇奇怪怪的反爬虫机制,基本上只要有时间分析,一般的数据都是可以爬取的,那么到了这个时候我们需要考虑的就是爬取的效率了,关于提高爬虫效率,也就是实现异步爬虫,我们可以考虑以下两种方式:一是线程池的使用(也就是实现单进程下的多线程)...
目录一、前言二、同步代码演示三、异步,线程池代码四、同步爬虫爬取图片五、使用线程池的异步爬虫爬取4K美女图片一、前言学到现在,我们可以说已经学习了爬虫的基础知识,如果没有那些奇奇怪怪的反爬虫机制,基本上只要有时间分析,一般的数据都是可以爬取的,那么到了这个时候我们需要考虑的就是爬取的效率了,关于提高爬虫效率,也就是实现异步爬虫,我们可以考虑以下两种方式:一是线程池的使用(也就是实现单进程下的多线程)...
 前言python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程。爬虫分为四个步骤:请求,解析数据,提取数据,存储数据。本文也会从这四个角度介绍基础爬虫的案例。一、简单静态网页的爬取我们要爬取的是一个壁纸网站的所有壁纸http://www.netbian.com/dongman/1.1选取爬虫策略——缩略图首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的i...
前言python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程。爬虫分为四个步骤:请求,解析数据,提取数据,存储数据。本文也会从这四个角度介绍基础爬虫的案例。一、简单静态网页的爬取我们要爬取的是一个壁纸网站的所有壁纸http://www.netbian.com/dongman/1.1选取爬虫策略——缩略图首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的i...
 前言说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是58同城。哎呦,我这暴脾气,想到就赶紧去干。但很显然,我失败了。说显然,而不是不幸,这是因为58同城是大公司,我这点本事爬不了数据是再正常不过的了。下面来看看58同城的反爬手段了。这是我爬取下来的网页源码。我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到58同城对自己的网...
前言说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是58同城。哎呦,我这暴脾气,想到就赶紧去干。但很显然,我失败了。说显然,而不是不幸,这是因为58同城是大公司,我这点本事爬不了数据是再正常不过的了。下面来看看58同城的反爬手段了。这是我爬取下来的网页源码。我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到58同城对自己的网...
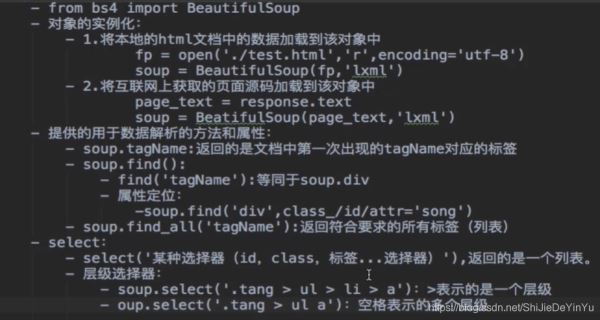 一、实现数据解析因为正则表达式本身有难度,所以在这里为大家介绍一下bs4实现数据解析。除此之外还有xpath解析。因为xpath不仅可以在python中使用,所以bs4和正则解析一样,仅仅是简单地写两个案例(爬取可翻页的图片,以及爬取三国演义)。以后的重点会在xpath上。二、安装库闲话少说,我们先来安装bs4相关的外来库。比较简单。1.首先打开cmd命令面板,依次安装bs4和lxml。2.命令分别是pipinstallbs4和...
一、实现数据解析因为正则表达式本身有难度,所以在这里为大家介绍一下bs4实现数据解析。除此之外还有xpath解析。因为xpath不仅可以在python中使用,所以bs4和正则解析一样,仅仅是简单地写两个案例(爬取可翻页的图片,以及爬取三国演义)。以后的重点会在xpath上。二、安装库闲话少说,我们先来安装bs4相关的外来库。比较简单。1.首先打开cmd命令面板,依次安装bs4和lxml。2.命令分别是pipinstallbs4和...
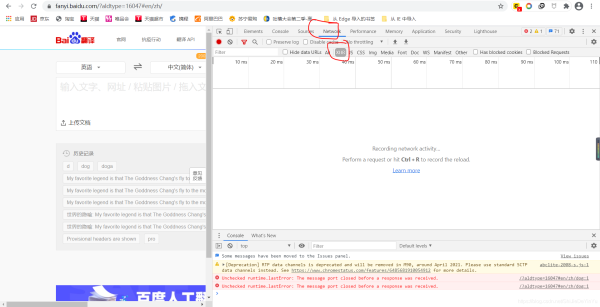 破解百度翻译翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢?爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的。百度做到这一点是用AJAX实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新。了解了这一点,那么我们要怎...
破解百度翻译翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢?爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的。百度做到这一点是用AJAX实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新。了解了这一点,那么我们要怎...
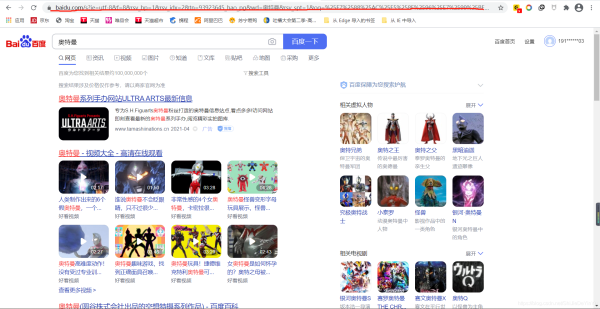 简易网页搜集器前面我们已经学会了简单爬取浏览器页面的爬虫。但事实上我们的需求当然不是爬取搜狗首页或是B站首页这么简单,再不济,我们都希望可以爬取某个特定的有信息的页面。不知道在学会了爬取之后,你有没有跟我一样试着去爬取一些搜索页面,比如说百度。像这样的页面注意我红笔划的部分,这是我打开的网页。现在我希望能爬取这一页的数据,按我们前面学的代码,应该是这样写的:importrequestsif__name__=="__main__":...
简易网页搜集器前面我们已经学会了简单爬取浏览器页面的爬虫。但事实上我们的需求当然不是爬取搜狗首页或是B站首页这么简单,再不济,我们都希望可以爬取某个特定的有信息的页面。不知道在学会了爬取之后,你有没有跟我一样试着去爬取一些搜索页面,比如说百度。像这样的页面注意我红笔划的部分,这是我打开的网页。现在我希望能爬取这一页的数据,按我们前面学的代码,应该是这样写的:importrequestsif__name__=="__main__":...
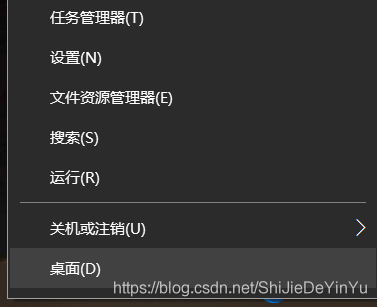 一、爬虫的流程开始学习爬虫,我们必须了解爬虫的流程框架。在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步:1.指定url,可以简单的理解为指定要爬取的网址2.发送请求。requests模块的请求一般为get和post3.将爬取的数据存储二、requests模块的导入因为requests模块属于外部库,所以需要我们自己导入库导入的步骤:1.右键Windows图标2.点击“运行”3.输入“cmd”打开命...
一、爬虫的流程开始学习爬虫,我们必须了解爬虫的流程框架。在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步:1.指定url,可以简单的理解为指定要爬取的网址2.发送请求。requests模块的请求一般为get和post3.将爬取的数据存储二、requests模块的导入因为requests模块属于外部库,所以需要我们自己导入库导入的步骤:1.右键Windows图标2.点击“运行”3.输入“cmd”打开命...
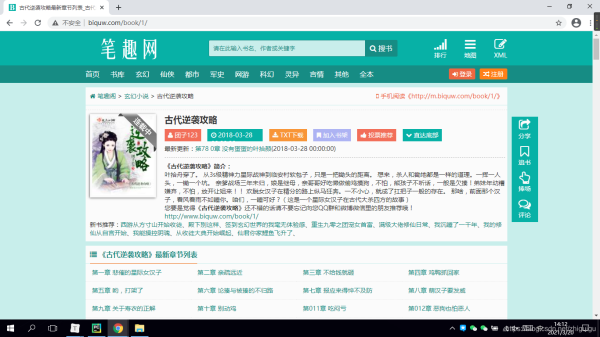 前言为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序。好吧,其实就是找个目的学习python,分享一下。一、首先导入相关的模块importosimportrequestsfrombs4importBeautifulSoup二、向网站发送请求并获取网站数据网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例。进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取#声明请求头headers={'User-...
前言为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序。好吧,其实就是找个目的学习python,分享一下。一、首先导入相关的模块importosimportrequestsfrombs4importBeautifulSoup二、向网站发送请求并获取网站数据网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例。进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取#声明请求头headers={'User-...
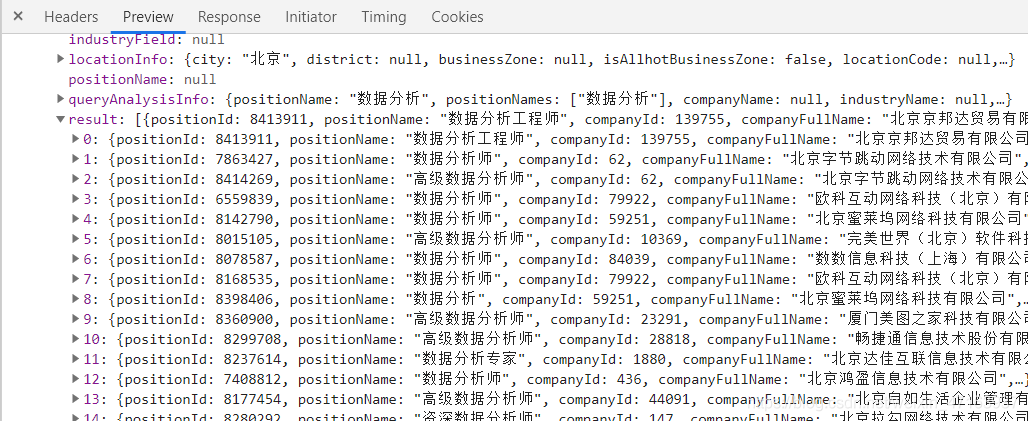 一、前言利用selenium+requests访问页面爬取拉勾网招聘信息二、分析url观察页面可知,页面数据属于动态加载所以现在我们通过抓包工具,获取数据包观察其url和参数url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false"参数:city=%E5%8C%97%E4%BA%AC==》城市first=true==》无用pn=1==》页数kd=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90==》商品关键词所以我们要想实现全站爬取,需...
一、前言利用selenium+requests访问页面爬取拉勾网招聘信息二、分析url观察页面可知,页面数据属于动态加载所以现在我们通过抓包工具,获取数据包观察其url和参数url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false"参数:city=%E5%8C%97%E4%BA%AC==》城市first=true==》无用pn=1==》页数kd=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90==》商品关键词所以我们要想实现全站爬取,需...
 一、基本开发环境Python3.6Pycharm二、相关模块的使用importosimportrequestsimporttimeimportreimportjsonfromdocximportDocumentfromdocx.sharedimportCm安装Python并添加到环境变量,pip安装需要的相关模块即可。三、目标网页分析网站的文档内容,都是以图片形式存在的。它有自己的数据接口接口链接:https://openapi.book118.com/getPreview.html?&project_id=1&aid=272112230&t=f2c66902d6b63726d8e08b557fef...
一、基本开发环境Python3.6Pycharm二、相关模块的使用importosimportrequestsimporttimeimportreimportjsonfromdocximportDocumentfromdocx.sharedimportCm安装Python并添加到环境变量,pip安装需要的相关模块即可。三、目标网页分析网站的文档内容,都是以图片形式存在的。它有自己的数据接口接口链接:https://openapi.book118.com/getPreview.html?&project_id=1&aid=272112230&t=f2c66902d6b63726d8e08b557fef...
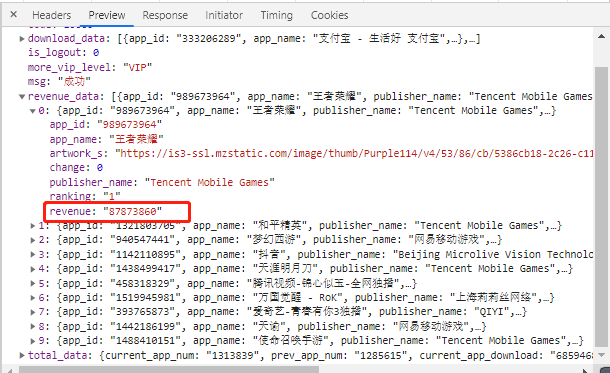 前言王者荣耀是最近几年包括现在一直都是最热销的手游,收益主要来源是游戏里面人物皮肤。今天就来爬取展示王者荣耀近一年收入流水线动图,看看王者荣耀有多赚钱(哈哈哈哈)主要可视化内容:一.App收入排行流水线1.1.获取数据数据来源于:七麦数据,里面数据都是通过异步加载,因此只需要找到异步链接,修改参数就可以直接获取到数据。备注:需要cookie才可以获取数据。请求链接https://api.qimai.cn/pred/appMonthPred?analy...
前言王者荣耀是最近几年包括现在一直都是最热销的手游,收益主要来源是游戏里面人物皮肤。今天就来爬取展示王者荣耀近一年收入流水线动图,看看王者荣耀有多赚钱(哈哈哈哈)主要可视化内容:一.App收入排行流水线1.1.获取数据数据来源于:七麦数据,里面数据都是通过异步加载,因此只需要找到异步链接,修改参数就可以直接获取到数据。备注:需要cookie才可以获取数据。请求链接https://api.qimai.cn/pred/appMonthPred?analy...
 一、项目介绍爬取网址:CSDN首页的Python、Java、前端、架构以及数据库栏目。简单分析其各自的URL不难发现,都是https://www.csdn.net/nav/+栏目名样式,这样我们就可以爬取不同栏目了。以Python目录页为例,如下图所示:爬取内容:每篇文章的博主信息,如博主姓名、码龄、原创数、访问量、粉丝数、获赞数、评论数、收藏数(考虑到周排名、总排名、积分都是根据上述信息综合得到的,对后续分析没实质性的作用,这里暂不爬取。)不...
一、项目介绍爬取网址:CSDN首页的Python、Java、前端、架构以及数据库栏目。简单分析其各自的URL不难发现,都是https://www.csdn.net/nav/+栏目名样式,这样我们就可以爬取不同栏目了。以Python目录页为例,如下图所示:爬取内容:每篇文章的博主信息,如博主姓名、码龄、原创数、访问量、粉丝数、获赞数、评论数、收藏数(考虑到周排名、总排名、积分都是根据上述信息综合得到的,对后续分析没实质性的作用,这里暂不爬取。)不...
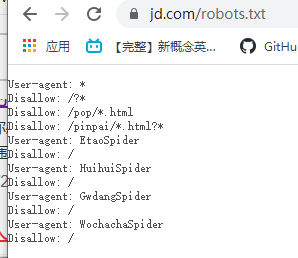 在学习Python爬虫部分,需要你已经学过Python基础和前端的相关知识。开发环境介绍: window10操作系统Python解释器3.8集成开发环境pycharm数据的来源及作用数据的来源有哪些?用户产生的数据:百度指数政府统计的数据:政府数据数据管理公司:聚合数据自己爬取的数据:爬取网站上的某些视频数据的作用数据分析智能产品的练习数据其他(比如买卖) 爬虫的相关概念 a)...
在学习Python爬虫部分,需要你已经学过Python基础和前端的相关知识。开发环境介绍: window10操作系统Python解释器3.8集成开发环境pycharm数据的来源及作用数据的来源有哪些?用户产生的数据:百度指数政府统计的数据:政府数据数据管理公司:聚合数据自己爬取的数据:爬取网站上的某些视频数据的作用数据分析智能产品的练习数据其他(比如买卖) 爬虫的相关概念 a)...