
2020
11-29
11-29
python爬虫分布式获取数据的实例方法
在我们进行卫生大扫除的时候,因为工作任务较多,所以我们会进行分工,每个人负责不同的打扫项目。同样分工合作的理念,在python分布式爬虫中也得到了应用。我们需要给不同的爬虫分配指令,让它们去分头行动获取同一个网站的数据。那么这些爬虫是怎么分工搜集数据的呢?感兴趣的小伙伴,我们可以通过下面的示例进行解惑。假设我有三台爬虫服务器A、B和C。我想让我所有的账号登录任务分散到三台服务器、让用户抓取在A和B上执行,让...
继续阅读 >
 我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情。周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题。那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧。1. 创建项目运行命令:scrapystartprojectmyfrist(your_project_name)文件说明:名称|作用--|--scrapy.cfg|...
我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情。周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题。那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧。1. 创建项目运行命令:scrapystartprojectmyfrist(your_project_name)文件说明:名称|作用--|--scrapy.cfg|...
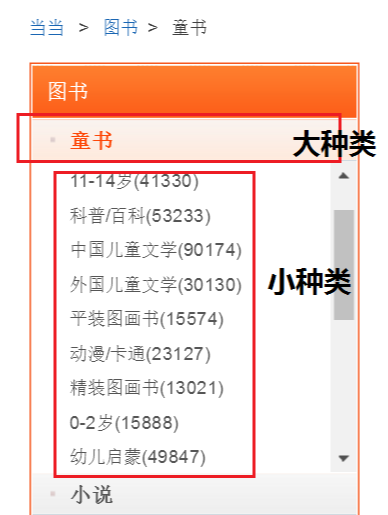 我们去图书馆的时候,会直接去自己喜欢的分类栏目找寻书籍。如果其中的分类不是很细致的话,想找某一本书还是有一些困难的。同样的如果我们获取了一些图书的数据,原始的文件里各种数据混杂在一起,非常不利于我们的查找和使用。所以今天小编教大家如何用python爬虫中scrapy给图书分类,大家一起学习下:spider抓取程序:在贴上代码之前,先对抓取的页面和链接做一个分析:网址:http://category.dangdang.com/pg4-cp01.25.17.00.0...
我们去图书馆的时候,会直接去自己喜欢的分类栏目找寻书籍。如果其中的分类不是很细致的话,想找某一本书还是有一些困难的。同样的如果我们获取了一些图书的数据,原始的文件里各种数据混杂在一起,非常不利于我们的查找和使用。所以今天小编教大家如何用python爬虫中scrapy给图书分类,大家一起学习下:spider抓取程序:在贴上代码之前,先对抓取的页面和链接做一个分析:网址:http://category.dangdang.com/pg4-cp01.25.17.00.0...
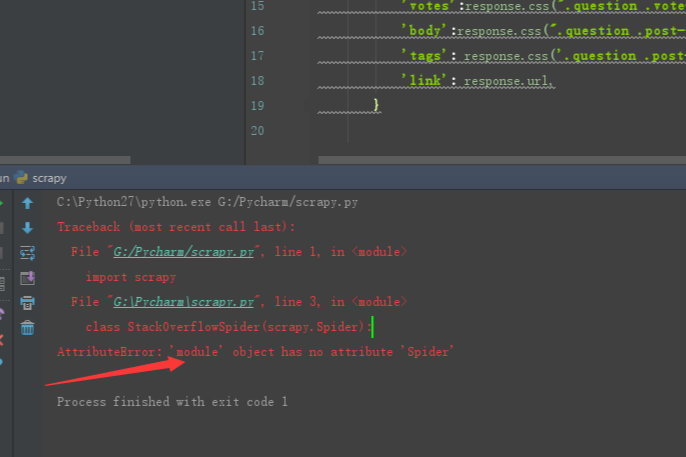 在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了。一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题。有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点。问题描述:安装位置:环境变量:解决办法:文件命名叫scrapy.py,明显和scrapy自己的包名冲突了,这里classStackOverFlowSpider(scrapy.Spider)会直接找当前文件(s...
在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了。一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题。有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点。问题描述:安装位置:环境变量:解决办法:文件命名叫scrapy.py,明显和scrapy自己的包名冲突了,这里classStackOverFlowSpider(scrapy.Spider)会直接找当前文件(s...
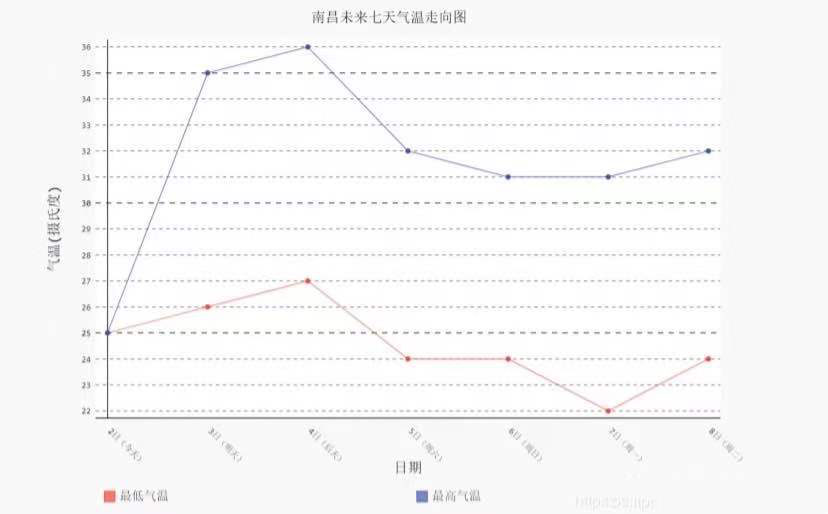 就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了。之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观。那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢?使用pygal绘图,使用该模块前需先安装pipinstallpygal,然后导入importpygalbar=pygal.Line()#创建折线图bar.add('最低气温',lows)#添加两...
就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了。之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观。那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢?使用pygal绘图,使用该模块前需先安装pipinstallpygal,然后导入importpygalbar=pygal.Line()#创建折线图bar.add('最低气温',lows)#添加两...
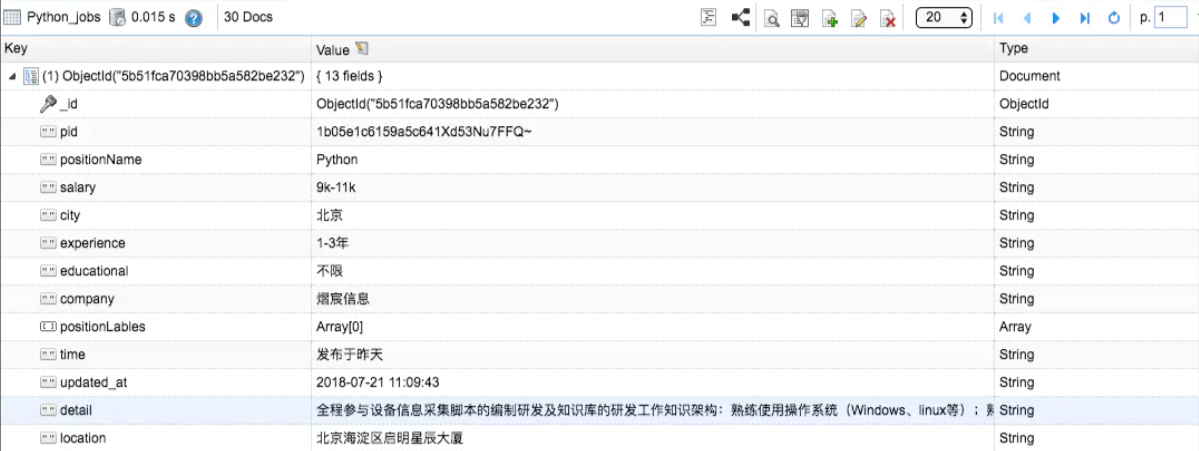 在我们人生的路途中,找工作是每个人都会经历的阶段,小编曾经也是苦苦求职大军中的一员。怀着对以后的规划和想象,我们在找工作的时候,会看一些招聘信息,然后从中挑选合适的岗位。不过招聘的岗位每个公司都有不少的需求,我们如何从中获取数据,来进行针对岗位方面的查找呢?大致流程如下:1.从代码中取出pid2.根据pid拼接网址=>得到detail_url,使用requests.get,防止爬虫挂掉,一旦发现爬取的detail重复,就重新启动爬虫3...
在我们人生的路途中,找工作是每个人都会经历的阶段,小编曾经也是苦苦求职大军中的一员。怀着对以后的规划和想象,我们在找工作的时候,会看一些招聘信息,然后从中挑选合适的岗位。不过招聘的岗位每个公司都有不少的需求,我们如何从中获取数据,来进行针对岗位方面的查找呢?大致流程如下:1.从代码中取出pid2.根据pid拼接网址=>得到detail_url,使用requests.get,防止爬虫挂掉,一旦发现爬取的detail重复,就重新启动爬虫3...
 PhantomJS作为常用获取页面的工具之一,我们已经讲过页面测试、代码评估和捕获屏幕这几种使用的方式。当然最厉害的还是网页方面的捕捉,这里就不再讲述了。今天我们要讲的是它加载页面的新方法,这个可能很多人不知道。其实经常会用到,感兴趣的小伙伴一起进入今天的学习之中吧~可以利用phantom来实现页面的加载,下面的例子实现了页面的加载并将页面保存为一张图片。varpage=require('webpage').create();page.open('http://...
PhantomJS作为常用获取页面的工具之一,我们已经讲过页面测试、代码评估和捕获屏幕这几种使用的方式。当然最厉害的还是网页方面的捕捉,这里就不再讲述了。今天我们要讲的是它加载页面的新方法,这个可能很多人不知道。其实经常会用到,感兴趣的小伙伴一起进入今天的学习之中吧~可以利用phantom来实现页面的加载,下面的例子实现了页面的加载并将页面保存为一张图片。varpage=require('webpage').create();page.open('http://...
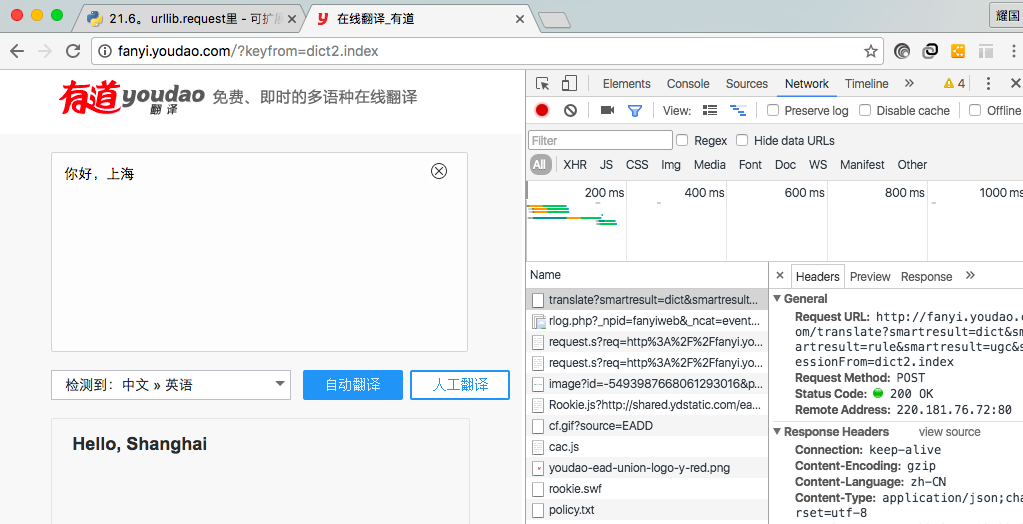
 一、分析网页网站的页面是JavaScript渲染而成的,我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的,因此这些数据并不存在于原始HTML代码中,而requests仅仅抓取的是原始HTML代码。抓取这种类型网站的页面数据,解决方案如下:分析Ajax,很多数据可能是经过Ajax请求时候获取的,所以可以分析其接口。在XHR里可以找到,RequestURL有几个关键参数,uuid和cityId是城市标识,offset偏移量可以控制...
一、分析网页网站的页面是JavaScript渲染而成的,我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的,因此这些数据并不存在于原始HTML代码中,而requests仅仅抓取的是原始HTML代码。抓取这种类型网站的页面数据,解决方案如下:分析Ajax,很多数据可能是经过Ajax请求时候获取的,所以可以分析其接口。在XHR里可以找到,RequestURL有几个关键参数,uuid和cityId是城市标识,offset偏移量可以控制...
 一、网络爬虫网络爬虫又被称为网络蜘蛛(🕷️),我们可以把互联网想象成一个蜘蛛网,每一个网站都是一个节点,我们可以使用一只蜘蛛去各个网页抓取我们想要的资源。举一个最简单的例子,你在百度和谷歌中输入‘Python',会有大量和Python相关的网页被检索出来,百度和谷歌是如何从海量的网页中检索出你想要的资源,他们靠的就是派出大量蜘蛛去网页上爬取,检索关键字,建立索引数据库,经过复杂的排序算法,结果按照...
一、网络爬虫网络爬虫又被称为网络蜘蛛(🕷️),我们可以把互联网想象成一个蜘蛛网,每一个网站都是一个节点,我们可以使用一只蜘蛛去各个网页抓取我们想要的资源。举一个最简单的例子,你在百度和谷歌中输入‘Python',会有大量和Python相关的网页被检索出来,百度和谷歌是如何从海量的网页中检索出你想要的资源,他们靠的就是派出大量蜘蛛去网页上爬取,检索关键字,建立索引数据库,经过复杂的排序算法,结果按照...
 lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高XPath,全称XMLPathLanguage,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可...
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高XPath,全称XMLPathLanguage,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可...