
2021
02-21
02-21
Python用requests库爬取返回为空的解决办法
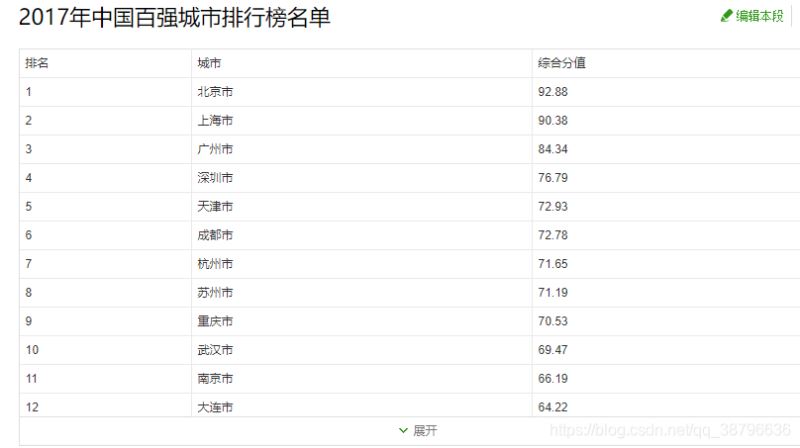 首先介?一下我??用360搜索派取城市排名前20。我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html我们要爬取的内容:html字段:robots协议:现在我们开始用pythonIDLE爬取importrequestsr=requests.get("https://baike.so.com/doc/24368318-25185095.html")r.status_coder.text结果分析,我们可以成功访问到该网页,但是得不到网页的结果。被360搜索识别,我们将headers修改。输出有个小插曲,网页内容很多,我...
继续阅读 >
首先介?一下我??用360搜索派取城市排名前20。我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html我们要爬取的内容:html字段:robots协议:现在我们开始用pythonIDLE爬取importrequestsr=requests.get("https://baike.so.com/doc/24368318-25185095.html")r.status_coder.text结果分析,我们可以成功访问到该网页,但是得不到网页的结果。被360搜索识别,我们将headers修改。输出有个小插曲,网页内容很多,我...
继续阅读 >