
2020
12-02
12-02
python爬虫请求头的使用
爬虫请求头网页获取:通过urlopen来进行获取requset.urlopen(url,data,timeout)第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间。第二三个参数是可以不传送的,data默认为空None,timeout默认为socket._GLOBAL_DEFAULT_TIMEOUT第一个参数URL是必须要加入的,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面fromurllib.requestimporturlopenurl="https://www...
继续阅读 >
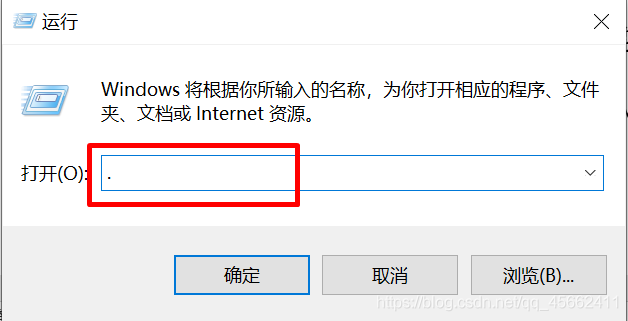 问:为何要更改pip镜像源?答:因为默认使用的镜像源是https://pypi.org/,国内访问的时候是其慢无比,特别是有时紧急安装库的时候;这时候我们就可以换成国内的镜像源网站,来提升下载的速度,以获得更好的编写代码体验具体操作流程:1、使用Win键(也就是键盘上那个Windows图标键)+R键打开运行窗口2、输入英文下的点(.)或者使用命令:%USERPROFILE%3、入到用户家目录后,点击鼠标右键新建一个名为pip的文件4、进入这个新建的...
问:为何要更改pip镜像源?答:因为默认使用的镜像源是https://pypi.org/,国内访问的时候是其慢无比,特别是有时紧急安装库的时候;这时候我们就可以换成国内的镜像源网站,来提升下载的速度,以获得更好的编写代码体验具体操作流程:1、使用Win键(也就是键盘上那个Windows图标键)+R键打开运行窗口2、输入英文下的点(.)或者使用命令:%USERPROFILE%3、入到用户家目录后,点击鼠标右键新建一个名为pip的文件4、进入这个新建的...
 python读取图像原图:importcv2#利用opencv读取图像importnumpyasnp#利用matplotlib显示图像importmatplotlib.pyplotaspltimg=cv2.imread("./lena.png")#读取图像#显示图像plt.imshow(img)plt.axis('off')plt.show()效果:问:为什么画出的图像和原图有色差呢?答:opencv的颜色通道顺序为[B,G,R],而matplotlib的颜色通道顺序为[R,G,B]。解决方案:把R和B的位置调换一下img=img[:,:,(2,1,0)]再次显示图像效果:(...
python读取图像原图:importcv2#利用opencv读取图像importnumpyasnp#利用matplotlib显示图像importmatplotlib.pyplotaspltimg=cv2.imread("./lena.png")#读取图像#显示图像plt.imshow(img)plt.axis('off')plt.show()效果:问:为什么画出的图像和原图有色差呢?答:opencv的颜色通道顺序为[B,G,R],而matplotlib的颜色通道顺序为[R,G,B]。解决方案:把R和B的位置调换一下img=img[:,:,(2,1,0)]再次显示图像效果:(...
 在找寻材料的时候,会看到一些暂时用不到但是内容不错的网页,就这样关闭未免浪费掉了,下次也不一定能再次搜索到。有些小伙伴会提出可以保存网页链接,但这种基本的做法并不能在网页打不开后还能看到内容。我们完全可以用爬虫获取这方面的数据,不过操作过程中会遇到一些阻拦,今天小编就教大家用sleep间隔进行python反爬虫,这样就可以得到我们想到的数据啦。步骤要利用headers拉动请求,模拟成浏览器去访问网站,跳过最简单的反...
在找寻材料的时候,会看到一些暂时用不到但是内容不错的网页,就这样关闭未免浪费掉了,下次也不一定能再次搜索到。有些小伙伴会提出可以保存网页链接,但这种基本的做法并不能在网页打不开后还能看到内容。我们完全可以用爬虫获取这方面的数据,不过操作过程中会遇到一些阻拦,今天小编就教大家用sleep间隔进行python反爬虫,这样就可以得到我们想到的数据啦。步骤要利用headers拉动请求,模拟成浏览器去访问网站,跳过最简单的反...
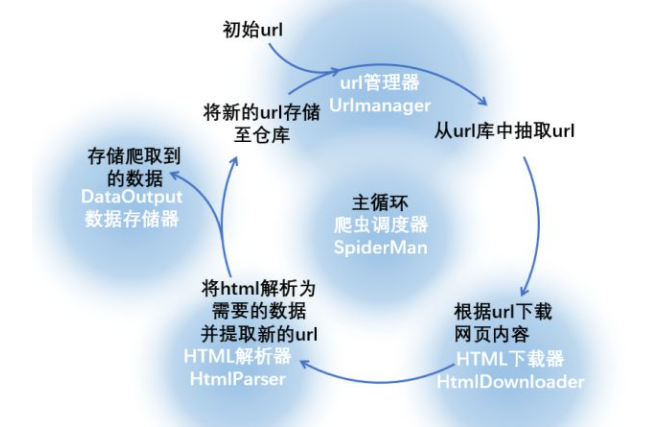 我们一般使用爬虫看到的都是最后的数据结果,对于整个的获取过程没有过多了解过。对于初学python的小伙伴们来说,不光是代码的练习,还是原理的分析都是必不可少的。小编把整个爬取的过程分为了几个部分,从一开始的下载,到数据的去重解析,再到整个爬虫循环的结束,以图片和代码的双重形式展现给大家,希望能够对爬虫调度器有一个深刻的理解。我们可以编写几个元件,每个元件完成一项功能,下图中的蓝底白字就是对这一流程的抽象...
我们一般使用爬虫看到的都是最后的数据结果,对于整个的获取过程没有过多了解过。对于初学python的小伙伴们来说,不光是代码的练习,还是原理的分析都是必不可少的。小编把整个爬取的过程分为了几个部分,从一开始的下载,到数据的去重解析,再到整个爬虫循环的结束,以图片和代码的双重形式展现给大家,希望能够对爬虫调度器有一个深刻的理解。我们可以编写几个元件,每个元件完成一项功能,下图中的蓝底白字就是对这一流程的抽象...
 本文总结分享介绍接口测试框架开发,环境使用python3+selenium3+unittest+ddt+requests测试框架及ddt数据驱动,采用Excel管理测试用例等集成测试数据功能,以及使用HTMLTestRunner来生成测试报告,目前有开源的poman、Jmeter等接口测试工具,为什么还要开发接口测试框架呢?因接口测试工具也有存在几点不足。测试数据不可控制。比如接口返回数据不可控,就无法自动断言接口返回的数据,不能断定是接口程序引起,还是测试数据变化...
本文总结分享介绍接口测试框架开发,环境使用python3+selenium3+unittest+ddt+requests测试框架及ddt数据驱动,采用Excel管理测试用例等集成测试数据功能,以及使用HTMLTestRunner来生成测试报告,目前有开源的poman、Jmeter等接口测试工具,为什么还要开发接口测试框架呢?因接口测试工具也有存在几点不足。测试数据不可控制。比如接口返回数据不可控,就无法自动断言接口返回的数据,不能断定是接口程序引起,还是测试数据变化...